DDG search drop in powered by ddg.patdryburgh.com

tl;dr - A few more Paxos papers have been produced since the original post, I do the usual writeup. Main benefit/focuses this time look to be centered around increasing throughput by taking load off of the leader node(s) (and assigning the extra work to existing or new nodes).
This is (now) a multi-part blog-post!
I’m not sure if there’s a lot of new Paxos research out there, since I’m not a post graduate student, but thanks to judofyr from HN I found out about a few more that are new (to me):
I’ll give them the same kind of rundown as I did before but do make sure to do your own reading! If you find some mischaracterized descriptions, reach out and let me know. I also just realized that “consensus” is spelled wrong in the original post 🤦.
This paper is a nice and short one – it doesn’t introduce a new variant of Paxos but it introduces a new interesting concept – reading primarily from a quorum of followers to acknowledge a round, combined with a forced immediately subsequent phase to account for pending updates. They call this the “Paxos Quorum Read” protocol and go into the implementation.
There’s a nice picture that sums up how it works:
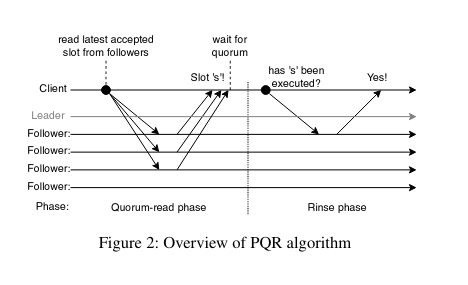
The image is well made and explains it pretty clearly – the ability to do a simple quorum for reads that doesn’t involve the master, and only check one follower in the subsequent round means it’s pretty easy to do more reads. This effect is compounded when Flexible quorums are brought into play, so that load can be spread across followers.
PQR does serve for a nice improvement over stock Paxos:
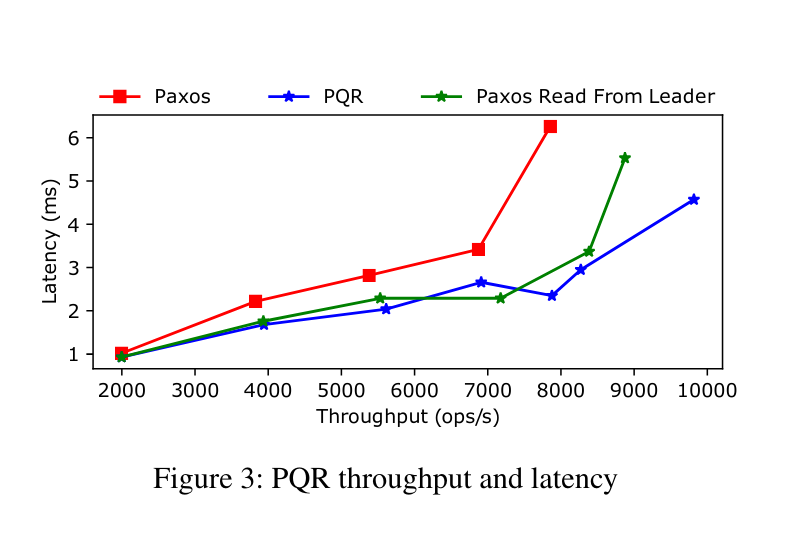
Overall PQR offers/introduces:
Quorum read from a possibly shifting quorum of non-leader nodes, then check one nodes and you can return your answer.
Bipartisan Paxos (“BPaxos”) is really interesting! It introduces a modularized conception of paxos – Leaders, dependency service nodes, proposers, acceptors and replicas (only one of those node types is new). BPaxos’s novel contribution is to “scale” the leaders and proposers, as they are the easily-identifiable bottleneck. With this simple change, the researchers were able to obtain 2x the throughput of EPaxos which is pretty impressive. Bipartisan takes a very pragmatic approach (if that wasn’t already obvious – “scale” is generally something people in non-academic realms think of/optimize for) and uses an off-the-shelf Paxos implementation which is a smart choice, and in doing so actually find bugs in the implementation of EPaxos that went unnoticed for 6 years (!). It can happen to anyone.
This paper serves as a great refresher on the Paxos landscape (as good papers should), starting off with a brief and succint review of Paxos & MultiPaxos and their well-documented failings of such a setup (single leader). Mencius, EPaxos and Caesar (which I don’t think I’ve covered?) are also introduced as solutions, as they enable “multileader” protocols.
So how does BPaxos achieve a speed up? Hello again, our old friend commutability. BPaxos is a “generalized” state replication protocol, which means that it only requires conflicting commands to be executed in the same order (which means that you need to know which commands are conflicting, which can get complex real quick on anything other than a simple key-value store). Paxos introduces the partial ordering of it’s commands by creating a directed graph (notably not acyclic), which are analogous to MultiPaxos logs.
Here’s an image from the paper that lays this out:
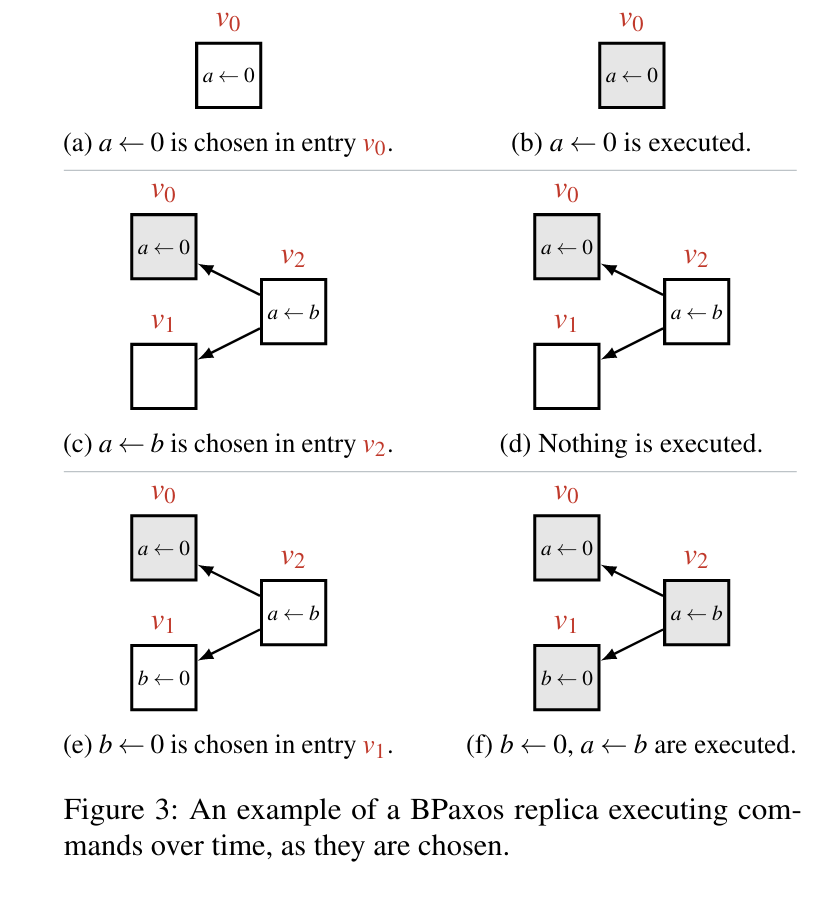
The command graph is analogous to the the command log so we don’t have to think too hard about it, but it introduces an interesting way of modeling executions, and the introduction/possibility of cycles is interesting. The plot thickens as we look at an overview of BPaxos’s execution:
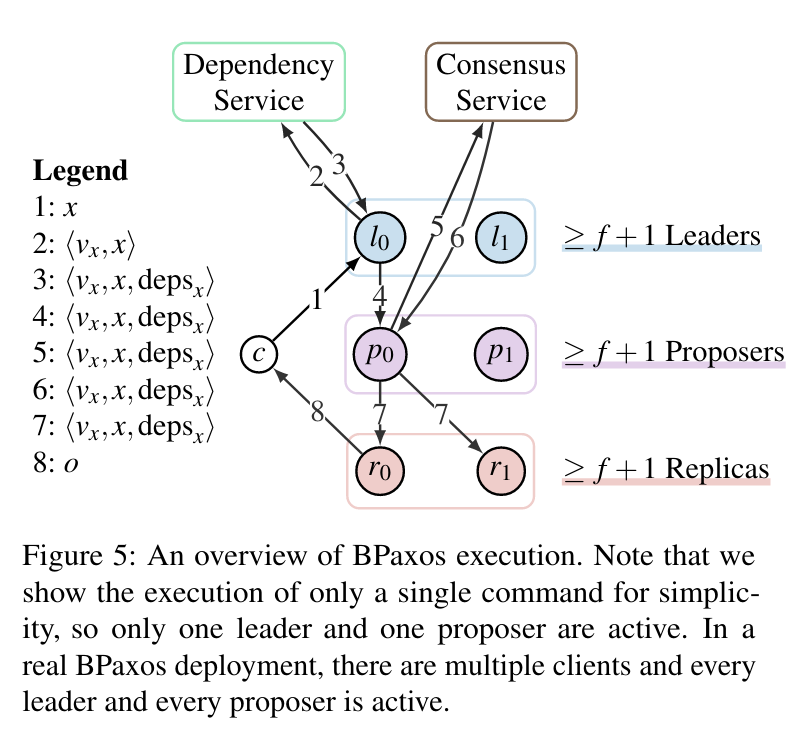
The dependency service plays an important role in deciding which operations conflict and which don’t, which affects required ordering operations. What’s interesting is that there’s an extra quorum step in talking to the dependency service. Leaders must aggregate dependencies from all the dependency service nodes before they can move ahead with forwarding to a proposer. After that, the proposers talk to the “consensus service” (isn’t that what we’re solving here?) which perform a more “traditional” round of consensus (the BPaxos paper uses stock conensus with a ballot zero optimization that allows for choices in only 1 round trip, similar to MultiPaxos).
All this said though, BPaxos does very well compared to EPaxos and MultiPaxos – disaggregating roles and scaling the leaders and proposers is very effective on increasing throughput, and shifting the bottle neck to other parts of the system (which can’t be scaled quite as easily if at all). It’s never made quite clear how the leaders’ work roles are divyed up but I assume this is something that dependency nodes track (so if a write to x goes to two leaders, the coordination point with the dependency service is when the first/second node will realize any needed dependencies on shared data). Most important to remember is that there are two keys to BPaxos:
Here’s a nice picture of the performance comparison:
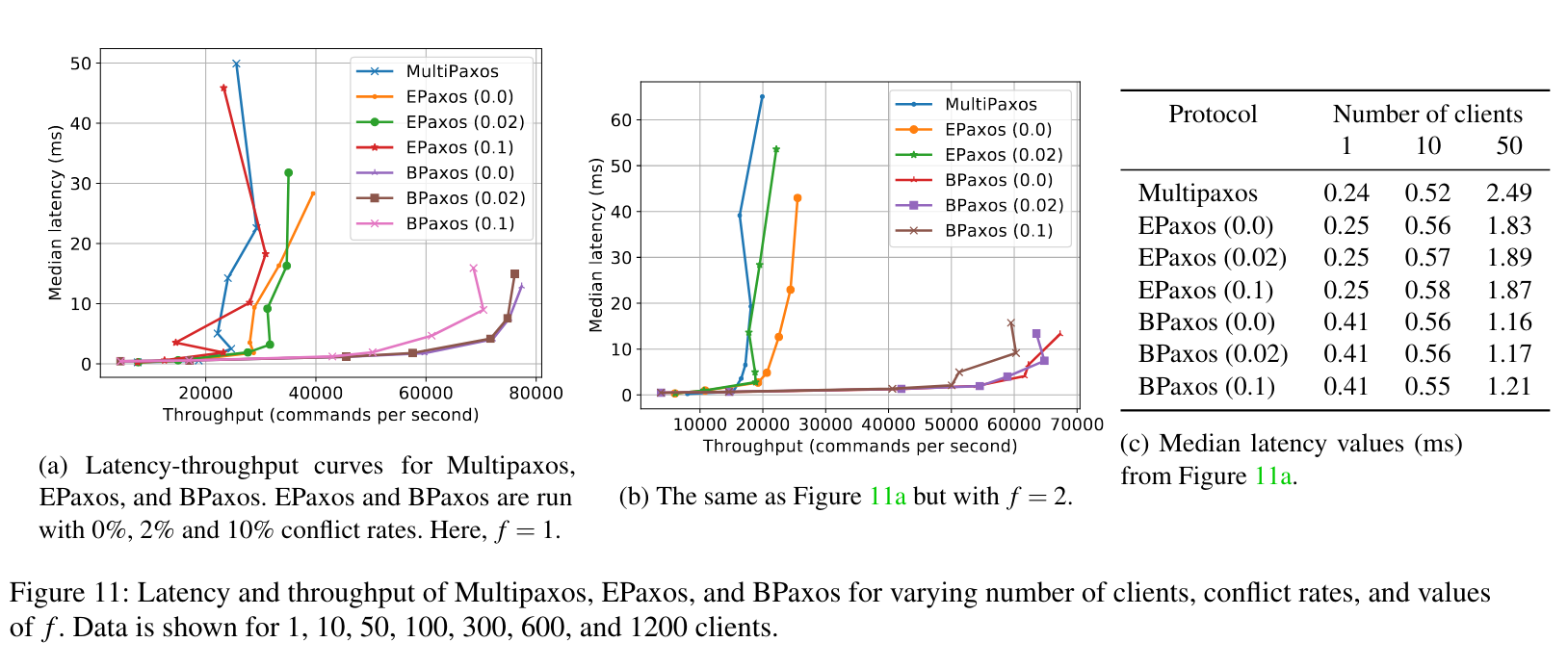
BPaxos offers:
Throw in a graph, model your operations as a graph, add a dependency service, make sure everything runs separately and scale scale scale.
This Paxos variant is interesting as far as I can see – it looks like someone has applied “web scale” to Paxos. The “compartmentalization” approach is focused on two “simple” ideas – decoupling and scaling. What’s nice is this paper also contains a nice concise explanation of the field – Paxos, MultiPaxos and the others are all covered briefly and succinctly. The key ingredient to getting the amazing throughput results that this paper generate lying in identifying unnecessary work being done by key parts of the system. In the MultiPaxos case this means letting the work of notifying Replicas replicas be given to other nodes (leaders in MultiPaxos traditionally have to order writes and communicate paxos round results to Replicas).
Here’s what it looks like when MultiPaxos leaders do the hard work themselves:
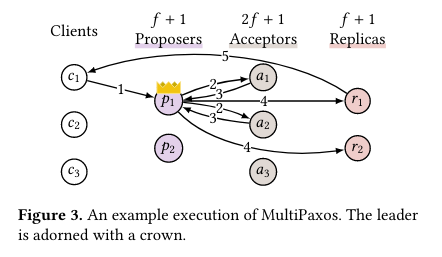
And here’s what it looks like when MultiPaxos leaders leave the hard work to others:
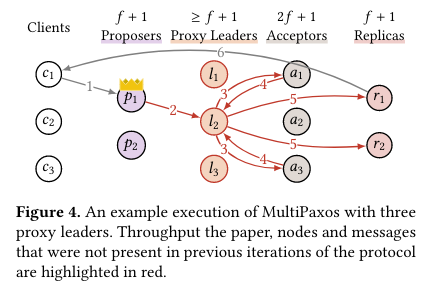
Note the introduction of the “proxy leader” class of nodes – it’s quite a nice solution/shift of the problem – simply freeing up the leader nodes to do only log ordering means that there is more (CPU) time to order log messages! The researchers also do well to get to the question before I can ask it in my head:
Have we really eliminated the leader as a bottleneck, or have we just moved the bottleneck into the proxy leaders? To answer this question, we scale.
They go on to note that you can’t just scale any which way though, the key insight is that once the commands have been ordered, then you can choose whichever downstream acceptors you want (and scale can be applied almost indiscriminately). In addition to scaling the Proxy leaders, they then scale the acceptors, and then the replicas. then, we sprinkle some batching on top! Here’s what things look like by the end for MultiPaxos:
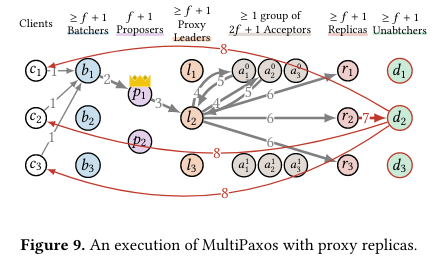
Whew, that’s quite the number of arrows – considering most non Hyperscale “distributed systems” out in the wild have either 3 or 5 nodes (at least those are the numbers most frequently used in the guides), this represents a really interesting shift in the thinking – maybe it’s not that hard to manage this many replicas of each part of the system?
The performance looks absolutely stunning compared to MultiPaxos:
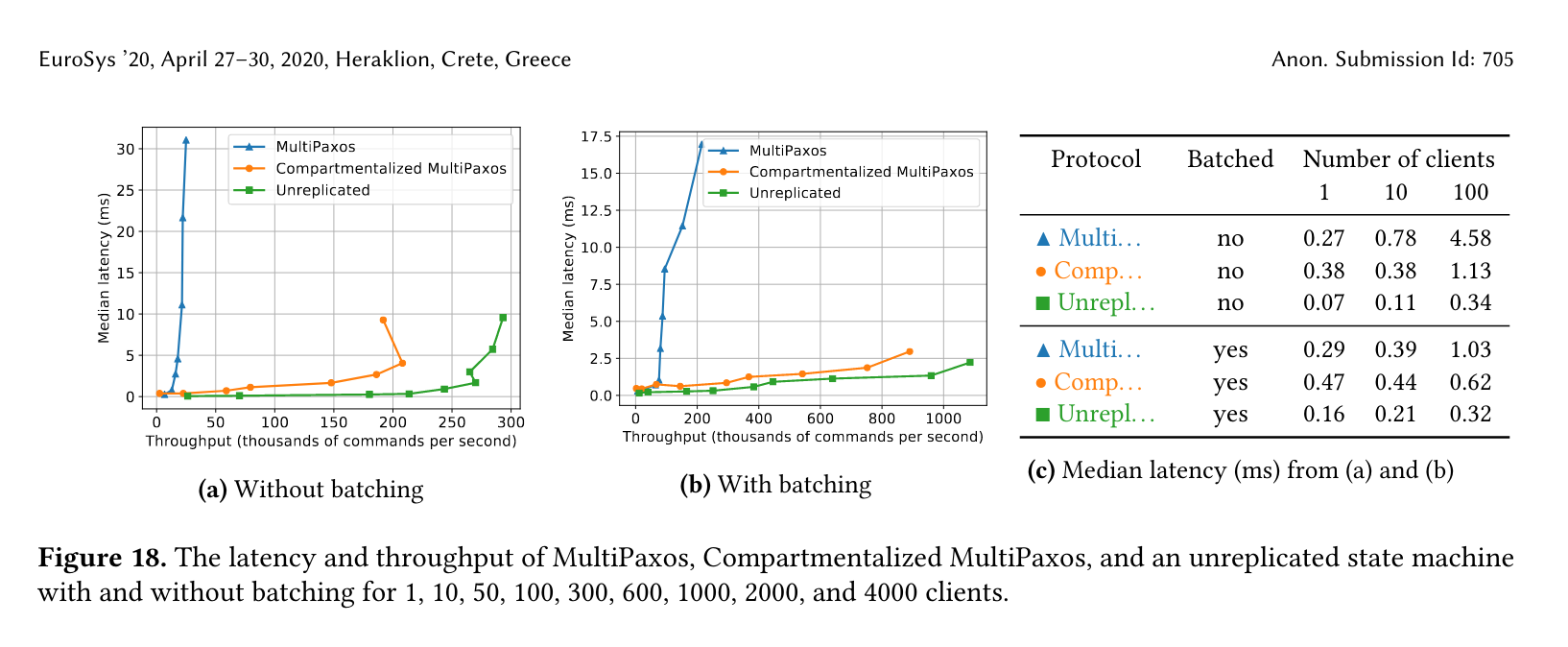
Compartmentalized Paxos offers:
Separate your functionality, introduce nodes that act as demi-leaders, buy more of everything with load balancing and randomization and you’ve got throughput gains with your web-scale.
You can also find information related to the paper here: https://mwhittaker.github.io/publications/compartmentalized_paxos.html
Matchmaker Paxos focuses on the problems of reconfiguration – the process of replacing dead machines with live ones during failure scenarios in Paxos algorithms like MultiPaxos and Raft. The researchers capitalized on the fact that it was an underexplored area and sought to make reconfiguration require less (machine) effort. A bit of a twist though – where old reconfigurations were applied retroactively (once a machine fails, replace it), the techniques in this paper optimize for a world where machines are reconfigured proactively. The key to making this all work is allowing different rounds to have different configurations of acceptors.
There’s a nice explanatory diagram:
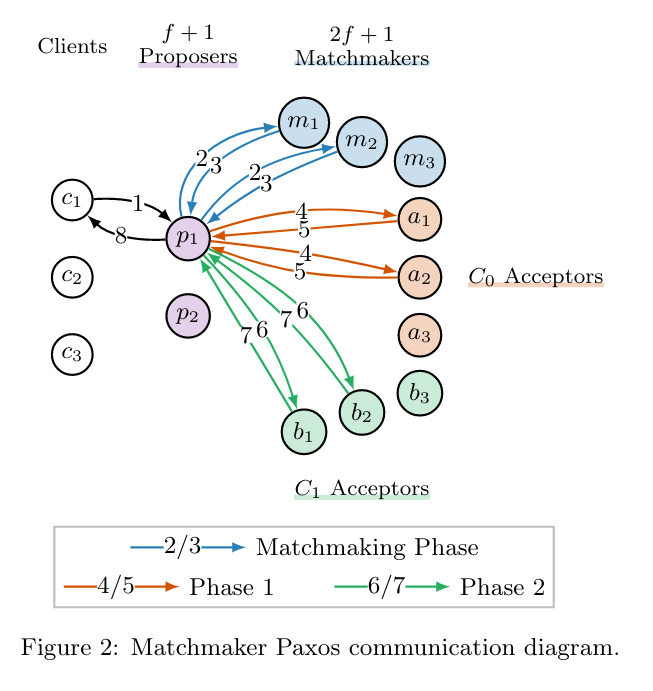
See those that new set of blue machines? Those are the matchmaker machines that let can tell proposers which acceptors to talk to, essentially functioning as a “acceptor service discovery”.
Here’s what “stock” MultiPaxos looks like around horizontal reconfigurations:
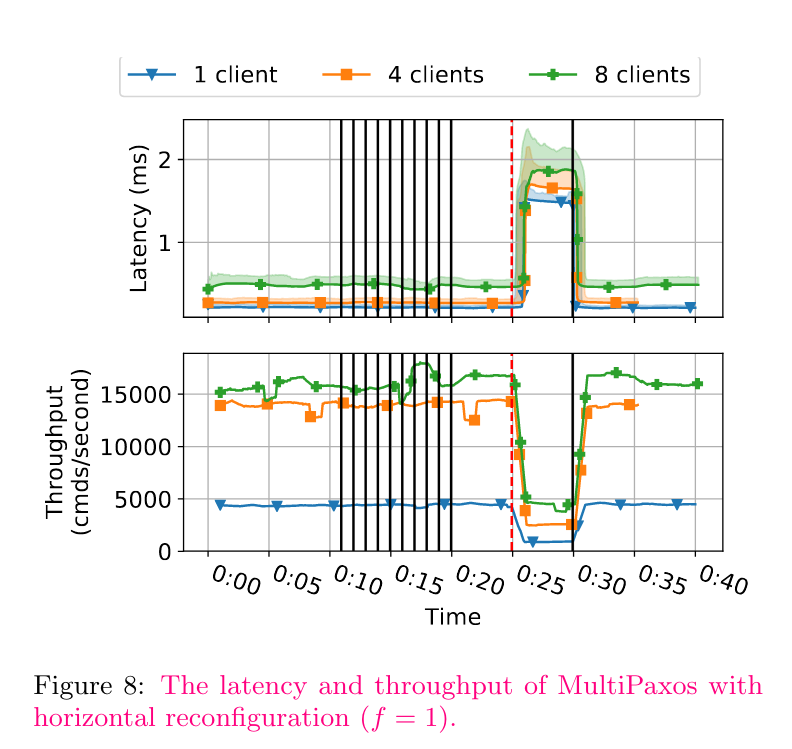
And here’s Matchmaker Paxos, providing a nearly-degradation-free horizontal reconfiguration:
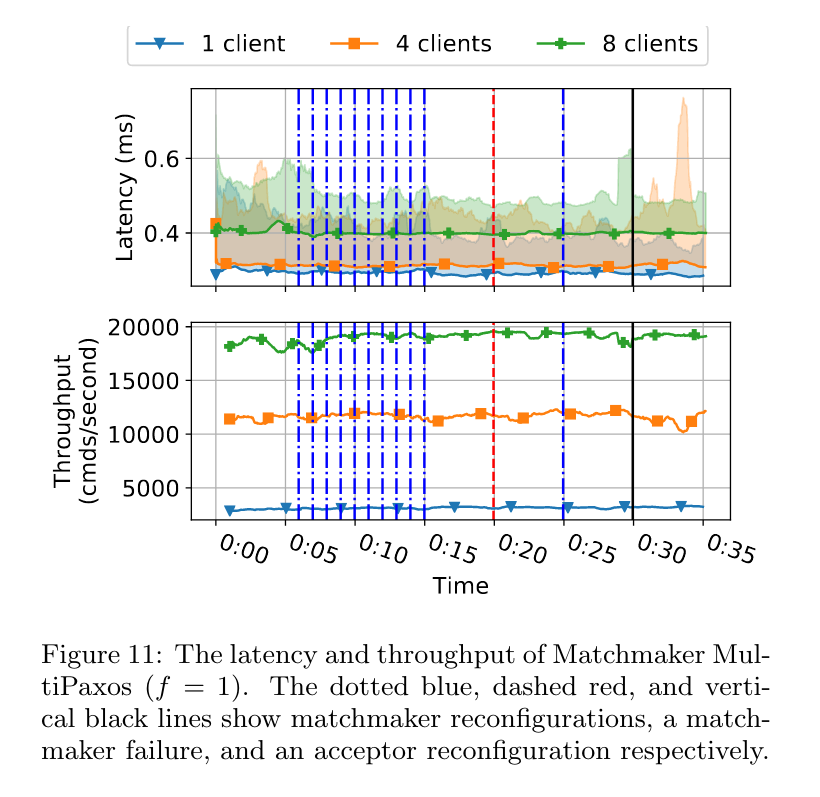
Matchmaker Paxos offers:
Reconfigure so easily you can do it ahead of time by paying the cost of doing acceptor service discovery.
Pig Paxos is a bit interesting because it looks like compartmentalized Paxos at first, but the key to the benefits there are related to increasing efficiency of communication by doing some (aptly named) piggy backing and essentially aggregating/batching of messages. The researchers who worked on Pig Paxos seem to have realized the same thing that compartmentalized paxos did as well – leader nodes are simply doing too much. Pig’s contribution here is that it replaces the leader-follower communication with a a “relay-/aggregate-based message flow”. In somewhat plain-er terms this means that nodes are selected to perform the communication would have done (forwarding the leader’s message and gathering responses). Pig also focuses doing this particularly on strong consistency replication – the only kind of consistency that most application developers can actually wrap their heads around properly.
Here’s a nice explanatory image from the paper:
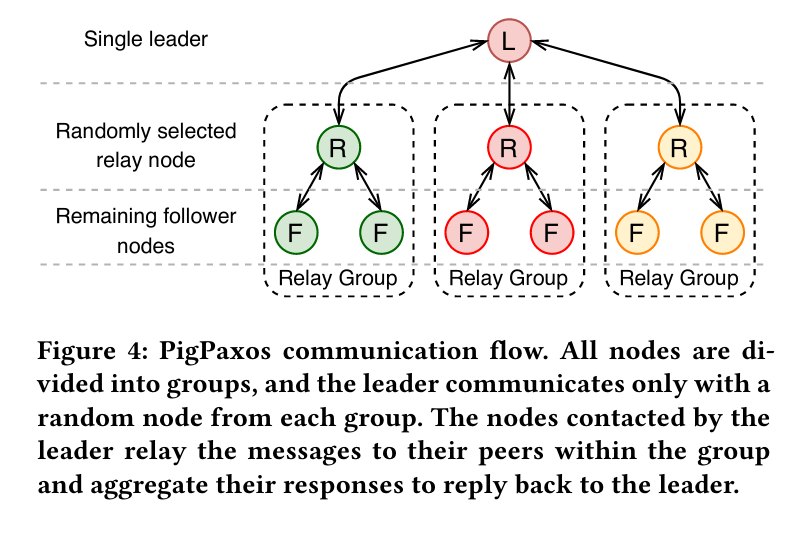
Pig Paxos relies on a randomly selected (and thus load-sharing) group of relay nodes who will serve as a sort of “surrogate” leaders. Similar, but slightly different to the ideas of compartmentalized Paxos (there are definitely less mentions of “scale”, at least). The communication flow diagram is a bit more instructive:
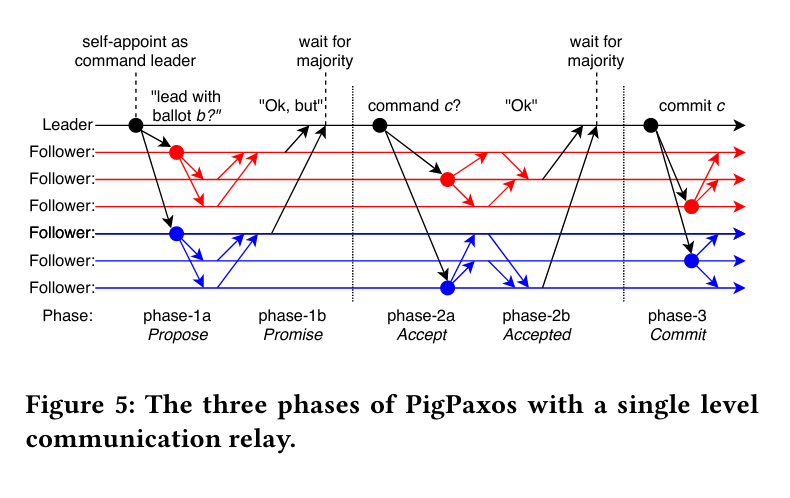
This all looks well and good but PigPaxos may be the weakest entry so far – the optimizations here seem somewhat optimistic compared to other approaches, and there is a considerable amount of new complexity. To be fair to Pig Paxos though, other papers covered in this edition of Paxosmon could be characterized as being somewhat hand-wavy by ignoring the difficulty of managing gobs of new machines (I’m looking at you, compartmentalized paxos).
PigPaxos gets quite an impressive throughput/latency curve:
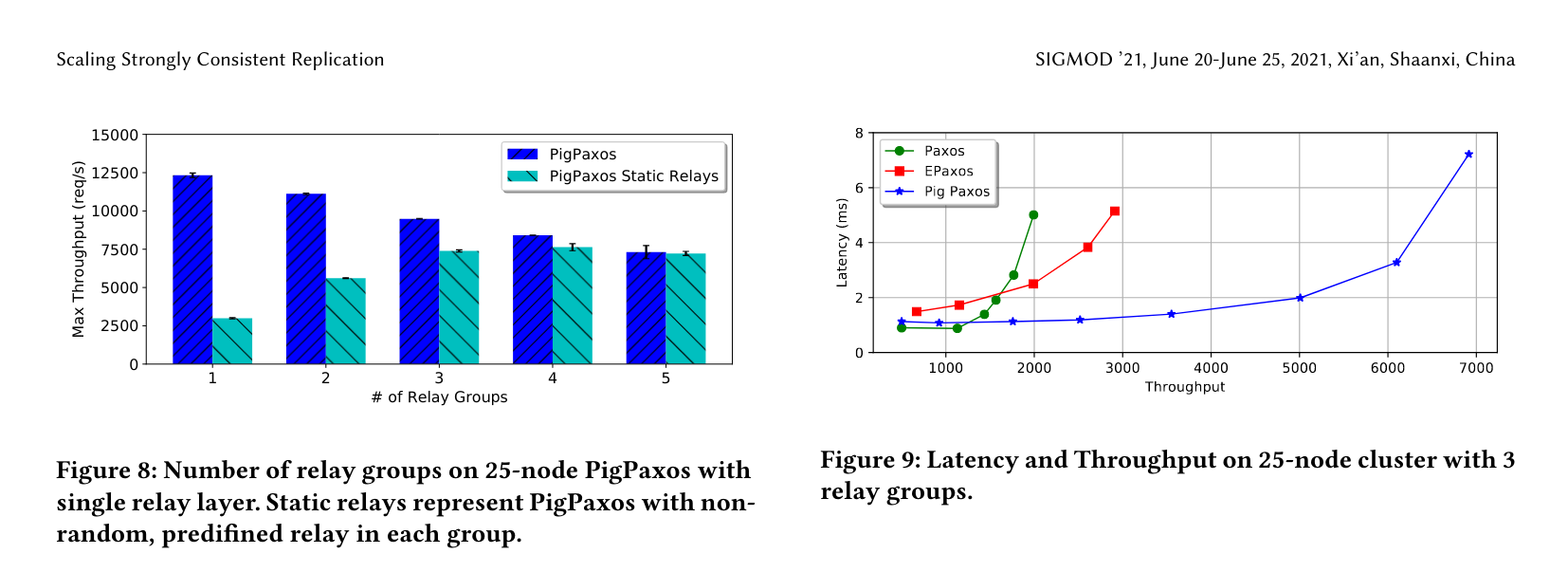
Shunt work from the leader node from your big quorum to communication-only leaders in small quorums, and optimistically you’ll get more throughput (compared to EPaxos and stock Paxos).
Well hopefully it was fun to read about these new developments in the Paxos ecosystem. After reading some of these papers I started wondering if it was Michael Whittaker himself who recommended all these papers to me, but it wasn’t – THanks to Magnus Holm for making me aware of all these developments. Looks like 2020 was a productive year for the Paxos sphere.
It seems like the main advancement of Paxos in this series of papers was shifting work off of the master nodes. I wonder if this indicates a local maximum in the optimization of other parts of the protocol (operation ordering/guarantees, batching, etc). What someone really needs to do is put all these approaches together into a benchmark/shootout of some sort so we can see just how good they all are stacked up next to each other…