DDG search drop in powered by ddg.patdryburgh.com
tl;dr - I over-engineered a script to run a small experiment to figure out what was the right cluster size for PM2 in various CPU + RAM configurations. Turns out having lots of PM2 instances is really good when there’s not much memory and only slightly bad when there is sufficient memory, so a blanket recommendation like 32 actually works out. The code is on Gitlab – you can skip to the results.
pm2 is one of (if not the) most popular process manager that is used with NodeJS. If you’re not familiar, similar to Python and Ruby, NodeJS required the use of subprocesses to scale (this has recently changed with worker threads becoming available). Unlike Python and Ruby, NodeJS was never held back by the issues presented by having a Global Interpreter Lock (GIL), but it did not have a story for system threading per-say, as the cluster module is more akin to spawning and coordinating child processes in Python/Ruby though it is a bit more purpose-built since NodeJS lets the processes share ports.
Note: NodeJS is known for it’s concurrency, that is not the same as parallelism (see the famous Concurrency is not Parallelism talk by Rob Pike for a refresher if you need to)
While concurrency and parallelism implementations differ from language to language, the basics are the same in every language. Languages generally make use of concurrency with kernel primitives like select, epoll, BSD’s kqueue and more recently io_uring and deal with system threads and related management manually or via some libraries (usually pthread which supplies POSIX compliant processes). This talk won’t be very technical on the lower levels but I do want to note that I will be very Linux focused. Generally, since CPUs with simultaneous multithreading (SMT) capability (ex. Intel’s hyper threads) can only do so much at a time, you’d expect the maximal amount of worker threads for a given program to be # of hyper threads. This should be the number that maximally uses all the threads of execution available to a given CPU, and no matter what you do with them (ex. run asynchronous code above), you’re constrained by the number of CPUs/hyper threads.
pm2 on HerokuA simple understanidng of the base case is what lead to some confusion recently – while working with pm2 on Heroku, I ran into some documentation that seems to suggest that 28 cluster workers is the appropriate size for a Performance L instance. Is Heroku providing 14 cores with every Performance L instance? Looking at their documentation doesn’t really help, since the “compute” column is relative and in terms of CPU (time) share (which I’m not sure is actual linux CPU (time) shares), and even when we look at the dedicated compute instances (Performance M and L), they list “12x” and “50x” compute.
A cursory search surfaces a bit more information on Stack Overflow, and it looks like concensus is that Performance M provides 2 dedicated “cores” (I assume 4 hyper threads) and Performance L provides 8 dedicated “cores” (16 hyper threads??). It’s a bit weird – if we’re talking about hyper threads that means a Performance M is only one dedicated core, so I have to assume that means the number is actual cores. Performance L providing 8 dedicated cores is quite a big jump. The alternative is to assume that /proc/cpuinfo is outputting logical cores, which means that a Performance M is one dedicated physical CPU core and Performance L is 4. It’s not news that Heroku is considered overpriced by some (me included), but it’s a still bit puzzling that with this knowledge they’d suggest 28 cluster workers for a performance L machine.
Regardless of how many cores are available, 28 still seems like way too many instances – we know that NodeJS is extremely IO efficient due to it’s asynchronous nature, so is it that it takes this many workers to fully cause a process to be CPU bound? But what happens when one of these workers gets involved in some very tough CPU work, are the rest starved? Normally you’d expect cluster worker per hyper thread (like NGINX’s approach to solving the C10K problem).
Basically, more cores per worker could be good if there is more CPU bound work to be done while IO bound work is waiting, and it could be bad if the context switching burden to start doing any work overtakes the actual work to be done. Only way to definitively find out is to test, so let’s do it.
Why would Haskell come up in a post about Javascript? Well it turns out that Haskell does this really well – one of the best explanatory illustrations was in an SO answer:
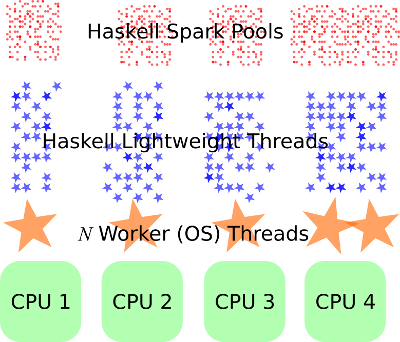
Anyway, that’s enough about Haskell – it’s RTS system has lots of advantages but they’re not the current focus. Haskell is a good example of the fundamentals laid out somewhere else.
So of course, all that’s left is to figure out whether this prescription is right or not! There are lots of different types of applications but we’re going to be concerned most with web-service-y things. There are a few things we can think of having this server do:
In the interest of time I’m only going to do some dummy JSON, since it’s at least a little harder than just returning static text. Let’s test three different scenarios:
dummy-json: Generating and returning JSON using dummy-jsonprepared-dummy-json-random-read: Pre-generate lots of dummy JSON to a local temporary folder with random names, read them back a random one from disk (randomly)gen-dummy-json-write: generate dummy JSON on the fly, write it to a file then return the result (and run something in the background to remove the file)I won’t get into much here but I ended up using commander since I wanted to be able to setup and and run the benchmarks as a command line script (and I could see myself using it in the future). The simplest way to do this would probably have been just running something (ex. node app.js) and using a tool like vegeta or locust to test it and recording the results manually, but I love yak shaving meaningful automation. This means I’ve ended up with a fully functioning command line application, linting, tests, code coverage and all.
One of the first important things to do is figure out what information I need to perform a single run:
export enum SupportedAppName {
Simple = "simple",
}
export enum SupportedClientName {
Simple = "simple",
}
// Configuration for many benchmarks that is used to generate individual runs
export interface BenchmarkDimensionsConfig {
cpuMillicores: number[],
ramMB: number[],
clients: SupportedClientName[],
apps: SupportedAppName[],
pm2Instances: number[],
}
// Configuration for a single benchmark run
export interface BenchmarkRunConfig {
cpuMillicores: number,
ramMB: number,
client: SupportedClientName,
app: SupportedAppName,
pm2InstanceCount: number,
}
Basically, these represent all the axes that that I’ll need to run tests over – there are a lot of them but they should be pretty self-explanatory. I’ll explain anyway:
cpuMillicores - the amount of underlying CPU for the platform (VM/container/etc), expressed in millicores to make it easier to splice upramMB - the amount of underlying RAM that will be available to the platform (VM/container/etc), expressed in MBclients - the kind of client logic that will be tested (ex. "simple" might represent a simple GET request being done repeatedlyapps - the kind of server logic that will be tested (ex. "simple" might have only one endpoint, which is a simple GET)pm2Instances - the number of instances that will be set with PM2Before we get started setting up the components which will run this show, let’s set up some basic premises:
export interface Component {
// Provision resources and perform any setup to run tests
init(): Promise<this>;
// Initialize configuration of a benchmark output recorder
cleanup(): Promise<this>;
}
So now we can get along to writing the components that will use the data and interfaces above!
Provisioner interface - creating application instances flexiblyOne thing that was important was being able to run these tests locally and remotely – how things run on your machine are very different from how they’ll run in production. I accomplished this by introducing configuration around deployment, in particular introducing the idea of “driver"s. First here’s the basic configuration for a driver:
export interface BenchmarkProvisionerConfig {
driver: BenchmarkProvisionerName; // The driver to use when deploying the test application
config?: any; // Bag of configuration to pass to the driver
}
And here’s the interface for a BenchmarkProvisioner:
// Provisioners that are capable of provisioning some compute and memory for performing a benchmark run
export interface BenchmarkProvisioner extends Component {
// Provision an application for benchmarking a particular configuration
provision(benchmarkConfig: BenchmarkRunConfig): Promise<AppInstanceInfo>;
// Teardown an instance
teardown(info: AppInstanceInfo): Promise<this>;
}
My immediate thought was to implement two:
docker locally)Pod)If you want to check out the source code for both of these, check the repository.
Runner interface - running clients to generate load flexiblyAfter we’ve provisioned some resources to run tests on, we’ll need to actually run the tests. I’ve settled on autocannon since it seems to be relatively high quality, easy to natively use from NodeJS and is pretty simple. As I want to leave space for supporting various kinds of runners, (for example one that uses scripts with playwright or puppeteer), I’m leaving some space open for flexibility here. The basic configuration for a Runner is very much like a Driver:
export interface BenchmarkRunnerConfig {
type: BenchmarkRunnerType; // The runner to use when deploying the test application
extra?: any; // Bag of "extra" configuration to pass to the runner
}
And the interface is extremely simple:
export interface BenchmarkRunner extends Component {
// Run a single test
run(benchmarkInstanceInfo: AppInstanceInfo): Promise<any>;
}
Recorder interface - Saving resutls to local files and S3Another thing that was a nice to have I couldn’t help implementing was some flexibility around how to record results – I wanted in particular to be able to save results in two places:
Here’s what the interface for the configuration looks like:
export interface BenchmarkOutputConfig {
directory: string; // The direcotry into which the benchmark results will be placed
format: BenchmarkOutputFormatName; // Output format to use
}
And here’s what the OutputRecorder looks like:
export interface BenchmarkConfigAndOutput<T> {
cfg: BenchmarkDimensionsConfig;
output: T;
}
// OutputRecorders are capable of writing the output of a given run to a certain place
// while we don't know what the output is, it is up to the recorder to try to figure it out
// and throw errors if it can't handle the content (or handle content it knows specially)
export interface BenchmarkOutputRecorder<T> {
// Initialize configuration of a benchmark output recorder
init(cfg: BenchmarkOutputConfig): Promise<T>;
// Record one or more benchmark
record(configAndOutputs: BenchmarkConfigAndOutput<T>[]): Promise<BenchmarkConfigAndOutput<T>[]>
// Initialize configuration of a benchmark output recorder
cleanup(cfg: BenchmarkOutputConfig): Promise<T>;
}
I’m still not sure exactly what I want the output to look like but I’ll have to figure that out soon.
docker#First step is to get things working locally using docker. With containerd inside, docker gives us easy control over the resources required by a container, and thus we can use it to easily limit the test runs. While we could use something like dockerode, I’m going to stick with simple subprocesses (i.e. running docker with child_process.spawn). I won’t go into all the code required here, but you can look at the gory details in the GitLab repository.
Here’s the general gist of the important bit:
// Generate container name and host port
const containerName = `pm2-benchmark-${RandomString.generate(7)}`;
const hostPort = await getPort();
this.logger.debug(`Using container [${containerName}] @ host port [${hostPort}]`);
// Gather arguments for docker to use
const args: string[] = [
"run",
"--detach",
"--publish", `${hostPort}:${DEFAULT_CONTAINER_INTERNAL_PORT}`,
"--env", `PM2_INSTANCE_COUNT=${benchmark.pm2InstanceCount}`,
"--cpus", `${benchmark.cpuMillicores / 1000}`,
"--memory", `${benchmark.ramMB}mb`,
"--name", containerName,
dockerImageName,
];
// Start the docker container for the run
this.logger.debug(`Running docker with arguments:\n${JSON.stringify(args, null, ' ')}`);
let output: any;
try {
output = await execAsync(`${dockerBinPath} ${args.join(" ")}`);
} catch (err) {
// Print notice about delegation of CPU
if (err && err.code === 125 && err.stderr && err.stderr.includes("kernel does not support CPU CFS scheduler")) {
this.logger.warn("CGroups not properly enabled/delegated (see https://wiki.archlinux.org/index.php/Cgroups#User_Delegation)");
this.logger.warn("to check, run `cat /sys/fs/cgroup/user.slice/user-1000.slice/cgroup.controllers` and ensure 'cpuset cpu and io' are printed")
}
throw err;
}
I put lots of abstraction around this bit but in the end the important thing is to just run the docker binary with some options that represent the parameters for the test run to it.
And here’s what the output of a run looks like (lots of abstraction between the snippet above and a Here’s a look at what a test run looks like:
yarn benchmark run --config ./2C-16GB-simple.config.json
yarn run v1.22.10
$ node dist/src/benchmark.js run --config ./2C-16GB-simple.config.json
[info] [2021-02-10T06:48:04.863Z] [benchmark] running...
[info] [2021-02-10T06:48:04.865Z] [benchmark] Loading and parsing JSON config from [./2C-16GB-simple.config.json]...
[info] [2021-02-10T06:48:04.867Z] [benchmark] Generated [12] benchmark run configurations
[info] [2021-02-10T06:48:04.867Z] [benchmark] Preparing output recorder...
[info] [2021-02-10T06:48:04.873Z] [output-recorder] Successfully initialized local recorder
[info] [2021-02-10T06:48:04.873Z] [benchmark] Preparing provisioner...
[info] [2021-02-10T06:48:04.873Z] [provisioner-docker] Successfully initialized
[info] [2021-02-10T06:48:04.873Z] [benchmark] Preparing benchmark runner...
[info] [2021-02-10T06:48:04.873Z] [runner-autocannon] Initializing AutoCannon runner...
[info] [2021-02-10T06:48:04.873Z] [runner-autocannon] Successfully initialized
[info] [2021-02-10T06:48:04.874Z] [benchmark] Running benchmarks...
[info] [2021-02-10T06:48:04.874Z] [benchmark] Running benchmark [1 / 12]...
[info] [2021-02-10T06:48:17.702Z] [benchmark] successfully recorded results @ [file://./results/local/CPUM_2000-MB_RAM_4096-client_simple-app_simple-pm2_instances_4/results.data.json]
[info] [2021-02-10T06:48:17.703Z] [provisioner-docker] Stopping container [pm2-benchmark-SwLI0Zv]
[info] [2021-02-10T06:48:18.291Z] [provisioner-docker] Removing container [pm2-benchmark-SwLI0Zv]
[info] [2021-02-10T06:48:18.364Z] [benchmark] Running benchmark [2 / 12]...
[info] [2021-02-10T06:48:33.718Z] [benchmark] successfully recorded results @ [file://./results/local/CPUM_2000-MB_RAM_4096-client_simple-app_simple-pm2_instances_8/results.data.json]
[info] [2021-02-10T06:48:33.718Z] [provisioner-docker] Stopping container [pm2-benchmark-cctfXBF]
[info] [2021-02-10T06:48:34.129Z] [provisioner-docker] Removing container [pm2-benchmark-cctfXBF]
[info] [2021-02-10T06:48:34.201Z] [benchmark] Running benchmark [3 / 12]...
[info] [2021-02-10T06:48:48.563Z] [benchmark] successfully recorded results @ [file://./results/local/CPUM_2000-MB_RAM_4096-client_simple-app_simple-pm2_instances_16/results.data.json]
... more output ...
Since I happen to have a Kubernetes cluster handy, this is the easiest way that I can run this build remotely and get a sense for “real-internet” delays and quirks.
Deploying to Kubernetes is pretty easy once you’ve got a gist of it – what we need here is a bunch of ephemeral Deployments that will run and absorb traffic. Basically instead of calling docker we’re going to be calling kubectl. This time instead of showing you all the code, here’s just the chunk that builds the appropriate JSON for a Deployment:
protected async generatePodJSON(info: KubernetesResourceInfo): Promise<object> {
const imagePullSecrets = [];
if (info.imagePullSecret) {
imagePullSecrets.push({ name: info.imagePullSecret });
}
if (!info.benchmark) {
throw new Error("benchmark run config missing while generating Pod JSON");
}
return {
apiVersion: "apps/v1",
kind: "Deployment",
metadata: {
name: info.name,
namespace: info.namespace,
},
spec: {
replicas: 1,
selector: {
matchLabels: {
app: info.appTag,
}
},
template: {
metadata: {
labels: {
app: info.appTag,
}
},
spec: {
imagePullSecrets,
containers: [
{
name: "app",
image: info.imageName,
imagePullPolicy: "IfNotPresent",
ports: [
{ containerPort: info.containerPort },
],
resources: {
limits: {
cpu: `${info.benchmark.cpuMillicores}m`,
memory: `${info.benchmark.ramMB}Mi`,
},
requests: {
cpu: `${info.benchmark.cpuMillicores}m`,
memory: `${info.benchmark.ramMB}Mi`,
}
},
env: [
{ name: "PM2_INSTANCE_COUNT", value: `${info.pm2InstanceCount}` },
]
},
]
}
}
}
};
}
One thing that we do have to worry about is specifying an image for every SupportedAppName that we plan to use during the test. We need to maintain a mapping of the app names to docker images that embody their behavior.
The behavior we’re aiming fo is pretty simple:
Deployment to match a BenchmarkDimensionsConfigDeployment (via kubectl apply)DeploymentI won’t get into it too much more here, but if you check out the code, it does what you’d expect in a pretty predictable way.
As you might expect, a test run for the kubernetes provisioner looks very similar to the one for the docker provisioner, with slightly different log messages:
yarn benchmark run --config ./2C-16GB-simple.k8s.config.json
yarn run v1.22.10
$ node dist/src/benchmark.js run --config ./2C-16GB-simple.k8s.config.json
[info] [2021-02-10T06:51:05.404Z] [benchmark] running...
[info] [2021-02-10T06:51:05.407Z] [benchmark] Loading and parsing JSON config from [./2C-16GB-simple.k8s.config.json]...
[info] [2021-02-10T06:51:05.409Z] [benchmark] Generated [12] benchmark run configurations
[info] [2021-02-10T06:51:05.409Z] [benchmark] Preparing output recorder...
[info] [2021-02-10T06:51:05.415Z] [output-recorder] Successfully initialized local recorder
[info] [2021-02-10T06:51:05.415Z] [benchmark] Preparing provisioner...
[info] [2021-02-10T06:51:05.415Z] [provisioner-k8s] Successfully initialized
[info] [2021-02-10T06:51:05.415Z] [benchmark] Preparing benchmark runner...
[info] [2021-02-10T06:51:05.415Z] [runner-autocannon] Initializing AutoCannon runner...
[info] [2021-02-10T06:51:05.415Z] [runner-autocannon] Successfully initialized
[info] [2021-02-10T06:51:05.415Z] [benchmark] Running benchmarks...
[info] [2021-02-10T06:51:05.415Z] [benchmark] Running benchmark [1 / 12]...
[info] [2021-02-10T06:51:14.218Z] [provisioner-k8s] Finished setting up pod [pm2-benchmark-w1q4wry] exposed by svc [pm2-benchmark-w1q4wry] and ingress [pm2-benchmark-w1q4wry]
[info] [2021-02-10T06:51:25.738Z] [benchmark] successfully recorded results @ [file://./results/k8s/CPUM_2000-MB_RAM_4096-client_simple-app_simple-pm2_instances_4/results.data.json]
[info] [2021-02-10T06:51:30.427Z] [benchmark] Running benchmark [2 / 12]...
[info] [2021-02-10T06:51:37.813Z] [provisioner-k8s] Finished setting up pod [pm2-benchmark-dlmzddy] exposed by svc [pm2-benchmark-dlmzddy] and ingress [pm2-benchmark-dlmzddy]
[info] [2021-02-10T06:51:49.244Z] [benchmark] successfully recorded results @ [file://./results/k8s/CPUM_2000-MB_RAM_4096-client_simple-app_simple-pm2_instances_8/results.data.json]
... more output ...
If you read the whole post up until this point, you are to be commended! If you didn’t that’s OK too, because I’m going to get to the juicy part right now:
With this test configuration:
{
"recorder": {
"directory": "file://./results/local",
"format": "json"
},
"provisioner": {
"type": "local-docker-binary"
},
"runner": {
"type": "autocannon"
},
"dimensions": {
"cpuMillicores": [
2000
],
"ramMB": [
4096,
8192,
16384
],
"clients": [ "simple" ],
"apps": [ "simple" ],
"pm2InstanceCounts": [
4,
8,
16,
32
]
}
}
Here are the graphs from the combinations generated by the config above, that focus on p99 latency. Early on I focused on total requests per second and that was a bad idea, since I was hitting the top of what autocannon was configured to attempt – remember that lower is better:



In general it looks like we’ve got much lower latencies when running with 8 instances – 4x the number of cores. 8 instances did really well across various RAM restrictions, and while it’s not clear why 8 did that much better, we can at least say that 32 isn’t doing much to help, it’s consistently the worst performer. There looks to be a sweet spot around 8 instances to 2 cores here, and a clear drop off a the top end (16 instances and 32).
Let’s take that same configuration and change it into one that works with the Kubernetes runner:
{
"recorder": {
"directory": "file://./results/k8s",
"format": "json"
},
"provisioner": {
"type": "k8s",
"extra": {
"externalBaseURL": "https://pm2-cluster-rightsizing.experiments.vadosware.io/",
"k8sImageName": "registry.gitlab.com/mrman/experiment-pm2-cluster-rightsizing/pm2-rightsize-test-app-simple",
"k8sTlsDomain": "pm2-cluster-rightsizing.experiments.vadosware.io",
"k8sTraefikEntrypoint": "websecure",
"k8sContainerPort": 8080,
"k8sSharedTlsSecretName": "pm2-cluster-rightsizing-tls"
}
},
"runner": {
"type": "autocannon"
},
"dimensions": {
"cpuMillicores": [
2000
],
"ramMB": [
4096,
8192,
16384
],
"clients": [ "simple" ],
"apps": [ "simple" ],
"pm2InstanceCounts": [
4,
8,
16,
32
]
}
}
Here are the corresponding graphs:



Keep in mind that in this case the CPU is not changing, only the RAM and number of instances.
It looks like we’ve got a clear answer to the 32 instance count – for some reason with 2 cores and 4GB of RAM, pm2 instance counts of 16 and 32 do way better than 4 and 8. It’s basically bimodal! With more RAM the performance slightly favors the smaller instance counts, but this explains why the easy recommendation would be to just put way more instances than you think you’d need for the number of cores (virtual or otherwise).
Now that we’ve got a framework to use, it’s easy to ask one more question that makes a lot of sense – will the request scale with CPU? We know that the Network will be a bottleneck at some point, but with how light the processing is we should get some gains from raising the CPU limits. I twiddled some configuration so I could quickly check if scaling CPU rather than memory would show some bias-confirming numbers. I changed the configuration to the following:
{
"recorder": {
"directory": "file://./results/k8s",
"format": "json"
},
"provisioner": {
"type": "k8s",
"extra": {
"externalBaseURL": "https://pm2-cluster-rightsizing.experiments.vadosware.io/",
"k8sImageName": "registry.gitlab.com/mrman/experiment-pm2-cluster-rightsizing/pm2-rightsize-test-app-simple",
"k8sTlsDomain": "pm2-cluster-rightsizing.experiments.vadosware.io",
"k8sTraefikEntrypoint": "websecure",
"k8sContainerPort": 8080,
"k8sSharedTlsSecretName": "pm2-cluster-rightsizing-tls"
}
},
"runner": {
"type": "autocannon"
},
"dimensions": {
"cpuMillicores": [
50,
100,
500,
1000
],
"ramMB": [
16384
],
"clients": [ "simple" ],
"apps": [ "simple" ],
"pm2InstanceCounts": [
16
]
}
}
Here’s the graph that I got:

So if I wanted to “right-size” this very simple server, it looks like ~500 millicores is all I would need. In practice it would probably be a lot easier to just use something like a the kubernetes vertical pod autoscaler.
I sure am glad I took the time to think through the little bit of code that automatically finds the changed configuration value and uses it, since I didn’t have to change anything to get the cpuMillicores bit to show up properly.
Looks like we’ve got our answer on the vague 32 instance recommendation! Latency is pretty much bimodal at lower memory levels (heavily in favor of higher instance counts) with an only marginal penalty at higher memory levels, so it’s easy to make the recommendation to just always use a high value (like 32).
Hopefully this was an interesting experiment – I know I had fun yak shaving building the tooling to make it easier to try out scenarios and get graphs. If you’ve run something simliar (or have some anecdata for me) on this topic please feel free to reach out.
If you’d like to run this experiment on your own (don’t worry it’s very simple if you use the local provider, assuming you have docker set up properly), please clone the GitLab repository and try it out – I’d love to know what results you get. If you see a bug, submit a pull request and let’s figure it out!