DDG search drop in powered by ddg.patdryburgh.com
tl;dr - Work our way through some more type tomfoolery, domain modeling (w/ a light discussion of Domain Driven Design). Next a Component which can operate on the Task domain model, the TaskStore is introduced. Then the types “hit the road” and we build a partial implementation of a SQLiteTaskStore (with assistance from sqlite-simple). The code is available in the haskell-restish-todo repo, @ tag part-2.
After some feedback from the r/haskell post I added an extra section on some more interesting approaches to handling the over-typed first section, based on suggestions from helpful people on r/haskell.
This is a multi part blog post with the following sections:
So if you’ve been following from the previous blog post, you know that we’ve just set up a bunch of machinery for loading configuration and running the server’s CLI aspect. Unfortunately, as in the first post, we’re not actually going to quite make it to the actual “HTTP” part of this endeavor quite yet – we’re going to spend a little time taking care of arguably more abstract API-adjacent tasks. Today we’re going to build castles in the sand – building up the domain of the solution we’re solving with as much help we can get from the formalisms in Haskell.
As usual, I will try to start off with the simplest approach to solving a problem, and be explicit whenever we find a chance to put on our strong typing tophat 💪 🎩 to solve problems in a similar, slightly more complex, but ultimately “better” way (“better” in this instance means with more verification/work done with the type system/compiler).
Today we’ll be going all the way up to getting a “working” main method which starts up a bunch of components, which is the system. Notice I have not mentioned anything about how we’ll express operations to the outside world (eventually HTTP), and that’s becasue those concerns are orthogonal (on an external layer of the DDD onion model). I’ll be covering that in Part 3 (which is where Servant will actually come in).
In this part, I’ve changed things a little bit from the first part – you can find a link to the guaranteed working at the end of every major section. The code snippets in this article should not be copy-pasted in, but are close to what you need for working code, often pointing out new imports or lanuage extensions used.
OK, enough preamble let’s jump in.
There’s a bit of a chicken and egg problem with determining our domain model and important objects, and trying to tease out the structure of our application at a high level – you can come at the problem top down (e.g. starting from the HTTP routes an application must provide and determining the types needed) or bottom up (like we will do now). None of this is “real work” yet, but just getting how we’re thinking down on paper – this is also a good time to see where we can leverage the power of Haskell’s type system. It may seem like it’s not important, but this is the step that differentiates architects from junior engineers (which is obvious, this is the architecting bit).
Let’s figure out what our data model looks like. Here are a few motivating questions (assuming we decide that Task is a good place to start):
Task item?Task are optional?Task? Is there standard metadata that a Task should always have?Task? Is that information part of a Task?Let’s start with a basic definition of tasks (in a file called Types.hs):
Types.hs:
data TaskState = NotStarted
| InProgress
| Completed deriving (Enum, Read, Show)
data Task = Task { tName :: Text
, tDescription :: Text
, tState :: TaskState
}
We’ve already sort of stepped in/around a landmine here in the way that Strings work in haskell – there are actually a bunch of types you could choose for Strings – String (equivalent to [Char]), Text, ByteString, and the strict/lazy derivatives of the last two. sdiehl has written a good guide on it, and there are other good posts and SO threads to consider. Here, we’re going to keep things simple-ish and use Text – this means we’ll need to bone up on conversions to/from text later and there will be some complications, but it’s much better than using the very inefficient basic String type. Bytestring might have been another good option, but we’ll forgo any super deep thinking for now.
Even with this pretty simple domain model, there is a big opportunity to make things more robust here – we could actually use some more advanced polymorphism to make our types a little more malleable:
data Task f = Task { tName :: f Text
, tDescription :: f Text
, tState :: f TaskState
}
type Complete f = f Identity
type Partial f = f Maybe
We did the same trick in in part-1, but this time I’ve added the generalization of Partial f to represent any similarly-constructed partial type. Just like before, what we’ve gained by adding the f is the ability to differentiate between fully formed Complete Tasks (i.e. Task Identity) and Partial Tasks (Task Maybe) which might be used for merging or partial updates or whatever. In case it’s unclear, a Partial Task (AKA Task Maybe) is a Task in which every property it has, is a Maybe! You can see what this might be like if you just do the replacement:
data Task Maybe = Task Maybe { tName :: Maybe Text
, tDescription :: Maybe Text
, tState :: Maybe TaskState
}
This is just like the ability to do mapped types like Partial<T> in typescript. This kind of parametric polymorphism comes in really handy in the likely case that we support a a JSON merge patch standard-compliant PATCH endpoint. In general, we can now avoid writing types that are basically just partial versions of other types, like a TaskUpdate type or TitleOnlyTask, etc. If you’re not comforatble with this brand of polymorphism yet, that’s totally fine! When the time comes you can make seperate types (with names like PartialTask or TaskCreationRequest) in an ad-hoc fashion. We can always change the types later with good assurance that the compiler will find all the bugs for us – don’t get in over your head if you don’t have to just yet.
Whether you make the class simply or in a more complex manner, there’s always a case to be made for making distinct types that expose state information – it enables you to make it impossible to attempt invalid operations with an API you provide. For example, if completing a task has the type signature completeTask :: IncompleteTask -> IO CompletedTask, it becomes impossible to misuse the function to complete a task twice, for example. With that example in mind, let’s put on our strong typing tophats 💪 🎩 and get even more fancy with our type specification – I want to be able to distinguish incomplete and complete tasks at the type level:
data Completed
data InProgress
data NotStarted
data TaskState = Completed | InProgress | NotStarted
data Task f state = Task { tName :: f Text
, tDescription :: f Text
, tState :: f state
}
type Complete f = f Identity
type Partial f = f Maybe
type CompleteTask f = f Identity Completed
type IncompletePartialTask f = f Maybe InProgress
type IncompleteTask f = f Identity InProgress
type NotStartedPartialTask f = f Maybe NotStarted
type NotStartedTask f = f Identity NotStarted
Is this too much? Maybe, we’ll find out later – we can always relax the definitions a little bit later and rework things. More importantly now we can actually be even stricter in our function signatures. Let’s get even more persnickety and introduce some newtypes for tName and tDescription:
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
-- ... other code ...
-- Newtypes preventing careless
newtype TaskName = TaskName { getTName :: Text } deriving (Eq, Show)
newtype TaskDesc = TaskDesc { getTDesc :: Text } deriving (Eq, Show)
data Task f state = Task { tName :: f TaskName
, tDescription :: f TaskDesc
, tState :: f state
}
Now someone can’t even give us a Text value (from Data.Text) without going through a single checkpoint we control. We could use this to ensure that invalid TaskNames are inconstructable to begin with. But why stop there? Why do a little when we can do entirely too much? Let’s put another tophat on top of our tophat & drown ourselves in types:
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE StandaloneDeriving #-}
{-# LANGUAGE TypeSynonymInstances #-}
{-# LANGUAGE FlexibleInstances #-}
-- Individual separate types for tasks to enable specifying them as part of (Task f state)
data Finished = FinishedTask deriving (Eq, Read, Show)
data InProgress = InProgressTask deriving (Eq, Read, Show)
data NotStarted = NotStartedTask deriving (Eq, Read, Show)
-- Task state for abstracting over TaskState
data TaskState = Finished
| InProgress
| NotStarted deriving (Eq, Enum, Read, Show)
-- Newtypes preventing careless
newtype TaskName = TaskName { getTName :: Text } deriving (Eq, Show)
newtype TaskDesc = TaskDesc { getTDesc :: Text } deriving (Eq, Show)
-- The beefy task class
data Task f state = Task { tName :: f TaskName
, tDescription :: f TaskDesc
, tState :: f state
}
-- Completed tasks
type CompletedTask = Task Identity Finished
deriving instance Eq CompletedTask
deriving instance Show CompletedTask
-- Incomplete, partially specified tasks
type IncompletePartialTask = Task Maybe InProgress
deriving instance Eq IncompletePartialTask
deriving instance Show IncompletePartialTask
-- Incomplete, fully specified tasks
type IncompleteTask = Task Identity InProgress
deriving instance Eq IncompleteTask
deriving instance Show IncompleteTask
-- Not started, partially specified tasks
type NotStartedPartialTask = Task Maybe NotStarted
deriving instance Eq NotStartedPartialTask
deriving instance Show NotStartedPartialTask
-- Not started, completely specified tasks
type NotStartedTask = Task Identity NotStarted
deriving instance Eq NotStartedTask
deriving instance Show NotStartedTask
This might be a little insane for our little project, but also is kind of awesome, and the code should be relatively easy to follow. I might be punching above my weight with this level of specification, but this kind of fun is a big part of the joy of Haskell in my mind. I can’t think of another non-ML language (which the majority of the world is using) where syntax is this clear and you can “say what you mean” this rigidly. I am definitely pushing Haskell (look at all the new language extensions along the way!) to get to such a specified model, pushing Haskell to produce even stricter checks for me by tinkering. It’s all in good fun until you encounter a compiler error that you can’t understand. Anyway, let’s get into the language extensions I enabled to make the code snippet(s) above possible:
OverloadedStrings - Easier to work with Strings and autoconversions where possible to TextStandaloneDeriving - Forced by the f type in Task, since Haskell doesn’t know what the f type is, and the normal deriving clause has no way to tell itTypeSynonymInstances - Due to the fact that I used StandaloneDeriving on a type-based alias (normally it only takes actual type constructors)… Eventually I could actually remove this for some reason.FlexibleInstances - Standalone instances like Eq IncompleteTask break the requirement of all type variables appearing at most once in instance head (I’m least sure about this one)GeneralizedNewtypeDeriving - To ensure that the newtype instances can be treated the same as the type they’re made of (i.e. TaskName is more or less equivalent to a regular Text)I want to again note that I’m very very likely going to regret this level of type specification but it’s nice to be able to get it to compile for now at least. It’s absolutely fine to stop at any of the previous steps before I got to this bit of madness, but I did want to see how far I could go – hopefully any problems from here on out will be learning experiences as well.
This is a small rant on why DDD is important - feel free to skip it if you’re full up on hastily stated opinons for the day.
I’ve mentioned it a few times in passing now but Domain Driven Design (DDD) is one of the important schools of thought/patterns/paradigms in software design. The idea of separating and encapsulating your concerns at different layers, the onion model is a thoroughly practical concept and the only good way I’ve seen of truly separating domain concerns and other adjacent code (like JSON marshalling or HTTP requests). It’s very hard to manage complexity well without thinking in a way similar to what DDD suggests – whether you arrive at it yourself or learn about DDD from others.
Validatable typeclassOK, so now we have a Task class, but here’s another important distinction we should try to make, we should be able to determine when a Task is not only well-typed/sound but also “valid”, for our defnition of valid. I mentioned it in passing in the previous section, but rather than taking the correct-by-construction route (constraining how Task/TaskName/TaskDesc values can be made), I’m going to solve this problem by introducing a typeclass to deal with the types that can be validated in some way. The concept is simple:
newtype FieldName = FieldName { getFieldName :: Text } deriving (Eq, Show, Read)
data ValidationError = InvalidField FieldName
| MissingField FieldName deriving (Eq, Show, Read)
data Validated t = Validated t
class Validatable t where
validate :: t -> Either ValidationError (Validated t)
Some of the tricks from before are used here but line-by-line the code is straight forward:
newtype FieldName is there to ensure that whoever makes a ValidationError is forced to be specific abou the Text they’re talking aboutValidationError is an enumeration of the types of errors that could happen during validationValidated t is a product type that basically means nothing outside of the fact that something was validated (the type will be exported, but without the constructor, forcing people to go through Validatable’s validate method)Validatable t typeclass is there to give implementers of Validatable types a chance to set their validation logicWith this in place, let’s define what validation looks like for a the types of Tasks we’ve defined. In general I like to think of a Valid Task (see what I did there?) as a task with a non-empty name and a non-empty description (state can’t possibly be invalid at this point, as long as it’s present). Here’s the implementation for CompletedTask:
instance Validatable CompletedTask where
validate t = if isEmpty name then
Left (InvalidField (FieldName "name"))
else
if isEmpty description then
Left (InvalidField (FieldName "description"))
else
Right (Validated t)
where
name :: DT.Text
name = getTName $ runIdentity $ tName $ t
description :: DT.Text
description = getTDesc $ runIdentity $ tDescription t
isEmpty :: DT.Text -> Bool
isEmpty = (==0) . DT.length
The intense types we’ve made have already caused some complexity, look at the unwrapping we need to do to get to the actual name of task in the where clause. I was able to quite easily follow the compiler through my mistakes so I’m not completely spooked yet but I just wanted to note that this is often a result of the additional cleverness from before, if you ever feel you need to turn back and make things simpler (at least at first), don’t hesitate to do so.
There’s another decision made here, which is where I chose to add the Valid a class. The natural choice for me was to put it on the outside – Valid CompletedTask is really Valid (Task Identity Finished), but I could have done something like adding a type parameter (just like we did with Task f state) to include the validation as a part of the task itself. I’ve chosen to consider the task’s status as part of the task, but not the tasks’s validity – this is a design choice on my part.
Anyway, back to the implementation – it looks right, but the nested if statements kind of stick in my craw. Let’s make it a little more generic/clean… How can we do this? I know there’s a set of checks I want to run, and they all must pass for an object to be valid… Thinking about this in code:
type ValidationCheck t = t -> Maybe ValidationError
class Validatable t where
validate :: t -> Either ValidationError (Validated t)
validationChecks :: [ValidationCheck t]
Some functional concepts can help us out here – in particular the basics of map/reduce/filtering (where people normally get their introduction to functional programming). Restated, what I want to do is have a list of validation functions run on the given object, and ensure that none of them produce ValidationErrors. I could also solve this by reducing/folding the object over functions, but I think (f)mapping and filtering is the most straight forward way to obtain all the ValidationErrors if they want to.
With this realization, it might make sense to change the Validatable typeclass a bit more… We should be able to deduce a general definition of validate in terms of validationChecks, and maybe add an isValid that just produces a bool, since sometimes that’s all a consumer might care about. We can also now cut down on the actual mechanical code to a list of individual checks. Let’s get out our strong typing tophats 💪 🎩 and see what this might look like:
import qualified Data.Text as DT
import Data.Either (isRight)
import Data.Maybe (isJust, fromJust)
import Data.Functor.Identity (Identity(..))
-- ... other code ...
type FullySpecifiedTask = Task Identity
type PartialTask = Task Maybe
taskNameField :: FieldName
taskNameField = FieldName "name"
taskDescField :: FieldName
taskDescField = FieldName "description"
-- | Helper function to access task name for fully specified task
-- this works for both `FullySpecifiedTask state` (where state can vary, e.g. s`CompletedTask`(~`Task Identity Finished`) or `IncompleteTask`s (~`Task Identity InProgress`)
fsTaskName :: FullySpecifiedTask state -> DT.Text
fsTaskName = DT.strip . getTName . runIdentity . tName
fsTaskDesc :: FullySpecifiedTask state -> DT.Text
fsTaskDesc = DT.strip . getTDesc . runIdentity . tDescription
instance Validatable (FullySpecifiedTask state) where
validationChecks = [checkName, checkDescription]
where
checkName :: (FullySpecifiedTask state) -> Maybe ValidationError
checkName t = if DT.null (fsTaskName t) then Just (InvalidField taskNameField) else Nothing
checkDescription :: (FullySpecifiedTask state) -> Maybe ValidationError
checkDescription t = if DT.null (fsTaskDesc t) then Just (InvalidField taskDescField) else Nothing
pTaskName :: PartialTask state -> Maybe DT.Text
pTaskName = (DT.strip . getTName <$>) . tName
pTaskDesc :: PartialTask state -> Maybe DT.Text
pTaskDesc = (DT.strip . getTDesc <$>) . tDescription
instance Validatable (PartialTask state) where
validationChecks = [checkName, checkDescription]
where
checkName :: (PartialTask state) -> Maybe ValidationError
checkName = maybe (Just (MissingField taskNameField)) notEmptyIfPresent . pTaskName
where
notEmptyIfPresent :: DT.Text -> Maybe ValidationError
notEmptyIfPresent v = if DT.null v then Just (InvalidField taskNameField) else Nothing
checkDescription :: (PartialTask state) -> Maybe ValidationError
checkDescription = maybe (Just (MissingField taskDescField)) notEmptyIfPresent . pTaskDesc
where
notEmptyIfPresent :: DT.Text -> Maybe ValidationError
notEmptyIfPresent v = if DT.null v then Just (InvalidField taskDescField) else Nothing
The code got longer, but I’m pretty satisfied – by defining Validatable on PartialTask state, we’ve defined it for both CompletedTasks and IncompleteTasks, since state is allowed to be unknown, kind of. I can just focus on the list of functions specifying how a value could be invalid. I don’t necessarily live by the DRY principle, but this is definitely DRYer than what we had before, and should pay dividends for every instance we write (which again, is unfortunately a bunch). A few notes about the code:
IncompleteTask to InProgressTask to better match the stateTraversable (validate/validationChecks), BiFunctor (isValid).qualified import of Data.Text is important to prevent namespace clashes with the Prelude for functions like length and null.null exists for checking empty lists (SO Post). There seems to be a very real penalty for not using it (O(N) vs O(1)) so I added it in and removed all instanced of my little isEmpty helper function.<$>(fmap) and it’s friends for so long I totally forgot about this built in langauge feature.Specifying all these instances for all the types synonyms (which are basically pre-set combinations of product tyeps) we specified above is a bit tedious, but now we’ve got a Validatable fully and partially specified Tasks!
The code got longer, but I’m pretty satisfied – by defining
ValidatableonPartialTask state, we’ve defined it for bothCompletedTasks andIncompleteTasks, sincestateis allowed to be unknown.
If this quote from the previous section threw you a little for a loop, you can blame Haskell. Turns out every time you write a definition like:
someFunc :: a -> Int
You’re actually doing something called type quantification with roots in another thing called System F (which is basically the source of all parametric polymorphism as we know it today). You’re really writing:
someFunc :: forall a. a -> Int
If you just take the english for what it stands for without thinking deeply, you’re defining someFunc for all as – you’re creating a function that no matter what a is, can give back an Int. So the forall is implied in the first example, and explicit in the second. The example might not seem very useful, but forall can be used in a bunch of places, for example:
data Backend = Backend { forall b. TaskStore b => store :: b }
Normally, we’d have to bubble that b up to the definition of Backend (making it Backend b), but here we can actually express that “for any b, as long as it is TaskStore, it can be in this spot”. We’ve managed to actually hide the b from users of Backend! Now they don’t have to care about what the store is used by the Backend. Whether you want this behavior or not is debatable – I like compound type names like Backend SQLite – but at least it’s your choice.
Components that act on our domain modelsReturning to our regularly schedule programming, we’ve just finished building some beefy bordering on excessive abstractions on top of our basic Task type. Let’s start thinking about things that can create and manipulate these Tasks (our domain model): Components.
While OOP might have fallen out of favor in many places, I’m a staunch believer in componentizing the internal workings of large scale applications I write. Object Oriented Programming is not right/wrong/good/bad by default, it’s just a paradigm – context and implementation are important. Somewhat ironically I think haskell’s heavily functional class system and the way in which typeclasses work is a really good fit for OOP-style thinking – unlike focusing building up object hierarchies as we might do in Python (have you seen their cool new type hinting features?) or Java, we can cleanly separate what data is crucial for a type to know about itself, and what functions should be possible if you’re holding an instance of the class (and even attach data that types should know about themselves at the typeclass level, which we’ve done with validationChecks).
At a higher level, components are interesting because they arrive almost naturally as a tool for separating large arenas of functionality in any large system, if not only for the better ergonomics. Very soon after starting to think up domain models, I find that it’s good to think of the components/functionality that you would need to serve the domain – doing this leads to less and less surprise when you start to build the external side of the system. Again, you could go with just a bag of functions in a bunch of individual module files, but I prefer the creation of Components which are first-class objects in the system because they can help encapsulate necessary runtime properties (like, holding a configuration parameter of all the functions you would call).
Here are some things to think about:
These questions are pretty lofty and general for the humble app we’ll be making, but they’re nice food for thought anyway. Going back to the abstract, here’s a wishlist of things that independent Components should generally be able to do:
Here are some goals I might call “stretch” goals – they’re awesome but not absolutely crucial, and can be tacked on in generic ways:
One thing we’re kind of skipping over here is the distinction between a typeclass method call, and an explicit Command-parsing and executing strategy (“command” as in Command Query Response Seperation). In the end I kind of think of Command parsing/taking as more of a transport layer (weirdly enough, in the same way that HTTP is), so I’m going to focus on the most direct methodology here – direct (typeclass) method invocations.
ComponentsHere’s a real simple typeclass that sort of captures the functionality we thought was crucial for some type c:
-- | A simple Component typeclass parametrized over the type of configuration it takes
class Component c where
start :: c -> IO ()
stop :: c -> IO ()
Simple, but not very useful – let’s make this more interesting by composing this typeclass with some more specific ones that will constrain the space of eligible types.
TaskStoreLet’s take some time to think about what an TaskStore should be/be able to do, in a very specific sense:
Component so we can invoke it’s lifecycle (and think about it in that way, even though we’re not doing much with lifecycle now)Todo instance we’ve created that will be readable at a later timeTodo instance (how do we know which one? well we’ll need some kind of identifier)Todo instanceTodo instanceAs you might have noticed, this is the CRUD pattern (read the first letter of each point) – we’re basically building a database-like abstraction. Despite what might seem like simple duplication, this is actually abstraction – not because we’ll ever use a different backing store (we probably won’t) but more because we can think without worrying about the difficulties of maintaining indices or creating tables or maintaining consistency. We can deal abstract over database specifics (even if it’s just the one database) with this Component, and live in our white castle for a little longer (we’ll deal with making it “real” later).
Let’s write a sketch of the typeclass that encapsulates what we’d expect of a TaskStore:
class Component c where
start :: c -> IO ()
stop :: c -> IO ()
data TaskStoreError = NoSuchTask TaskID
| UnexpectedError DT.Text
deriving (Eq, Show, Read)
newtype TaskID = TaskID { getTaskID :: Int } deriving (Eq, Show, Read)
class Component c => TaskStore c where
persistTask :: c -> Validated (FullySpecifiedTask state) -> Either TaskStoreError (FullySpecifiedTask state)
completeTask :: c -> TaskID -> Either TaskStoreError CompletedTask
getTask :: c -> TaskID -> Either TaskStoreError (FullySpecifiedTask state)
updateTask :: c -> TaskID -> PartialTask state -> Either TaskStoreError (FullySpecifiedTask state)
deleteTask :: c -> TaskID -> Either TaskStoreError (FullySpecifiedTask state)
Alright, here’s where the theoretical benefit of all the type wrangling we did comes along. By being very specific about our types means that when I write Validated (FullySpecifiedTask state), I can read that as “a validated, fully specified task in some unknown state”. Similarly, when I can be more specific in the case of completeTask, expecting that the method will return to me a CompletedTask, which is the same as a FullySpecifiedTask Finished, in other words “a fully specified task in the completed state”. This specificity, being enforced by the compiler hopefully menas we can prevent ourselves from misusing the API this component presents at the code level – as in you can’t write code that will even try to persist a task that isn’t completely specified.
I’ll get off the strong typing high horse (tm) here and say that while this level of type-level specificity is amazing in my own opinion (and unheard of or table stakes for others, everyone’s different), it’s maybe not the most necessary thing to spend hours on – if you have a deadline, and need to get a feature out the door, you might be better off going with a simple Task type that isn’t parametrized at all, and judging whether you need this extra safety (I think you almost always should do it if you can afford to, it’s why you’re using Haskell and not language X, right?).
Another thing you woud have likely noticed is that we’ve actually required that not only does the type that can function as a TaskStore must already be a Component. Hopefully your head doesn’t feel too heavy with the strong typing tophat 💪 🎩 you’ve been wearing this whole time. Haskell’s typeclass system and excellent support for parametric polymorphism is one of it’s best features, if you can’t tell already. Constraints on typeclasses serve as a way to implement OOP-style inheritance and give us the composability everyone’s been wanting from OOP-focused languages with weaker type systems. Languages other than haskell also have similar systems – Golang’s duck-typing at the interface level approach is kind of like this but a bit looser, Rust has traits which are the closest thing I’ve seen, and of course some JVM based languages are in the mix (off the top of my head Scala’s traits , Clojure’s protocols seem like the right analogues).
Also note that there are two new entities I didn’t discuss much:TaskID and TaskStoreError. The TaskStoreError type will contain (at least for now) my guesses at the ways things could go wrong with this component. Haskell uses values as exceptions and this is a good example of it (even though I haven’t defined it yet). More importantly, this abstraction over “things that can go wrong” (💪 🎩) allows me to unify how different implementations surface their almost certainly implementation-specific errors later, under some type you might call an AppError. This is something that we take for granted in Haskell-land, but it’s absolutely not the case in other languages – people have to actually worry about error classification and knowing what’s what at runtime and stuff in other languages.
TaskID is a bit of a sidetrack, so let’s diverge and talk about it.
Task? Enter the WithID product typeWe touched on this a tiny bit before, but this really extends to where you think the line is drawn between an object itself and it’s metadata. Is the ID of an object in a database system a property of the object or of some nebulous metadata that sort of follows it around? Analogies/anecdata is bad but this is like thinking that your ID (government-issues, company-issues, even your very name) is part of you in the physical sense. Maybe it doesn’t make sense to think of objects as physical things, but if we go with that assumption, a lot of OOP is going to look very silly. Anyway, I’m making the choice that identification metadata is NOT part of the object. Another decent argument is that you really only seem to need the identity when someone or something needs to find/track you – you can make a case for this piece of data being non-essential. Yet another decent argument is whether the concept of a Task can exist without an ID – the answer is yes (at creation time, since it doesn’t have a server-assigned one, though this might be different if you allowed user-assigned task IDs).
In any case, the choice to treat ID as an external piece of information makes things more difficult due to having to wrap and unwrap this data everytime I think about/use some Task stuff, but it helps me sleep better at night (in my bed inside the ivory tower of theory) so there’s that.
OK, so let’s introduce the WithID type. It’s pretty simple:
WithId a = { id :: Int
, obj :: a
}
This is just about the simplest way we could make this. But exposing sequential numeric ids to external API users is so 1999 (not going to lie I still do it sometimes when I use SQLite), what about v1/v4/v5 UUIDs?
WithId a = { id :: UUID
, obj :: a
}
Thanks to the uuid package we’ve got some nice access to reasonable UUID class that we can actually use. Well now we have a tiny bit of a conundrum, what if we decide to have objects that have both? Indeed, in may database systems there’s actually a hidden column – SQLite has rowid and Postgres has oids which are disabled since 8.0 – and what about the simple case that we want to use numeric IDs for internal API access and UUIDs for external or something (whether you should or not is another question). How should we handle this divergence? At the very least there are three ways:
data WithId a = { id :: Maybe Int
, uuid :: Maybe UUID
, obj :: a
}
The idea here is that we just include both, which can be simplified if you just want to commit to always having both be available.
newtype NumericID = { getNumericId :: Int } deriving (Eq, Show, Read)
data TaskID = NumericID
| UUID deriving (Eq, Show, Read)
data WithId a = { id :: TaskID
, obj :: a
}
The idea here is to create a sum type (really a disjoint union) and store that in the space. This means code we write will deal in TaskIDsThe other choice is to parametrize the choice:
data WithId idt a = { id :: idt
, obj :: a
}
type WithNumericId = WithID Int a;
type WithUUID = WithID UUID a;
type WithAllIds = WithID (Int, UUID) a;
This is the most complex of the options, but it provides some interesting tradeoffs. For the cost of additional type complexity, we’ve actually gained the ability to gracefully handle and be very specific about all 3 individual cases, and more specifically reflect the state of things at the type level, and give people who use this type a little more information. I’m itching to choose this, just because it seems fancier, but what are the actual tradeoffs here?
The basic idea here is that to handle this discrepancy (the fact that we might want to use the Int ID sometimes and UUID other times, since this is what we’re allowing for), we’re going to have to write some case code (2 sets of code that look very similar) somewhere. Or do we? One way we abstract (💪 🎩) over these differing implementations is by creating a typeclass that encapsulated what we want to know about these two. In particular, we’re most likely going to be using them in the at least the following arenas:
JSON encoding/decoding is going to be more-or-less taken care of automatically by [aeson’s magic][hackage-aeson] (including use of GHC.Generics), but that second bit is something we have to deal with, most likely – since we’re writing the abstraction that covers the database. The first thing I can think of that is going to be important regardless of what kind of ID is being used is the ability to turn it into a value that SQL can read – If we were doing string interpolation (again don’t), then this would mean Show (toString, essentially) instances. Since we’re going to be using a DB library that can understand Ints as well as Strings, let’s keep the types rich, and assume that all we really want is some functionality like:
class HasSQLID where
getSQLIDValue a -> ???
-- ??? represents some class that is OK for whatever library we're using to put in a query as a param
As long as we can ensure the implementations backing approach #2 (sum type) and approach #3 (parametrization) can both conform to this typeclass, we’re OK. The difference between doing this implementation seems to be identical. Making the typeclass instances (as in instance HasSQLID WithID vs instance HasSQLID WithNumericID) seem to differ only in where the case happens, whether it’s in getSQLIDValue (in the instance HasSQLID WithID case, since it’s a sum type), or whether it’s done at the type sytem level (you need ~3 different instances of HasSQLID).
Thinking about it a little more though, it turns out we can actually define ProducesSQLID in ~1 instance for WithID idt a though, by using a constraint on the type of idt. As long as we can ensure that idt satisfies ProducesSQLID, we can actually write a generic instance, by just defering to idt’s instance. On the other hand, if we think about the WithID instance a little bit more, we can actually do the same thing, but one step further – we can actually just derive HasSQLID, as long as it’s defined for all of the types it could be (i.e. NumericID and UUID).
So #2 seems like the least-code, least-complex way to do things (despite wanting to go with #3 because it’s got more/cooler type machinery in it), but all this thinking got me thinking about another thing: GADTs! As a solution, it’s kind of a mix between #2 and #3. This is almost the perfect use case for them:
data WithID a where
UUIDID :: UUID -> a -> WithID a
IntID :: Int -> a -> WithID a
I’ve been looking for a chance to use (and finally understand) GADTs for a while (there’s a great lecture/talk on it by Richard Eisenberg on YT), so I’m going to go with this approach, despite the relatively little amount of time I’ve spent talking about it. It’s a terrible way to make the decision but this blog post is long enough and long story short I’ve wanted to see if I coiuld use GADTs naturally somewhere so I gotta move on – if it helps it’s kind of like I picked both #2 and #3 simultaneously.
One more tiny thing – what if I have more metadata coming from the database? Like created_at, or version or updated_at? I’m not going to go into another long spiel but here’s the beginnings of what that might look like:
data WithMetadata a where
UUIDID :: UUID -> a -> TaskID UUID
IntID :: Int -> a -> TaskID Int
FullMeta :: FullMeta -> a -> TaskID FullMeta
You can imagine that the FullMeta type is one that consists of another GADT (or just a type full of Maybes to keep it simple), with more metadata specified. Anyway, I’m done thinking about this, my head is starting to hurt (I mean not really, it’s actually fun, but this post is getting terribly long and that’s probably a bad sign for the signal/noise ratio). Let’s move on.
Before I move on, the full version of this code (which excludes FullMeta for simplicity) requires two additional language extensions that should be discussed:
GADTs - Needed to use GADTs at allMultiParamTypeClasses - Needed to create the super general typeclass I created for HasSQLID (see the code/commit link below for the full code, it’s pretty different from what’s here)Note that I also had to go back and update the interfaces we were dealing with to reflect where the WithID class should show up. Here’s an example of what this looked like for persistTask:
persistTask :: c -> Validated (FullySpecifiedTask state) -> Either TaskStoreError (WithID (FullySpecifiedTask state))
BTW, if I was down with Dependent types in haskell (or at least the current level of support) (💪 🎩), we could get even more specific about the ID that came back from an operation like getTask and ensure it matched the ID that went in (of course this would require dependent typing all the way down to the DB query level). This is one of the places that they would come in handy.
TaskStoreUp until now all we’ve really done is write fanciful magic types, typeclasses, and abstractions without implementations. Here’s where the rubber hits the road – we’re going to write a type that is a working TaskStoreComponent (remember, this means one that is a Component and furthermore a TaskStore). Of course we’re going to need an actual way to talk to a database at this point, and while my original plan was to walk through in-memory arrays, hashes, and trees as backing stores for our TaskComponent, I’m going to skip straight to SQLite instead.
Haskell has many libraries for high-level abstraction over SQL-compliant databases, and also for dealing with objects at a level higher than SQL (Object Relational Mapping, AKA “ORMs”), which is what we’re about to do. Unfortunately I’m about to ignore ALL the libraries out there that do a great job of solving this problem, and do it the worst yet most straight-forward way I know – raw parametrized SQL queries without even so much as a single query builder to help.
Before we get going, one thing I haven’t covered much but would jump at you while developing this is that we’ve just surfaced another requirement on our TaskComponent’s configuration (and resultingly whatever type it is represented by) – it probably needs to know it’s own state storage location (the FilePath we’re using in this case). This would be a good place to stop and update the configuration-related types we’ve set up in Config.hs, let’s add a TaskStoreConfig that is part of the AppConfig we defined in part 1:
-- ... other code ...
data AppConfig f = AppConfig
{ host :: f Host
, port :: f Port
, taskStoreConfig :: f (TaskStoreConfig f)
}
data TaskStoreConfig f = TaskStoreConfig { tscDBFilePath :: f FilePath }
-- ... other code ...
In addition to just defining TaskStoreConfig and including it in AppConfig, we needed to ensure it was set up to properly be used by the config-reading machinery we’re already using. This is as simple as adding the necessary instances and spending some quality time with the compiler as it lovingly points out everything you’ve done wrong.
-- ... other code ...
type CompleteTaskStoreConfig = TaskStoreConfig Identity
deriving instance Generic CompleteTaskStoreConfig
deriving instance Eq CompleteTaskStoreConfig
deriving instance Show CompleteTaskStoreConfig
deriving instance FromJSON CompleteTaskStoreConfig
type PartialTaskStoreConfig = TaskStoreConfig Maybe
deriving instance Generic PartialTaskStoreConfig
deriving instance Eq PartialTaskStoreConfig
deriving instance Show PartialTaskStoreConfig
deriving instance FromJSON PartialTaskStoreConfig
instance Semigroup CompleteTaskStoreConfig where
a <> b = b
instance Monoid CompleteTaskStoreConfig where
mempty = TaskStoreConfig (Identity defaultTaskStoreFilePath)
instance Semigroup PartialTaskStoreConfig where
a <> b = TaskStoreConfig { tscDBFilePath=resolveMaybes tscDBFilePath }
where
resolveMaybes :: (PartialTaskStoreConfig -> Maybe a) -> Maybe a
resolveMaybes getter = maybe (getter a) Just (getter b)
instance Monoid PartialTaskStoreConfig where
mempty = TaskStoreConfig Nothing
JK, it wasn’t simple – these changes took >10 minutes to sort out – initially it was simple, but the compiler had a bit to say. The first wrinkle was how to distribute the f in AppConfig f – In this case f (TaskStoreConfig f) is the easy and correct choice, because if a task store config is not completely specified, an App store config must not be completely specified. This mean working through a bunch of other instances (mostly copy pasting with slight modification), and some quality time with the compiler. Another thing was I ended up doing refactoring mergePartial into a typeclass called AbsorbPartial partial, due to the need to recursively absorb partials for nested config objects (TaskStoreConfig is inside AppConfig). Check out the commit, it’s gnarly, considering how simple I thought the change would be.
sqlite-simpleWe’re going to be using sqlite-simple to talk to our SQLite database file so after adding it to package.yaml as a dependency for lib and start defining the actual database type in Types.hs:
data SQLiteTaskStore = SQLiteTaskStore
{ stsCfg :: CompleteTaskStoreConfig
, stsConn :: Maybe Connection
}
All we really need is the configuration (which will tell us how to make the connection and any other settings we need), and the actual connection. Of course, when this soon-to-be component is made, the connection won’t be present yet, so I’ve used a Maybe to represent those two cases. Now that we’ve got the type, we can start stubbing out the instances for Component and TaskStore:
instance Component SQLiteTaskStore where
start = undefined
stop = undefined
instance TaskStore SQLiteTaskStore where
persistTask = undefined
completeTask = undefined
getTask = undefined
updateTask = undefined
deleteTask = undefined
Obviously, there are a few issues with some assumptions and code we’ve written so far:
The signature for start actually doesn’t really work out – while in other languages we might have been able to mutate state, in Haskell we can’t, so if we want to create a new SQLiteTaskStore that’s connected (has a Just Connection inside), we need to make a whole new object.
Up until now we haven’t incorporated IO into the definition for a TaskStore at all – basically every time we return something it’s going to be returned from inside an IO context (due to the need to access the database).
As for the issue with the Component c type class definition, let’s introduce another typeclass that captures the quality we want – being able to construct a Component:
class Component c => Constructable c cfg err where
construct :: cfg -> IO (Either err c)
Now, when we try and create a TaskStore at one point, we can connect to the database, and produce a connected one or produce an error detailing why we couldn’t produce one. Another way to solve this problem might have been to modify the Component typeclass directly, I think this separation is good and a little more composable/flexible and explicit in it’s requirement – maybe not every component will have a cfg or an error class.
As for the second issue, we’ll just need to edit the definition of TaskSTore and add more IOs:
class Component c => TaskStore c where
persistTask :: c -> Validated (FullySpecifiedTask state) -> IO (Either TaskStoreError (WithID (FullySpecifiedTask state)))
completeTask :: c -> TaskID -> IO (Either TaskStoreError (WithID CompletedTask))
getTask :: c -> TaskID -> IO (Either TaskStoreError (WithID (FullySpecifiedTask state)))
updateTask :: c -> TaskID -> PartialTask state -> IO (Either TaskStoreError (WithID (FullySpecifiedTask state)))
deleteTask :: c -> TaskID -> IO (Either TaskStoreError (WithID (FullySpecifiedTask state)))
After writing this out, any attempt to start writing persistTask should immediately set off warning bells – even assuming we have a TaskStore with a Just Connection in it we can use, how in the world do we turn a FullySpecifiedTask state into a bunch of params we could use in a INSERT INTO x VALUES (...) DB query? Well the answer requires spending some time with sqlite-simple to figure out how to use it the directions are pretty easy to follow, but let’s skip ahead a bit (feel free to read up on sqlite-simple if you’d like):
import Data.Int (Int64)
import Database.SQLite.Simple (Connection, ToRow(..), FromRow(..), SQLData(..), field)
import Database.SQLite.Simple.FromRow (RowParser)
import Database.SQLite.Simple.ToField (ToField(..))
import Database.SQLite.Simple.FromField (fieldData, ResultError(ConversionFailed), FieldParser, Field, FromField(..), returnError)
--- ... other code ...
newtype TaskName = TaskName { getTName :: DT.Text } deriving (Eq, Show)
deriving instance FromField TaskName
newtype TaskDesc = TaskDesc { getTDesc :: DT.Text } deriving (Eq, Show)
deriving instance FromField TaskDesc
-- ... other code ...
-- | A validated object's ToRow is just the same as it's contained object's ToRow
-- this can probably be auto-derived but let's write it manually for now.
instance ToRow a => ToRow (Validated a) where
toRow = toRow . getValidatedObj
-- | UUIDs need to be converted to text before they can turn into fields
instance ToField UUID where
toField = SQLText . toText
instance ToField TaskState where
toField = SQLText . DT.pack . show
-- | ToRow (WithID a) can be generically performed if we just always put the ID first
-- this introduces the requirement that ids should always come first.
instance ToRow a => ToRow (WithID a) where
toRow (UUIDID id_ obj) = [toField id_] <> toRow (obj)
toRow (Int64ID id_ obj) = [toField id_] <> toRow (obj)
instance ToRow (FullySpecifiedTask TaskState) where
toRow t = toRow (fsTaskName t, fsTaskDesc t, fsTaskState t)
instance FromRow a => FromRow (WithID a) where
-- While normally FromRow instances are written like: `ValueConstructor <$> field <*> field ...`
-- I can't figure out how to cleanly construct and build the partial result using applicatives
-- since I need to pull out the ID, set it aside, then work on the rest, *then* use the right GADT constructor for WithId a
fromRow = field -- pull out first field (we assume it's the ID)
>>= \idSQLData -> fromRow -- parse the rest of the fields into an `a` value
>>= chooseCtor idSQLData -- Given the SQLData, use the right GADT constructor on the id + the `a` value
where
chooseCtor sqldata = case sqldata of
(SQLText txt) -> \obj -> case fromText txt of
Nothing -> throw (ConversionFailed (show sqldata) "Text" "Invalid UUID failed fromText conversion")
Just uuid -> pure $ UUIDID uuid obj
(SQLInteger int) -> \obj -> pure $ Int64ID (fromIntegral int) obj
_ -> throw (ConversionFailed (show sqldata) "???" "Unrecognized contents in ID field (no valid WithID GADT constructor)")
instance FromRow a => FromRow (Identity a) where
fromRow = fromRow
instance FromField a => FromField (Identity a) where
fromField = fromField
instance FromField TaskState where
fromField f = case fieldData f of
SQLText txt -> pure $ read $ DT.unpack txt
fd -> returnError ConversionFailed f "Unexpected TaskState field type"
instance (FromField state) => FromRow (FullySpecifiedTask state) where
fromRow = Task <$> field <*> field <*> field
instance (FromField state) => FromRow (PartialTask state) where
fromRow = Task <$> field <*> field <*> field
Some notes about the code above:
FromRow instance for WithID a was particularly difficult since I couldn’t use the normal applicative method that sqlite-simple lets you use – they did the hard work so I could write something like Task <$> field <*> field <*> ..., and I did the hard work to make sure I couldn’t do that (due to using a compound data type like WithId a and making it a GADT). I tried to write the code as clearly as possible otherwise to offset the complexity.Identity a along the way (sqlite-simple defines one for Maybe a as well).FromField instances for TaskName and TaskDescFromRow instances for FullySpecifiedTask and PartialTask are very easy given that FromField is defined for everythingDeriveAnyClass since I wasn’t sure if there were default implementations for everythingYes, reasoning about and writing all these instances took a while (and I’ve used sqlite-simple before) – don’t be scared away by the amount of code that was necessary. I did made things quite a bit harder for myself by using a GADT (WithID a) and by choosing slightly more complicated data structures (inclusion of f & state in Task f state), but all in all I felt like I understood things as I as going through it step-by-step, but it definitely took at least a few minutes at every compiler to realize where I was mistaken about what I thought was happening versus what the compiler was seeing.
Trying to think objectively about the amount of mental effort expended it might be approach self-inflicted masochism… Good thing I’m not thinking about it too much. A part of me can justify this with the likely fact that if I wasn’t doing the same amount of work in another language it would be because the code I was writing was buggy code that didn’t consider all the cases – or I would have spent this time trying to understand some other library that did the work.
By now it’s pretty obvious but sqlite-simple works by defining and using a whole bunch of instances of things like FromRow and ToRow (similar to aeson), with FromField and ToField as ancillary typeclasses. From what I can tell sqlite-simple doesn’t support generic deriving of the FromRow and ToRow types (like aeson does using GHC.Generics), so I’ve written instances manually. We should have enough to write out to work out a definition for persistTask:
disconnectionError :: IO (Either TaskStoreError a)
disconnectionError = pure $ Left $ Disconnected "Store is disconnected"
makeGenericInsertError :: SomeException -> IO (Either TaskStoreError a)
makeGenericInsertError = pure . Left . UnexpectedError . ("INSERT command failed: " <>) . DT.pack . show
saveAndReturnTask :: ToField state => Connection -> WithID (FullySpecifiedTask state) -> IO (Either TaskStoreError (WithID (FullySpecifiedTask state)))
saveAndReturnTask c t = catch doInsert makeGenericInsertError
where
doInsert = execute c "INSERT INTO tasks (uuid, name, desc, state) VALUES (?,?,?,?)" t
>> pure (Right t)
instance TaskStore SQLiteTaskStore where
persistTask :: SQLiteTaskStore -> Validated (FullySpecifiedTask TaskState) -> IO (Either TaskStoreError (WithID (FullySpecifiedTask TaskState)))
persistTask store (Validated newTask) = maybe disconnectionError _handler $ stsConn store
where
-- | _handler does all the real work of persisting a task
_handler conn = (flip UUIDID newTask <$> nextRandom) -- Use a random UUIDV4 to make a new `WithID (FullySpecifiedTask state)`
-- Insert the task
>>= saveAndReturnTask conn
-- ... other typeclass methods that are *still undefined*
It’s pretty clear that I should start moving this implementation (along with all the ToX/FromX instances) out of Types.hs, so it’s been moved to Components/TaskStore/SQLite.hs, and I turned on InstanceSigs so I could keep the signatures close to the implementation code. A few notes on the implementation:
FullySpecifiedTask state, using TaskState (which is the what we want anyway)Maybe Connection means I need to use the maybe helper method to handle when the connection is missingcatch from Control.Exception so we should be safeNOTE on the gratiuitous use of IO: Other monads and monad stacks exist, and even though IO might not be the right one in the end, there’s no need to worry. We’ll get more abstract in the next post (I’ll give you a hint, this whole component itself is abstractable/generalizable, not just the generous helping of IO) – for now, let’s keep it breezy and make peace with a specification that allows for anything to happen (which is what I imagine when I see IO at least), as long as the results we expect (Either TaskStoreError a) come back. Also keep in mind this popular haskell meme:
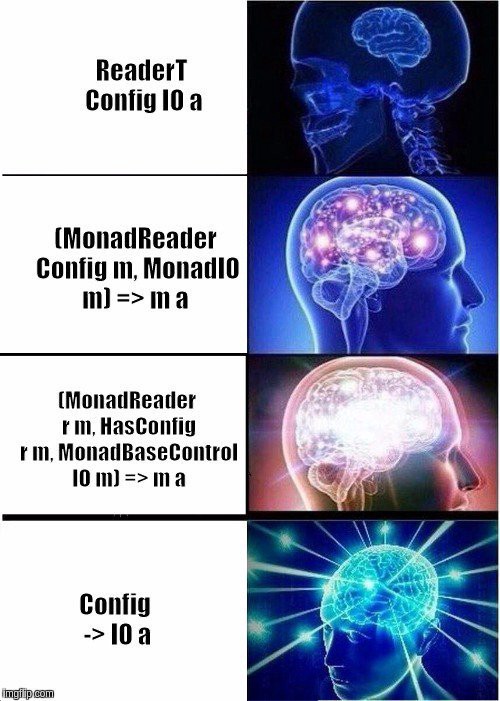
It’s popular meme because there’s a hint of truth – IO is the console.log/println/putStrln of monadic state management; old reliable by your side since day 1. Sometimes it’s easier and more comfortable to just reach for your old friends. We’ll be exploring more of this area in the next post.
At this point things compile but I’m pretty worried about the raw SQL string I’m using there. Other than the fact that it’s a general code smell to just have a string sitting there like that (at the very least we could factor it out so it could be reused), while the query is right there’s a bit of an issue… The query looks right but how do we know the backing SQLite database even has a tasks table?
As with any other language, we need some concept of migrations (or some kind of check at least) to ensure that our program-external database management system is in a consistent state when we start using it! We wrote a query that assumes a table called tasks exists, but it may not exist in the on-disk database’s schema. The easy way to do this is to make sure at SQLiteTaskStore construction time (where we first connect to the database and make our Just Connection), the database is migrated to the version we expect and throws an error otherwise. We can express this requirement on our component with a typeclass:
-- | Holds a database version (expected to be a monotonically increasing number)
newtype SQLMigrationVersion = SQLMigrationVersion { getMigrationVersion :: Int } deriving (Eq, Show, Read)
-- | Holds a SQL Query
newtype SQLMigrationQuery = SQLMigrationQuery { getMigrationQuery :: DT.Text } deriving (Eq, Show, Read)
-- | Specifies a `SQLMigrationVersion` that is the source of a migration path
type FromSQLMigrationVersion = SQLMigrationVersion
-- | Specifies a `SQLMigrationVersion` that is the target of a migration path
type ToSQLMigrationVersion = SQLMigrationVersion
data SQLMigration = SQLMigration
{ smFrom :: FromSQLMigrationVersion
-- ^ The starting migration version
, smTo :: ToSQLMigrationVersion
-- ^ The ending migration version
, smQuery :: SQLMigrationQuery
-- ^ Query to execute to perform the migration (also responsible)
}
data MigrationError = NoMigrationPath -- ^ A path between the migrations could not be found
| MigrationQueryFailed FromSQLMigrationVersion ToSQLMigrationVersion -- ^ An individual migration query failed
deriving (Eq, Show)
class TaskStore store => HasMigratableDB store where
-- | Retreive the desired version, this is normally just statically set @ compile time
desiredVersion :: store -> IO SQLMigrationVersion
-- | A list of available migrations that will be used by `migrateTo` to create a path from current (via `getCurrentVersion`) to `desiredVersion`
availableMigrations :: store -> IO [SQLMigration]
-- | Retrieve the current version of the database
getCurrentVersion :: store -> IO SQLMigrationVersion
-- | Perform migrations to get to the current version
migrate :: SQLiteTaskStore -> IO (Either MigrationError ())
migrate store = desiredVersion store >>= migrateTo store
-- | Finds and executes a path to the requested ToSQLMigration from
-- Currently when looking through `availableMigrations`, a monotonically increasing version number is assumed,
-- This means paths are made from version to version generally in one version increments (1 --[migrateTo]--> 2 --[migrateTo]-> 3)
migrateTo :: store -> ToSQLMigrationVersion -> IO (Either MigrationError ())
You might notice that I just suddenly realized that I absolutely under-utilizing Haskell’s wonderful doc-commenting system. Fintan Halpenny wrote an amazing summary post on some doc coment features that is worth a read, it was a huge eye-opener for me and I’ve kept it bookmarked for moments such as these. At some point I’ll probably go through the whole project and document lots more stuff (I know everyone says it but maybe it will actually happen this time).
We didn’t necessarily have to write this as a typeclass but I personally like the organization effect, if only for ergonomics. When someone defines a HasMigratableSQLDB, they will be defining it for some specific type (in our case SQLiteTaskStore), and can think in those terms, rather than managing a grouping of functions and constants in a file. Either way, here’s a simplistic implementation:
Components/TaskStore/SQLite.hs:
instance FromRow SQLMigrationVersion where
fromRow = fromRow
-- | Helper function for making migration failed errors
makeMigrationFailedError :: SQLMigration -> SomeException -> IO (Either MigrationError a)
makeMigrationFailedError m = pure . Left . MigrationQueryFailed from to . DT.pack . show
where
from = smFrom m
to = smTo m
executeMigration :: Connection -> SQLMigration -> IO (Either MigrationError ())
executeMigration conn m = catch runQuery (makeMigrationFailedError m)
where
query = Query $ getMigrationQuery $ smQuery m
runQuery = withTransaction conn (execute_ conn query)
>> pure (Right ())
-- | Helper function for making `VersionFetchFailed` `MigrationError`s
makeVersionFetchFailedError :: SomeException -> IO (Either MigrationError a)
makeVersionFetchFailedError = pure . Left . VersionFetchFailed . ("Unexpected version fetch failure: " <>) . DT.pack . show
getDBMigrationVersion :: Connection -> IO (Either MigrationError SQLMigrationVersion)
getDBMigrationVersion c = catch runQuery makeVersionFetchFailedError
where
getVersionQuery = Query "PRAGMA user_version;" -- Happens to return 0 if never set before in SQLite
runQuery = query_ c getVersionQuery
>>= \results -> pure $ case results of
[v, _] -> Right v
[] -> Left (VersionFetchFailed "Version retrieval query returned no results")
instance HasMigratableDB SQLiteTaskStore where
desiredVersion :: SQLiteTaskStore -> IO SQLMigrationVersion
desiredVersion _ = pure (SQLMigrationVersion 1)
availableMigrations :: SQLiteTaskStore -> IO [SQLMigration]
availableMigrations _ = pure $ sort migrations
getCurrentVersion :: SQLiteTaskStore -> IO (Either MigrationError SQLMigrationVersion)
getCurrentVersion = maybe _error _handler . stsConn
where
_error = pure $ Left $ VersionFetchFailed "Fetching current version failed"
_handler = getDBMigrationVersion
migrateTo :: SQLiteTaskStore -> ToSQLMigrationVersion -> IO (Either MigrationError ())
migrateTo s expected = maybe unexpectedMigrationErr tryHandler $ stsConn s
where
unexpectedMigrationErr :: IO (Either MigrationError ())
unexpectedMigrationErr = pure $ Left $ UnexpectedMigrationError "Failed to retrieve DB connection"
convertToUnexpectedError :: SomeException -> IO (Either MigrationError ())
convertToUnexpectedError = const $ pure $ Left $ UnexpectedMigrationError ""
tryHandler :: Connection -> IO (Either MigrationError ())
tryHandler conn = catch (handler conn) convertToUnexpectedError
-- | Recursively (!) runs all migrations by
-- There's quite a bit of wasted effort in here, but it's probably good enough (assuming it finishes :)).
handler :: Connection -> IO (Either MigrationError ())
handler conn = availableMigrations s
-- ^ Get the list of current migrations
>>= \usableMigrations -> getCurrentVersion s
-- ^ Get the current version
>>= rightOrThrow
-- ^ Get the current version
>>= \current -> pure (findNextMigration usableMigrations current)
-- ^ Determine the next migration
>>= \case
-- | We're either done or something went wrong
Nothing -> pure $ if current == expected then Right () else Left NoMigrationPath
-- | Perform a single migration then recur
Just m -> executeMigration conn m
>>= rightOrThrow
>> handler conn
-- | We are assuming monotonically increasing version numbers here, and that there exists at least
-- *one* migration between every version (i.e. v1->v2, v2->v3, etc). This is a bad assumption to make generally,
-- but I'm OK with it since this is generally how most people make migrations in my mind, implementation can change later if need be
findNextMigration ms current = find ((current+1==) . smFrom) ms
Components/TaskStore/Migrations/SQlite:
{-# LANGUAGE QuasiQuotes #-}
{-# LANGUAGE OverloadedStrings #-}
module Components.TaskStore.Migrations.SQLite where
import NeatInterpolation (text)
import Types (SQLMigration(..), SQLMigrationQuery(..))
migrations :: [SQLMigration]
migrations =
[SQLMigration
{ smFrom=0
, smTo=1
, smQuery=
SQLMigrationQuery
[text|
CREATE TABLE tasks(
uuid TEXT PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
description TEXT NOT NULL,
status TEXT NOT NULL
);
|]
}
]
Some notes on the code above:
instance shenanigans for the newtype’d SQLMigrationVersion class (it’s just an Int)hlint put me on to the LambdCase language extension which is pretty handyneat-interpolation library that does thisAgain, it’s important to note here that there are many other libraries out there to do migrations on hackage, and some teams are actually more comfortable doing migrations outside the API (middle layer) code itself with libraries like Flyway. The above code is a relatively hastily written, simple implementation showing how you could write migration code yourself, you almost definitely don’t want to use this in production, though in my opinion it’s “good enough”. Database schema migrations can get very complicated very quickly, but usually not due to the machinery above – it’s usually due to the hard-to-see effects of migration code, interdependencies and difficulty in corralling disparate data and semantics that make them difficult, usually migration machinery is set-it-and-forget-it.
OK, we’ve written two pretty big pieces of functionality, and up until now we’ve gone by the the basic “if it compiles it works” philosphy. While that statement is generally true (one of the reasons I love Haskell), Haskell programmers are at their most vulnerable when dealing with the outside world – in this case SQLite – and we should write some tests to make sure we’re not doing things terribly wrong, which will serve to prevent regressions going forward.
Since a test of the TaskStore component is not quite at whole-app level (neither CLI nor HTTP API), I’d categorize the test we’re about to write as an integration test. SQLite makes it pretty easy to do this test since we can use :memory: as the location of our file, which is fantastic for not persisting data across tests – we can even run these tests in parallel, all we have to do is make sure to start completely different object instances (or use one and clear it every time). We’ve only implemented a small bit of the actual API (persistTask), and we’ve just barely gotten a theoretically working migration implementation, so we should be good to at least test that creating and saving one task doesn’t crash and burn.
One problem though – pretty early on into the writing of the tests I realized that I hadn’t actually made the Constructable typeclass instance for SQLiteTaskStore, which means I couldn’t construct one… Here’s the instance I needed:
instance Constructable SQLiteTaskStore CompleteTaskStoreConfig TaskStoreError where
construct :: CompleteTaskStoreConfig -> IO (Either TaskStoreError SQLiteTaskStore)
construct cfg = catch makeStore connectionFailure
where
dbPath :: String
dbPath = show $ runIdentity $ tscDBFilePath cfg
makeStore :: IO (Either TaskStoreError SQLiteTaskStore)
makeStore = open dbPath
>>= \conn -> pure (Right (SQLiteTaskStore cfg (Just conn)))
connectionFailure :: SomeException -> IO (Either TaskStoreError SQLiteTaskStore)
connectionFailure = pure . Left . ConnectionFailure . ("Failed to connect to DB: "<>) . DT.pack . show
Now that we can actually construct a SQLiteTaskStore, let’s get on to testing:
module Components.TaskStore.SQLiteSpec (spec) where
import Components.TaskStore.SQLite (SQLiteTaskStore)
import Types (Constructable(..), HasMigratableDB(..), TaskStore(..), TaskStoreError, SQLMigrationVersion(..))
import Config (defaultCompleteTaskStoreConfig)
import Data.Either (isRight)
import Control.Monad.IO.Class (liftIO)
import Util (rightOrThrow)
import Test.Hspec
makeDefaultStore :: IO (Either TaskStoreError SQLiteTaskStore)
makeDefaultStore = construct defaultCompleteTaskStoreConfig
main :: IO ()
main = hspec spec
spec :: Spec
spec = do
describe "task store creation" $ do
it "works with the default config" $ \_ -> liftIO makeDefaultStore
>>= (`shouldBe` True) . isRight
describe "task store migration" $ do
it "migrates with the default config (0 -> 1)" $ \_ -> liftIO makeDefaultStore
-- Default stores
>>= rightOrThrow
-- migrate migrates to `desiredVersion`
>>= migrate
>>= (`shouldBe` True) . isRight
Trying to run the first test worked out just fine, but my worst fears came true with the second, an error occurred!
getCurrentVersionMy first assumption was that I must have gotten something wrong with the recursive code in migrateTo, but upon closer inspection, sqlite-simple was throwing an unexpected AsyncCancelled that I had never seen before (^C is where I stopped the ghci because it was hung):
*Main Components.TaskStore.SQLiteSpec
λ main
Components.TaskStore.SQLite
task store creation
works with the default config
task store migration
^C
Current version: Left (VersionFetchFailed "Unexpected version fetch failure: AsyncCancelled")
usable migrations: [SQLMigration {smFrom = SQLMigrationVersion {getMigrationVersion = 0}, smTo = SQLMigrationVersion {getMigrationVersion = 1}, smQuery = SQLMigrationQuery {getMigrationQuery = "CREATE TABLE tasks(\n uuid TEXT PRIMARY KEY NOT NULL,\n name TEXT NOT NULL,\n description TEXT NOT NULL,\n status TEXT NOT NULL\n);\n"}}]
Interrupted.
I’d never seen this error before I double checked some other code I’ve written with sqlite-simple and it was was exactly the same, so I started to figure I might have come unto an actual GHC bug. I checked the version of GHC that Stack was using:
$ stack ghc -- --version
And I saw that it was 8.4.3 – which instantly triggered some vague memories of issues with the 8.4.3 GHC release and figured this might be related. What I did was actually to move forward (!!) in LTS Stack resolvers (and resultingly in the GHC release the comes bundled), after taking a look at list of stackage releases on the Stackage home page – I went with resolver: lts-12.18 (in stack.yaml) and re-ran stack build for all the targets I cared about:
$ stack build
$ stack build :int
$ stack build :unit
After a while stack was done re-installing everything, so I went into the GHCI with the :int tag and ran the tests again, and got the same error. At this point, I looked back at the code I had and it’s running on resolver 11.6 so I tried with that instead, and was greeted with a different error:
[4 of 7] Compiling Config ( src/Config.hs, .stack-work/dist/x86_64-linux-ncurses6/Cabal-2.0.1.0/build/Config.o)
/home/mrman/Projects/foss/haskell-restish-todo/src/Config.hs:72:10: error:
Not in scope: type constructor or class ‘Semigroup’
|
72 | instance Semigroup CompleteAppConfig where
| ^^^^^^^^^
/home/mrman/Projects/foss/haskell-restish-todo/src/Config.hs:78:10: error:
Not in scope: type constructor or class ‘Semigroup’
|
78 | instance Semigroup PartialAppConfig where
| ^^^^^^^^^
/home/mrman/Projects/foss/haskell-restish-todo/src/Config.hs:104:10: error:
Not in scope: type constructor or class ‘Semigroup’
|
104 | instance Semigroup CompleteTaskStoreConfig where
| ^^^^^^^^^
/home/mrman/Projects/foss/haskell-restish-todo/src/Config.hs:110:10: error:
Not in scope: type constructor or class ‘Semigroup’
|
110 | instance Semigroup PartialTaskStoreConfig where
| ^^^^^^^^^
Completed 3 action (s).
So the move back presented a few issues:
11.6, Semigroup is not accessible so I had to import it from Data.Semigroup explicitlyData.Monoid imports had to be added as wellFromField for SQLData from a newer version of sqlite-simple had to be copied into my code– I guess the version the revolver was using didn’t have it.After doing all this, the code finally started to build again and I got the same error, but different, and this time it didn’t crash GHCI:
$ stack build :int
haskell-restish-todo-0.1.0.0: test (suite: int)
Components.TaskStore.SQLite
task store creation
works with the default config
task store migration
Current version: Left (VersionFetchFailed "Unexpected version fetch failure: <<loop>>")
... other output ...
migrates with the default config (0 -> 1) FAILED [1]
So good news and bad news here – the ghci isn’t hanging anymore, but I am stil having a problem with querying PRAGMA user_version from the :memory: SQLite DB. Thanks to a Stack Overflow thread on the subject it looks like <<loop>> means that the RTS system detected an endless loop at runtime. Going back and taking a hard look at the code again, this error happens even with the recursive bits commented out:
migrateTo :: SQLiteTaskStore -> ToSQLMigrationVersion -> IO (Either MigrationError ())
migrateTo s expected = maybe unexpectedMigrationErr tryHandler $ stsConn s
where
unexpectedMigrationErr :: IO (Either MigrationError ())
unexpectedMigrationErr = pure $ Left $ UnexpectedMigrationError "Failed to retrieve DB connection"
convertToUnexpectedError :: SomeException -> IO (Either MigrationError ())
convertToUnexpectedError = const $ pure $ Left $ UnexpectedMigrationError ""
tryHandler :: Connection -> IO (Either MigrationError ())
tryHandler conn = catch (handler conn) convertToUnexpectedError
-- | Recursively (!) runs all migrations by
-- There's quite a bit of wasted effort in here, but it's probably good enough (assuming it finishes :)).
handler :: Connection -> IO (Either MigrationError ())
handler conn = availableMigrations s
-- ^ Get the list of current migrations
>>= \usableMigrations -> getCurrentVersion s
>>= \currentVersion -> putStrLn ("Current version: " ++ show currentVersion)
>> putStrLn ("usable migrations:" ++ show usableMigrations)
>> pure (Left (UnexpectedMigrationError "NOPE"))
-- -- ^ Get the current version
-- >>= rightOrThrow
-- -- ^ Get the current version
-- >>= \current -> pure (findNextMigration usableMigrations current)
-- -- ^ Determine the next migration
-- >>= \case
-- -- | We're either done or something went wrong
-- Nothing -> pure $ if current == expected then Right () else Left NoMigrationPath
-- -- | Perform a single migration then recur
-- Just m -> executeMigration conn m
-- >>= rightOrThrow
-- >> handler conn
-- | We are assuming monotonically increasing version numbers here, and that there exists at least
-- *one* migration between every version (i.e. v1->v2, v2->v3, etc). This is a bad assumption to make generally,
-- but I'm OK with it since this is generally how most people make migrations in my mind, implementation can change later if need be
findNextMigration ms current = find ((current+1==) . smFrom) ms
To refresh your memory (since you’re on this bug hunt with me now), this is what getCurrentVersion and the relevant helper methods look like:
getCurrentVersion :: SQLiteTaskStore -> IO (Either MigrationError SQLMigrationVersion)
getCurrentVersion = maybe _error _handler . stsConn
where
_error = pure $ Left $ VersionFetchFailed "Fetching current version failed"
_handler = getDBMigrationVersion
getDBMigrationVersion :: Connection -> IO (Either MigrationError SQLMigrationVersion)
getDBMigrationVersion c = catch runQuery makeVersionFetchFailedError
where
getVersionQuery = Query "PRAGMA user_version;" -- Happens to return 0 if never set before in SQLite
runQuery = (query_ c getVersionQuery :: IO [SQLMigrationVersion])
>>= \results -> pure $ case results of
[v, _] -> Right v
[] -> Left (VersionFetchFailed "Version retrieval query returned no results")
Looks like the loop has to be in here, but weirdly enough, if I remove query_ (and replace it with something like pure (MigrationVersion 0) it works (and doesn’t infinite loop in the recursive bit because that’s commented out)… All of a sudden it hit me – here’s the definition of FromRow for SQLMigrationField:
instance FromRow SQLMigrationVersion where
fromRow = fromRow
Yep, I’m an idiot – this is obviously not an OK definition of FromRow – this is where the infinite loop ghc is running into is! What I needed was:
instance FromRow SQLMigrationVersion where
fromRow = SQLMigrationVersion <$> field
What a dumb thing to do, some part of me thought that somehow ghc was equating the fromRow definition there to the fromRow for Int because SQLMigrationVersion is a newtype. Once I re-ran the weird error was gone:
Progress 1/2: haskell-restish-todo-0.1.0.0
Components.TaskStore.SQLite
task store creation
works with the default config
task store migration
Current version: Right (SQLMigrationVersion {getMigrationVersion = 0})
But wait, since SQLMigrationVersion is a newtype maybe I can just use a standalone deriving instance to get the right answer? Now that I have some working code, I tried deleting the FromRow instance for SQLMigrationVersion and replacing it with a standalone deriving instance:
{-# LANGUAGE StandaloneDeriving #-}
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
-- instance FromRow SQLMigrationVersion where
-- fromRow = SQLMigrationVersion <$> field
deriving instance FromRow SQLMigrationVersion
Weirdly enough GHC spits out this error:
/home/mrman/Projects/foss/haskell-restish-todo/src/Components/TaskStore/SQLite.hs:156:1: error:
• Couldn't match type ‘Int’ with ‘SQLMigrationVersion’
arising from a use of ‘ghc-prim-0.5.1.1:GHC.Prim.coerce’
It can’t figure out that SQLMigrationVersion is actually Int, which is weird, because in my mind GeneralizedNewtypeDeriving was giving us exactly that. Since FromRow is DB implementation specific, it’s not really right to move FromRow to Types.hs and try to do it there… Now that I’ve actually solved the loop issue, I think that might be what was causing the AsyncCancelled error I was seeing – assuming the sqlite-simple version in the newer resolvers does it’s work in an async context, and the async context was crashing when it encountered the bad FromRow instance I wrote. Unfortunately the error is still present after upgrading my resolver version so I’m going to go ahead and leave the instance in there as-is (no deriving for me!).
With this issue taken care of (and all the dumb infinitely loop instances I wrote removed), we can get back to actually trying to test the migration functionality.
OK, with everything back to normal, let’s see what the migration test returns:
Components.TaskStore.SQLite
task store creation
works with the default config
task store migration
migrates with the default config (0 -> 1) FAILED [1]
Failures:
/home/mrman/Projects/foss/haskell-restish-todo/test/Integration/Components/TaskStore/SQLiteSpec.hs:30:70:
1) Components.TaskStore.SQLite, task store migration, migrates with the default config (0 -> 1)
expected: Right ()
but got: Left (UnexpectedMigrationError "src/Components/TaskStore/SQLite.hs:(174,41)-(176,119): Non-exhaustive patterns in case\n")
Good news/bad news:
Non exhaustive case errors like this are never supposed to happen in Haskell. The offending case is:
>>= \results -> pure $ case results of
[v, _] -> Right v
[] -> Left (VersionFetchFailed "Version retrieval query returned no results")
Welp, it’s a bit obvious that the only case I didn’t cover here was the case I actually care about – the [v] case! I mixed up the syntax as well, here’s the fixed version:
>>= \results -> pure $ case results of
(v:_) -> Right v
_ -> Left (VersionFetchFailed "Version retrieval query returned no results")
With this out of the way, let’s run it again!
Failures:
/home/mrman/Projects/foss/haskell-restish-todo/test/Integration/Components/TaskStore/SQLiteSpec.hs:30:70:
1) Components.TaskStore.SQLite, task store migration, migrates with the default config (0 -> 1)
expected: Right ()
but got: Left NoMigrationPath
Oh no, looks like my shitty algorithm can’t find a migration path from 0 to 1, with only one migration in there…
Looksl ike the logic was quick, dirty, and wrong – weirdly enough the issue was actually in the simplest function – determining whether there is a next step. Here’s teh definition:
findNextMigration ms current = find ((current+1==) . smFrom) ms
Can you see what’s wrong? Well it’s pretty obvious now, but smFrom should at least be an smTo – we want to know that the next migration goes to current + 1, not that it goes from current + 1. I beefed up the assumption a little bit and fixed it:
isNextStep current migration = smFrom migration == current && smTo migration == current + 1
findNextMigration migrations current = find (isNextStep current) migrations
When I run it again, I get:
Failures:
/home/mrman/Projects/foss/haskell-restish-todo/test/Integration/Components/TaskStore/SQLiteSpec.hs:30:70:
1) Components.TaskStore.SQLite, task store migration, migrates with the default config (0 -> 1)
expected: Right ()
but got: Left (UnexpectedMigrationError "MigrationQueryFailed (SQLMigrationVersion {getMigrationVersion = 0}) (SQLMigrationVersion {getMigrationVersion = 1}) \"SQLite3 returned ErrorError while attempting to perform prepare \\\"CREATE TABLE tasks(\\\\n uuid TEXT PRIMARY KEY NOT NULL,\\\\n name TEXT NOT NULL,\\\\n description TEXT NOT NULL,\\\\n status TEXT NOT NULL\\\\n);\\\\n\\\": table tasks already exists\"")
Which is much better since the migration is being run at all, but stil obviously an issue since the query is failing.
tasks tableAs you can see from the previous error output, table tasks already exists – which is ridiculous, because I’m working on an in-memory database (:memory:), that should be empty. Realistically the only way this would happen is if I migrated twice, or if my migration logic had an infinite loop. We can rule out the infinite loop case since the MigrationQueryFailed error gives us the versions it was trying to migrate from and to (MigrationQueryFailed (SQLMigrationVersion {getMigrationVersion = 0}) (SQLMigrationVersion {getMigrationVersion = 1}) means that we were going from 0 -> 1).
After a few seconds of headscratching, I realized the problem – I never added code to update PRAGMA user_version! Another boneheaded move! In particular, I should have been calling PRAGMA user_version = <update version> after every successful migration! Here’s the updated code:
executeMigration :: Connection -> SQLMigration -> IO (Either MigrationError ())
executeMigration conn m = catch runQuery (makeMigrationFailedError m)
where
migrationQuery = Query $ getMigrationQuery $ smQuery m
versionUpdateQuery = Query $ ("PRAGMA user_version = " <>) . DT.pack . show $ getMigrationVersion $ smTo m
migrateAndUpdateVersion = execute_ conn migrationQuery
>> execute_ conn versionUpdateQuery
runQuery = withTransaction conn migrateAndUpdateVersion
>> pure (Right ())
After that fix, all is well:
*Main Components.TaskStore.SQLiteSpec
λ main
Components.TaskStore.SQLite
task store creation
works with the default config
task store migration
migrates with the default config (0 -> 1)
Finished in 0.0021 seconds
2 examples, 0 failures
Now I can add one more test, to make sure that we can persist a task without failing:
-- generateTask :: IO (Validated NotStartedTask)
generateTask :: IO (Validated (Task Identity TaskState))
generateTask = rightOrThrow $ validate $ Task { tName = Identity $ TaskName "example"
, tDescription = Identity $ TaskDesc "this is a example task"
, tState = Identity NotStarted
}
describe "task store persistTask" $ do
it "works with default config" $ \_ -> liftIO makeDefaultStore
>>= rightOrThrow
>>= \store -> migrate store
>> generateTask
>>= \expected -> persistTask store expected
>>= rightOrThrow
-- | Ensure that the ID is non-empty when printed, and the object we got back is right
>>= \actualWithID -> pure (showID actualWithID /= "" && withoutID actualWithID == getValidatedObj expected)
>>= shouldBe True
You might be wondering why generateTask has the signature IO (Validated (Task Identity TaskState) and not IO (Validated NotStartedTask) – well that signature would be more ergonomic but there’s a problem – GHC can’t tell that Validated NotStartedTask (expanded, Validated (Task Identity NotStarted)) is the *same thing as a Task Identity TaskState, since TaskState can be multiple values. To restate, once persistTask returns us an object, we don’t know what state it’s going to be in when it comes back from the database! Remember, we actually abstract over TaskState all over persistTask (which allows us to accept pre-completed or in-progress tasks as they are):
persistTask :: c -> Validated (FullySpecifiedTask TaskState) -> IO (Either TaskStoreError (WithID (FullySpecifiedTask TaskState)))
I had to add some instances but all in all, the test is what we want. As you might have expected at this point, when we run it, it fails:
Failures:
/home/mrman/Projects/foss/haskell-restish-todo/test/Integration/Components/TaskStore/SQLiteSpec.hs:58:10:
1) Components.TaskStore.SQLite, task store persistTask, works with default config
uncaught exception: TaskStoreError
UnexpectedError "INSERT command failed: SQLite3 returned ErrorError while attempting to perform prepare \"INSERT INTO tasks (uuid, name, desc, state) VALUES (?,?,?,?)\": table tasks has no column named desc"
Looks like I’ve missnamed a column (description to be precise). Easily enough I can change the query and make sure it matches with the migration:
saveAndReturnTask :: ToField state => Connection -> WithID (FullySpecifiedTask state) -> IO (Either TaskStoreError (WithID (FullySpecifiedTask state)))
saveAndReturnTask c t = catch doInsert makeGenericInsertError
where
doInsert = execute c "INSERT INTO tasks (uuid, name, desc, state) VALUES (?,?,?,?)" t
>> pure (Right t)
(yes, I know this sucks and is very abstractable/fixable – the next post will cover how to make this better)
While we’re there, I also misnamed the status column in the SQLite migration so I’ve fixed that as well. After fixing those issues and rerunning it, we get… a successful test run! Looks like persist task is indeed doing to the database and back and bringing us back what we put in, with an ID!
I really want to keep the ability to specify a tasks completion directly (by using types like CompletedTask, but it looks like have to re-work how to represent this, or figure out a way to tell the compiler that these two types are identical.
This section got way longer than I expected, but hopefully you got a good loook at my amateur debugging up close and weren’t too turned off by the issues I ran to. The bugs in my code were pretty silly – writing nonsensical instances, a non-exhaustive case (which I’m still a little surprised Haskell allowed me to do in the first place), and forgetting to update the version in the database itself.
Now we have a working test for the two big pieces so far we implemented – migrations and persistTask! To run the tests we can run:
$ stack build && stack test :unit :int
.. other output ...
haskell-restish-todo-0.1.0.0: test (suite: int)
Components.TaskStore.SQLite
task store creation
works with the default config
task store migration
migrates with the default config (0 -> 1)
task store persistTask
works with default config
Finished in 0.0011 seconds
3 examples, 0 failures
haskell-restish-todo-0.1.0.0: Test suite int passed
haskell-restish-todo-0.1.0.0: test (suite: unit)
Config
defaults
has localhost as the default host
has 5000 as the default port
default values
CompleteAppConfig has default host
CompleteAppConfig has default port
PartialAppConfig has no default host
PartialAppconfig has no default port
Finished in 0.0008 seconds
6 examples, 0 failures
haskell-restish-todo-0.1.0.0: Test suite unit passed
TaskStore methods?I’m actually going ot skip the rest of the implementation (and you should too), becasue we’re going to actually generalize TaskStore next time, into an EntityStore. With the contents of this post, you should be able to imagine just how to write the implementations for completeTask, getTask, and updateTask, but it would suck to actually do, because we’d be writing very very Task-specific queries, when we’re going to have some other models in our domain. The next post will go into how we can generalize our TaskStore into an EntitySTore and write these functions (except for completeTask` of course, exactly once for domain models moving forward.
The code is posted up on Gitlab w/ the part-2 tag for your perusing pleasure. Note that it’s incomplete as it’s missing implementations for methods like completeTask, but don’t bother with them – we’re going to further generalize and abstract an EntityStore out of our TaskStore in the next post. persistTask should show the general flow, if you get the itch to write some code yourself.
Hopefully this post has been a decent practical guide to writing/modeling domains in Haskell and made it less daunting! While a lot of the methods used (like the migration strategy) are a bit questionable to use in production, they at the very least work reliably and are pretty well specified. We went a bit crazy with types this post and caused a bit of complications (defining instances, figuring out implementations) but again I want to remind everyone that you can ignore vast swaths of the advanced typing approaches until you’re ready, I tried to show the progression and decision making process I go through when I try to use the power Haskell offers. You can Get Stuff Done (tm) with Haskell without any of the advanced type stuff, and still enjoy the benefits of haskell on a simpler level.
Just to reassure everyone, we haven’t veered too far off course – the steps put forth in this post continue to represent the first steps of getting a decently architected REST-ish webservice up and running (domain models are important), but there is lots of tools out there that will get you much further than this much faster (ex. Postgrest, yesod, and in other languages, frameworks like Rails or Django), but if you are interested in building the internals at a lower level, hoping to have less batteries included and (hopefully) a better understanding of what’s happening, hopefully you’ve picked up a trick or two.
The next entry in this post is going to get hot and heavy in a hurry – believe it or not there’s a lot of abstraction at various levels and streamlining of the logic that has been left out in this one, along with the actual use of servant to serve HTTP or hooking up our domain TaskStore component to anything. The next post will focus on those things, generalizing, and we’ll get to making the actual API, finally!
In the earliest sections, we created a Task type that was parametrized over two values – f for completeness (using Identity vs Maybe as f), and state for task completion status (the TaskStatus GADT and associated types). The point of doing this for me was to be able to differentiate a case like a partial record of a completed task (Task Maybe Finished) versus a fully specified incomplete task (Task Identity NotStarted). While the amount of benefit of adding the second parametrization, state, is questionable, I thought at least the partial/completely specified record distinction was interesting.
After sharing this post on Reddit, a few suggestions were made on how to clean up this code. While I’m not sure all of them are the way to go, they do deserve sharing, so here they are.
u/blamario suggested the use of Rank2classes or Conkin. This offers a TemplateHaskell approach to automating the generation of the usual typeclasses surrounding a record type (Functor, Applicative, Foldable, etc) without writing them myself, to make it easier to interoperably use the types. Put another way, from what I understand rank2classes will make it much easier to write code that deals f and state (in Task f state) abstractly. the documentation for rank2classes is excellent and contains a better more in-depth description.
Conkin provides a similar solution and has similarly great and detailed documentation, check it out.
u/blamario provided a pretty in-depth description of how these types would be useful so please feel free to check that out as well.
DataKindsu/Tarmen brought suggesting using the DataKinds extension (along with a detailed explanation, including one using type families thanks u/Tarmen!), I agreed that it might just be the concept to help simplify the Task f state definitions. Kinds as a concept (in haskell) and use of the DataKinds extension in my own code are somewhat new to me but I also found an excellent primer on the subject to re-enforce what I thought I already knew.
I personally liked this suggestion the most because it was minimally invasive syntax and project (dependency) wise. I’m in the process of reading up and trying to better understand.
NOTE - Definitely check out the primer I linked to earlier – outside of being an excellent post, the section on datatype promotion is extremely relevant and well explained.
KindSignaturesu/sjakobi suggested using the KindSignatures language extension to be more explicit about the Kinds that were being used. This suggestion was made separately but works well with the suggestion to use the DataKinds extension. The example provided by (u/sjakobi) was pretty explanatory:
{-# LANGUAGE KindSignatures #-}
data Task (f :: * -> *) = Task ...
type Partial (f :: (* -> *) -> *) = f Maybe
As you can see, the KindSigntaures extension allows you to be more explicit about the kind level action going on. I do not have the deep understanding to try and explain Haskell’s kind system (and any attempt would have made this post even longer) but the primer I linked to earlier in this section is a pretty great read.