DDG search drop in powered by ddg.patdryburgh.com
tl/dr; an update (sudo pacman -Syu) to a server I manage running Arch messed up the boot process of my server, due to interaction between RAID and GRUB, and I stumbled my way through debugging it.
WARNING If you find yourself with this problem, make sure to read all the way to the end, because I take some steps that I think made things worse half way through (in particular running grub-install and in-effect wiping out boot)
We’re taking a detour from our regularly scheduled programming on observability inside Kubernetes environments to dive into an issue I ran into last night/this morning – After doing some work getting an app running in the cluster I updated and restarted the server since I hadn’t in a while and it didn’t boot. That’s bascially a nightmare scenario every time it happens – and while it doesn’t happen to often, I panicked quite a bit.
Some background – I purchased the machine I currently manage from the Hetzner Robot Market, which I really like and appreciate. I used to exclusively use VPSes but then upon realizing how amazing dedicated hosting could be I haven’t looked back (though I do still run some older things on a INIZ KVM VPS I still keep).
Very recently I switched from running CoreOS to Arch Linux on the server because I ran into some problems installing some stuff and CoreOS wasn’t behaving reliably. I haven’t written about it yet, but I will – it’s embedded in a long series about installing Rook (automated [CephFS]]ceph] for Kubernetes), so it might be a while till I get to it.
Well enough with the background, what happened yesterday was that after making some updates to the cluster, I finally got an app I’m working on in a good running state, so I figured I should update and restart the box (all my SystemD configuration is inplace so a fresh restart should change nothing, all the requisite services should come up automatically at start). Upon trying to SSH into the box after restarting, I found that I couldn’t SSH, the sites that were hosted were unreachable, kubernetes was unreachable, and an nmap revealed no ports to be open on the box.
After heading to the Heztner-provided console, it said the machine was indeed up (green at least), so the machine was running, but for some reason I couldn’t access it. What follows is the story of my debugging and prodding the system to figure out what happen. Technically the downtime ended up being close to 12+ hours (I went to sleep since nothing mission critical is being hosted on the server), which would probably be absolutely unacceptable in a production environment. Hetzner offers some pretty good [rescue system facilities][hetzner-recovery] (they actually are probably fairly industry standard for dedicated servers, but I’m impressed nonetheless), so I had some tools to debug with.
At this point in my linux sysadmin life, the first thing I like to look for after a failure is the logs (if there are any). As I’ve done plenty of stuff wrong, I basically just expect every issue to be user-error that’s been printed to a log somewhere for me to find later and yell a hardy “d’oh”.
There’s obviously a problem somewhere in the boot process, so after finding a random SO post on where boot-related logs might go (I probably should know this by now), I checked the area and they were….. Empty :( (/var/log/syslog, /var/log/dmesg).
The thing with kernel boot problems is that since the kernel can’t necessarily write to a file system for much of the process, it’s perfectly reasonable for those files to be empty, if you fail before the kernel gets to that part of setup.
After hitting a bit of a dead-end with trying to peruse the systme logs (I didn’t try that hard), my next thought was that maybe the issue was the firewall. One thing I remembered I had changed were some ufw settings before the update & reboot – though the commands I ran were pretty standard, maybe it was possible that I had messed up the configuration somehow and it just didn’t load (or loaded bad configuration closing all the ports)?
I loaded up the rescue system and tried to look around on the filesystem for any clues (/etc/systemd/system, iptables doesn’t even really seem to have settings anywhere), but had no luck. I also started looking into if there was a way to have SystemD ensure a unit was started @ startup (or disable one, incase UFW was preventing connections) or something like that, but there kind of isn’t a thing you can do from outside the system (as in without access to systemctl).
[EDIT] - Thanks to reddit user u/dafta007 for pointing out that IP table’s config files are available @ /etc/iptables/iptables.rules.
At this point it dawned on me that I just didn’t know how to figure this problem out without seeing the screen of the machine in question, and to see how far it got during boot/what was happening on it. It was up, yet wasn’t taking any connections – sure the screen had something on it that would help me figure out the issue.
Having to make non-educated guesses at a problem is usually a bad sign, and in this case, I found that my second guess (the firewall issue) was thoroughly wrong:
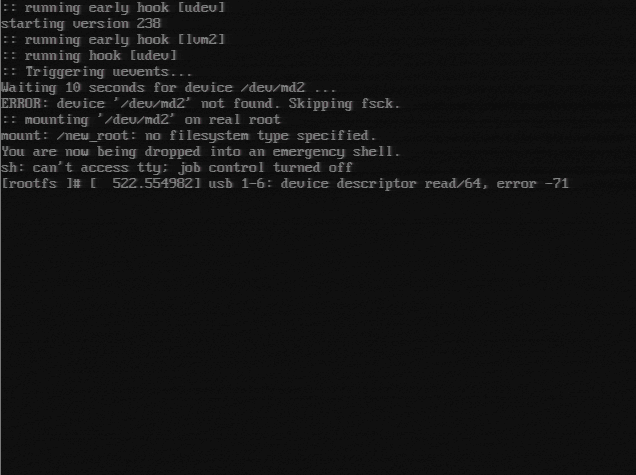
Well that’s pretty illuminating! It can’t find /dev/md2 which is weird now since it wasn’t an issue before (I’ve restarted with my current RAID setup and the previously working GRUB config before), so something must have changed to cause the issue. After a little bit of searching I found some seemingly relevant threads:
After looking at the contents of /etc/default/grub file, I did notice that the supposedly required modules (mdraid09, mdraid1x) were missing… I’m unsure how recently this file changed (I know I haven’t touched it in a while), and if it changed as a result of the server update.
Now I’m relatively certain that misconfigured GRUB2 seems to be the issue. Looking at the Arch guide for GRUB, I decided to try and follow it running grub-install to fix the problem, along with ensuring the relevant settings from the GRUB#RAID section were set.
FROM THE FUTURE - This step was probably wrong/unnecessary, not only does the guide say that it’s for BIOS systems only, I shouldn’t have needed to re-install grub, probably, since it was working prior.
The steps I followed look something like this:
mount the raid1 drive -> mount /dev/md2 /mnt (YMMV)mount the /dev, /proc, other partitions -> mount --bind /proc /mnt/proc/ ; mount --bind /dev /mnt/dev/ ; mount --bind /sys /mnt/sys/chroot into the Arch install to pretend like I’m root on the arch install (Note that a bunch of stuff won’t work (reasonably), for example systemctl will give you an error because it’s not PID 1 if you try to use it.)/etc/default/grub file as the arch guide suggestedgrub-install as the arch guide suggested/etc/default/grubAfter running these steps, I restarted hoping for the best…
FROM THE FUTURE - I missed the crucial step of regenerating the grub configuration (next section in the arch guide) at this point of doing everything… Try not to make the same hasty mistake.
After restarting the server, I was greeted with the GRUB console (visible from the KVM connection), instead of the machine booting correctly. I got my searchin’ shoes on and went on a trek across the internet to find if someone has gotten into this similar predicament:
I found through those links that I should have bene able to use the grub command line to at least once boot into my OS manually, using a command roughly like:
grub> linux <path/to/kernel/image> root=/dev/md2
Unfortunately, this didn’t work for me, and when I went to check /boot (where the generated grub config went), I found it shockingly empty except for grub/… This stood out to me because I’d worked with building customized kernels before using mkinitcpio – it dumps the built kernel images (and a fallback) to /boot so that folder should definitely not be empty. This is when I realized that in addition to running grub-install I needed to re-generate the configs for GRUB to use. I thought maybe after doing that, and re-generating the kernel with mkinitcpio things would go better.
Regenerating the GRUB configuration seemed to pass, though with a bunch of warnings:
[root@rescue /]# grub-mkconfig -o /boot/grub/grub.cfg
Generating grub configuration file ...
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
done
Well great, so the realization is now sinking in that I might have messed up my system pretty bad, but at the very least since I know that the kernel isn’t hard to generate, I can at least try creating it:
[root@rescue /]# mkinitcpio
==> ERROR: '/lib/modules/4.9.85' is not a valid kernel module directory
Yay, more panicking to do! Since I watch my kernel updates pretty intently, I was absolutely sure that there was a kernel module directory on the system (this is also kind of just how Arch works), so I took another look at the mkinitcpio documentation and noted the bit that states how you’re supposed to build kernels that are not necessarily the current one running, a command like ``mkinitcpio -g /boot/linux-custom2.img -k 3.3.0-ARCH` was supposed to do the trick.
Since obviously 3.3.0-ARCH isn’t my kernel version I had to find which one was, which meant checking lib/modules:
[root@rescue /]# ls /lib/modules/
4.15.15-1-ARCH/ extramodules-4.15-ARCH/
Seeing the note about mdadm not being installed in the Arch mkinitcpio guide also worried me, but after taking a close look at the configuration (which I set up when I first set up the server), it was just further down:
# vim:set ft=sh
# MODULES
# The following modules are loaded before any boot hooks are
# run. Advanced users may wish to specify all system modules
# in this array. For instance:
# MODULES=(piix ide_disk reiserfs)
MODULES=()
# BINARIES
# This setting includes any additional binaries a given user may
# wish into the CPIO image. This is run last, so it may be used to
# override the actual binaries included by a given hook
# BINARIES are dependency parsed, so you may safely ignore libraries
BINARIES=()
# FILES
# This setting is similar to BINARIES above, however, files are added
# as-is and are not parsed in any way. This is useful for config files.
FILES=()
# HOOKS
# This is the most important setting in this file. The HOOKS control the
# modules and scripts added to the image, and what happens at boot time.
# Order is important, and it is recommended that you do not change the
# order in which HOOKS are added. Run 'mkinitcpio -H <hook name>' for
# help on a given hook.
# 'base' is _required_ unless you know precisely what you are doing.
# 'udev' is _required_ in order to automatically load modules
# 'filesystems' is _required_ unless you specify your fs modules in MODULES
# Examples:
## This setup specifies all modules in the MODULES setting above.
## No raid, lvm2, or encrypted root is needed.
# HOOKS=(base)
#
## This setup will autodetect all modules for your system and should
## work as a sane default
# HOOKS=(base udev autodetect block filesystems)
#
## This setup will generate a 'full' image which supports most systems.
## No autodetection is done.
# HOOKS=(base udev block filesystems)
#
## This setup assembles a pata mdadm array with an encrypted root FS.
## Note: See 'mkinitcpio -H mdadm' for more information on raid devices.
# HOOKS=(base udev block mdadm encrypt filesystems)
#
## This setup loads an lvm2 volume group on a usb device.
# HOOKS=(base udev block lvm2 filesystems)
#
## NOTE: If you have /usr on a separate partition, you MUST include the
# usr, fsck and shutdown hooks.
HOOKS=(base udev autodetect modconf block mdadm_udev lvm2 filesystems keyboard fsck)
# COMPRESSION
# Use this to compress the initramfs image. By default, gzip compression
# is used. Use 'cat' to create an uncompressed image.
#COMPRESSION="gzip"
#COMPRESSION="bzip2"
#COMPRESSION="lzma"
#COMPRESSION="xz"
#COMPRESSION="lzop"
#COMPRESSION="lz4"
# COMPRESSION_OPTIONS
# Additional options for the compressor
#COMPRESSION_OPTIONS=()
So, no worries there! Time to try mkinitcpio:
[root@rescue /]# mkinitcpio -k 4.15.15-1-ARCH
==> Starting dry run: 4.15.15-1-ARCH
-> Running build hook: [base]
-> Running build hook: [udev]
-> Running build hook: [autodetect]
-> Running build hook: [modconf]
-> Running build hook: [block]
-> Running build hook: [mdadm_udev]
-> Running build hook: [lvm2]
-> Running build hook: [filesystems]
-> Running build hook: [keyboard]
-> Running build hook: [fsck]
==> Generating module dependencies
==> Dry run complete, use -g IMAGE to generate a real image
Dry run looking pretty good! It finds the modules, and it builds them (and there goes that madm_udev that I was worried about). Now, let’s generate an actual kernel image:
[root@rescue /]# mkinitcpio -g /boot/vmlinuz -k 4.15.15-1-ARCH
==> Starting build: 4.15.15-1-ARCH
-> Running build hook: [base]
-> Running build hook: [udev]
-> Running build hook: [autodetect]
-> Running build hook: [modconf]
-> Running build hook: [block]
-> Running build hook: [mdadm_udev]
-> Running build hook: [lvm2]
-> Running build hook: [filesystems]
-> Running build hook: [keyboard]
-> Running build hook: [fsck]
==> Generating module dependencies
==> Creating gzip-compressed initcpio image: /boot/vmlinuz
==> Image generation successful
I chose /boot/vmlinuz as the image name because it looked something like the default name that I remember would get generated. The generated image is present just like I want it to be:
[root@rescue /]# ls -l /boot
total 13080
drwxr-xr-x 6 root root 4096 Apr 18 06:24 grub
-rw-r--r-- 1 root root 13387168 Apr 18 06:36 vmlinuz
Not super confident but /boot/grub/grub.cfg has some code in it and it’s pointing so SOME RAID drive (set root='mduuid/<uuid>' is in grub.cfg), so maybe everything’s good? Also a random SO thread seems to suggest I can ignore the erorrs I saw.
The thought process at this point is that now that I have a bootable kernel image, all I need to do is restart, go back into GRUB console, and try to boot from it. Unfortunately that’s NOT what went down. When I booted back into the GRUB console, the image was present in /boot, but not bootable – I got an error that stated the “magic number” was incorrect. Here’s the gist:
grub> ls # shows you all the drives that grub knows about, for me the right drive is md/2
grub> set root=(md/2) # everything will be relative to this
grub> ls /boot # Just to make sure I see the kernel I'm trying to boot, and also grub folder
grub> linux /boot/vmlinuz root=/dev/md2
<error about magic number being incorrect>
And here’s a screnshot from the KVM screen:
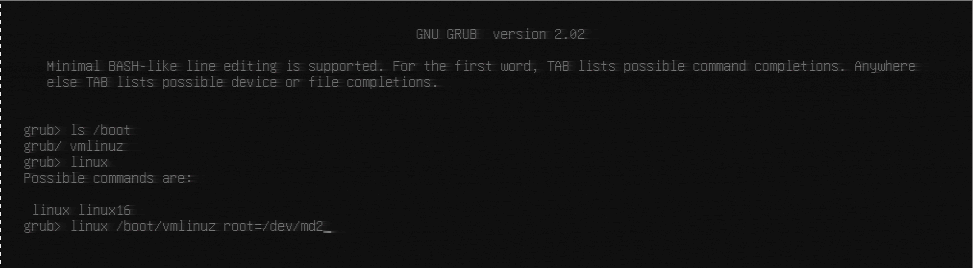
In searching for what this error could mean, I did find an excellent guide on doing these kind of GRUB recoveries, so that helped as well in understand GRUB and the boot process some more.
Since the kernel image I generated wasn’t bootable, clearly it was time to double-check my use of mkinitcpio. One thing I thought might be relevant was that I didn’t use the linux preset when generating the kernel image (-p linux), and I thought that would certainly explain why GRUB couldn’t load it properly when using the grub command line. Time to reboot->mount->mount->chroot to get into the faux arch environment again!
Once inside, I quickly saw that -p wasn’t all I’d need:
[root@rescue /]# mkinitcpio -p linux
==> Building image from preset: /etc/mkinitcpio.d/linux.preset: 'default'
-> -k /boot/vmlinuz-linux -c /etc/mkinitcpio.conf -g /boot/initramfs-linux.img
==> ERROR: invalid kernel specified: `/boot/vmlinuz-linux'
==> Building image from preset: /etc/mkinitcpio.d/linux.preset: 'fallback'
-> -k /boot/vmlinuz-linux -c /etc/mkinitcpio.conf -g /boot/initramfs-linux-fallback.img -S autodetect
==> ERROR: invalid kernel specified: `/boot/vmlinuz-linux'
At this point I’m thinking I really did wipe a bunch of stuff from /boot that needed to be there – I need to do a more basic (full?) kernel build. Turns out that since kernels are delivered just like regular pacman packages, I can just use pacman to repair the kernel!
First I needed to find the compressed (tar.xz) files for the kernel package I just recently installed:
[root@rescue /]# ls /var/cache/pacman/pkg/linux-*
/var/cache/pacman/pkg/linux-4.15.15-1-x86_64.pkg.tar.xz /var/cache/pacman/pkg/linux-firmware-20180119.2a713be-1-any.pkg.tar.xz
/var/cache/pacman/pkg/linux-4.15.3-1-x86_64.pkg.tar.xz /var/cache/pacman/pkg/linux-firmware-20180314.4c0bf11-1-any.pkg.tar.xz
/var/cache/pacman/pkg/linux-api-headers-4.14.8-1-any.pkg.tar.xz
Looks like I’ve got everything I need, so I ran pacman like so:
[root@rescue /]# pacman -U --force /var/cache/pacman/pkg/linux-4.15.15-1-x86_64.pkg.tar.xz /var/cache/pacman/pkg/linux-api-headers-4.14.8-1-any.pkg.tar.xz
loading packages...
warning: linux-4.15.15-1 is up to date -- reinstalling
warning: linux-api-headers-4.14.8-1 is up to date -- reinstalling
resolving dependencies...
looking for conflicting packages...
ages (2) linux-4.15.15-1 linux-api-headers-4.14.8-1
l Installed Size: 115.85 MiB
Net Upgrade Size: 0.00 MiB
roceed with installation? [Y/n] Y
(2/2) checking keys in keyring [######################################################################################################] 100%
(2/2) checking package integrity [######################################################################################################] 100%
(2/2) loading package files [######################################################################################################] 100%
(2/2) checking for file conflicts [######################################################################################################] 100%
(2/2) checking available disk space [######################################################################################################] 100%
:: Processing package changes...
(1/2) reinstalling linux-api-headers [######################################################################################################] 100%
(2/2) reinstalling linux [###########################(2/2) reinstalling linux [###########################(2/2) reinstalling linux [###########################(2/2) reinstalling linux [###########################(2/2) reinstalling linux [###########################(2/2) reinstalling linux [######################################################################] 100%
WARNING: /boot appears to be a separate partition but is not mounted.
:: Running post-transaction hooks...
(1/3) Updating linux module dependencies...
(2/3) Updating linux initcpios...
==> Building image from preset: /etc/mkinitcpio.d/linux.preset: 'default'
-> -k /boot/vmlinuz-linux -c /etc/mkinitcpio.conf -g /boot/initramfs-linux.img
==> Starting build: 4.15.15-1-ARCH
-> Running build hook: [base]
-> Running build hook: [udev]
-> Running build hook: [autodetect]
-> Running build hook: [modconf]
-> Running build hook: [block]
-> Running build hook: [mdadm_udev]
-> Running build hook: [lvm2]
-> Running build hook: [filesystems]
-> Running build hook: [keyboard]
-> Running build hook: [fsck]
==> Generating module dependencies
==> Creating gzip-compressed initcpio image: /boot/initramfs-linux.img
==> Image generation successful
==> Building image from preset: /etc/mkinitcpio.d/linux.preset: 'fallback'
-> -k /boot/vmlinuz-linux -c /etc/mkinitcpio.conf -g /boot/initramfs-linux-fallback.img -S autodetect
==> Starting build: 4.15.15-1-ARCH
-> Running build hook: [base]
-> Running build hook: [udev]
-> Running build hook: [modconf]
-> Running build hook: [block]
==> WARNING: Possibly missing firmware for module: wd719x
==> WARNING: Possibly missing firmware for module: aic94xx
-> Running build hook: [mdadm_udev]
-> Running build hook: [lvm2]
-> Running build hook: [filesystems]
-> Running build hook: [keyboard]
-> Running build hook: [fsck]
==> Generating module dependencies
==> Creating gzip-compressed initcpio image: /boot/initramfs-linux-fallback.img
==> Image generation successful
(3/3) Arming ConditionNeedsUpdate...
[root@rescue /]# ls /boot
grub initramfs-linux-fallback.img initramfs-linux.img vmlinuz-linux
So everything worked, and I’ve got a much more full /boot directory! With this good news, I assumed that I was done with the kernel generation part of the issue.
The next thing to do, now that I was more certain I had a bootable kernel image, was to update GRUB so I didn’t have to do the silly incantation from GRUB command line every time my system booted.
Since I clearly fumbled setting up GRUB, I looked to see if there was anything that would do it for me and grub-probe seemed to fit the bill. I quickly found out, however that due to the way I was mount->mount->chrooting, grub-mkconfig actually never worked properly!
Here’s the quote from the arch guide:
If you are trying to run grub-mkconfig in a chroot or systemd-nspawn container, you might notice that it does not work, complaining that grub-probe cannot get the “canonical path of /dev/sdaX”. In this case, try using arch-chroot as described in the BBS post.
Welp, that explained some of the errors I’d been getting and then some – I needed to be using arch-chroot, so I unmounted and remounted:
root@rescue ~ # umount /mnt/* ; umount /mnt
umount: /mnt/bin: not mounted
umount: /mnt/boot: not mounted
umount: /mnt/etc: not mounted
umount: /mnt/home: not mounted
umount: /mnt/installimage.conf: not mounted
umount: /mnt/installimage.debug: not mounted
umount: /mnt/lib: not mounted
umount: /mnt/lib64: not mounted
umount: /mnt/lost+found: not mounted
umount: /mnt/mnt: not mounted
umount: /mnt/opt: not mounted
umount: /mnt/root: not mounted
umount: /mnt/run: not mounted
umount: /mnt/sbin: not mounted
umount: /mnt/srv: not mounted
umount: /mnt/tmp: not mounted
umount: /mnt/usr: not mounted
umount: /mnt/var: not mounted
Then remounted:
root@rescue ~ # mount /dev/md2 /mnt
Then used arch-chroot:
root@rescue ~ # arch-chroot /mnt
While grub-probe still didn’t work, I decided to re-run grub-mkconfig and got MUCH better output:
sh-4.4# grub-mkconfig -o /boot/grub/grub.cfg
Generating grub configuration file ...
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
Found linux image: /boot/vmlinuz-linux
Found initrd image: /boot/initramfs-linux.img
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
Found fallback initrd image(s) in /boot: initramfs-linux-fallback.img
/usr/bin/grub-probe: warning: Couldn't find physical volume `(null)'. Some modules may be missing from core image..
done
This was pretty encouraging so I restarted and…
Got a successful boot!

I made lots of mistakes, but none of the enough to brick the system, luckily, and learned a little bit about debugging boot-time issues (though I’m not sure I could have done much without KVM access and the excellent rescue capabilities).
I think the critical change that actually fixed things was ensuring that mdraid09 and mdraid1x were in /etc/default/grub required modules +/- regenerating the grub configuration with grub-mkconfig. Everything’s fine and back up after the restart so I’m pretty happy, thought I’d shoot out this blog post just in case anyone had a similar problem.
I mentioned it a little earlier, but I had a 2-drive RAID1 (mirroring) setup until recently when I decided to use the second drive for network-attached-storage for Kubernetes (utilizing CephFS through Rook on k8s). I’m actually not sure why the RAID set up on the one drive was kept, but I’d like to think it’s still useful.
Past me probably didn’t change it out of fear of messing up the configuration on the boot drive. While some may call it “defensive”, I am realizing I might be doing a lot of “fear-based” operations recently, which is usually a sign that I either don’t understand enough about the systems I’m touching, or I need to use simpler systems.
As I mentioned early in the post, I recently switched from CoreOS due to their relatively recent acquisition news. I don’t really have much of an axe to grind against RedHat, but it just doesn’t seem like they’re going to keep investing in CoreOS (as an OS), compared to their own internal efforts.
There were lots of things that initially irked me about the appraoch CoreOS took but once I was used to it, it was nice and rock solid, and I never had to think about it. A problem like this would have been avoided I think due to it’s 2 phase update system (multiple partitions were used for updating so in theory you could always roll back in case of a bad update). Since I was small time, ignition was initially a big hassle, but after figuring it out (and using it, once) it wasn’t too bad. Another downside was the need to run docker containers to get access to what some might consider basic system utilities, but even that I was used to after a while.
While I love Arch Linux (I run it just about everywhere on my own personal machines), the fact that I was scared to update it (and that an update could break it) is a bad sign, at the very least meaning that I need to learn more about it before I should be using it in production. CoreOS was simple enough a simpleton like me could pick it up, use it, run the workloads I cared about (which is basically only Kubernetes, right now), and not have to think twice. Simplicity is valuable.
A thing called Java Web Start exists, and you need icedtea-web to run it. It feels incredibly unsafe, and probably is, but that’s how Hetzner does it’s temporary KVMs.