DDG search drop in powered by ddg.patdryburgh.com
tl;dr - I thought I needed PersistentVolumes but I don’t (I do go through how to use/activate them though), they solve a different problem. All I needed was the combination of a Volume + StatefulSet + Node Affinity + Service in order to get my database running on a single node consistently, and accessible through DNS. I also go through setting up High Availability (HA)/clustered RethinkDB but it’s probably wrong/not axiomatic Kubernetes so check out the section on why I think it’s wrong.
Continuing the follow up to my recent blog series that chronicled the set up of my small single node kubernetes cluster running on coreos, I’m going to explore what it took to get a database up and running on my kubernetes cluster. In the previous post I got a simple HTTP serving pod/service up and running, so now it’s time to ratchet up the complexity, eventually getting close to a full 3-tier app running.
I chose RethinkDB as the database that I chose to set up first (Postgres was the other option) because I have a project that uses it, and also because I love RethinkDB. RethinkDB is the best document store I’ve ever used, check out the Jepsen writeup and you’ll see that not only is it easy to use and packed full of features, it’s correct. These instructions should be largely usable with any other database, though, I focus on what I had to put into Kubernetes to get it to run my databse load, and only as a bonus I included what it took to set up HA/clustered RethinkDB.
RethinkDB is better than Mongo (on just about every axis except popularity, especially if you compare it to past iterations of Mongo), so I want to provide some more press for this awesome open source project. I feel like a broken record repeating the reasons RethinkDB is better, but here’s a quick summary:
If you have some legitimate reasons why Mongo is a better choice as a document store, please feel free to email me a rant or some reasons and I’ll gladly update this section.
Pods are supposed to be ephemeral/stateless things but obviously a database is very much not that. It IS possible, however, to think of the database process (literally the rethinkdb tree of processes in this case) as not much more than an ephemeral program that’s enabling/managing access to some persistent resource (RAM & eventually the harddrive), and in that way, as long as the persistence is properly managed and NOT ephemeral, the database process itself can be. As far as persistent resources go, Volumes and Persistent Volumes are the kubernetes concepts that match and are worth reading up on.
It wasn’t quite clear to me exactly which I needed to use between these two options. Volumes seemed OK because in the end, I knew all I needed to manage was space on disk somewhere. Since I only have one node (feel free to check out my previous blog posts) on the set up I’m working with at the moment), this always results in the same space on disk. Knowing that it works in my current setup isn’t enough however – I need to be sure that the same folder on the SAME NODE get picked, in the likely event that I get more than one node. With this concern, I gravitated towards Persistent Volumes, thinking that they were the proper fix but they solve a somewhat different problem, particularly for users who have large and numerous distinct storage infrastructure (like… 100 10GB slices of disk space for example).
Note from the future: In the end Persistent Volumes weren’t the way to solve my problem – I realized that the better solution was just using a combination of a StatefulSet, a Volume, and Node Affinity settings to ensure that the database pod ends up on a particular node. I’m going to explore what I did up until figuring this out though, so get ready to enter the jungle.
As previously mentioned, feel free to skip this step, as Persistent Volumes were not the simplest way to get the database set up, but I’m leaving this step in just in case it helps anyone else that DOES need a persistent volume set up.
After reading the Persistent Volume documentation, I copied the config from the documentation for the local volume, thinking that’s what I needed (as the disk I needed to read was indeed “local”). I don’t actually have multiple disks/chunks, and I’m not going to partition my current disk that way, so I’m just going to give it a folder and pretend it’s capacity is 5Gigs.. (this is a red flag that I’m doing things wrong, which I figure out later). Here’s what the config looked like, in a file called rethinkdb-pv.yaml:
apiVersion: v1
kind: PersistentVolume
metadata:
name: rethinkdb-pv
annotations:
"volume.alpha.kubernetes.io/node-affinity": '{
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{ "matchExpressions": [
{ "key": "kubernetes.io/hostname",
"operator": "In",
"values": ["XXX.XXX.XXX.XXX"]
}
]}
]}
}'
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /var/data/rethinkdb
So what this configuration was supposed to do was to create a persistent voliume that was affiliated to a particular node (the master node, in this case my only node). The idea was that after I created this persistent volume, I could then pass it to whichever database pods that needed it.
To try and create this persistent volume, I ran kubectl create -f rethinkdb-pv.yaml, but was surprised when it didn’t work – luckily the error message was very clear, basically amounting to the fact that persistent volumes are a gated feature that must be enabled.
Feature gates are specified when kubelet starts up, as specified in the configuration for kubelet (CTRL+F “feature-gate”).
kubelet (as I use systemd, mine is at /etc/systemd/system/kubelet.service)--feature-gates=PersistentLocalVolumes=true to long list of options for starting kubeletAfter making these changes and trying to restart the service, I ran into an error from some invalid configuration in the kubelet unit file: --secure-port and --basic-auth-file were improperly specified. After some trial and error and watching journalctl -xef -u kubelet helped me figure out what I was doing wrong:
--basic-auth-file isn’t supported in the kubelet unit file--secure-port isn’t supported in the kubelet unit file (it’s supposed to go in the API server’s manifest)--feature-gates doesn’t even go there… the whole approach is wrong.The documentation I ran across for local volumes did indeed state it clearly, so maybe I just didn’t read closely enough:
Configure the Kubernetes API Server, controller-manager, scheduler, and all kubelets with the PersistentLocalVolumes feature gate.
So it looks like the parts of Kubernetes that are set up with the MANIFESTS are what need to be set up with the appropriate feature gates, most importantly the API server. The API proxy isn’t mentioned but I put the feature gate there too. IIRC updating the manifests should have caused the individual system-level services to restart on their own.
After making these changes to the appropriate manifests, I was able to apply the configuration (kubectl apply -f rethinkdb-pv.yaml) and the persistent volume was created.
The actual database pod will be created by a StatefulSet (as opposed to a regular ReplicaSet), after a good skim/read through the documentation here’s what I went through to get it up.
It turns out that Node Affinity was the more important feature for what I wanted to accomplish, but I didn’t know it at this point – I was still trying to integrate the PersistentVolume with the StatefulSet. After writing out the RethinkDB configuration with a persistentVolumeClaimTemplate to match the PersistentVolume that was created, I got the following error (after running kubectl describe pod rethinkdb-master-0):
Mounting command: mount
Mounting arguments: /var/data/rethinkdb /var/lib/kubelet/pods/ad02a416-7ff7-11e7-8f7c-8c89a517d15e/volumes/kubernetes.io~local-volume/rethinkdb-pv [bind]
Output: mount: special device /var/data/rethinkdb does not exist
It looks like Kubernetes is definitely expecting that “folder” to be an actual device (like you might find at /dev/sda). At this point, I started to think I didn’t really need a persistent volume or a claim to one at all. A regular volume (with hostPath configuration) + node affinity configuration seems like all I need. Here’s the configuration that DID work, to set up the RethinkDB master node:
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: rethinkdb-master
spec:
serviceName: rethinkdb-master
replicas: 1
template: # pod template
metadata:
labels:
app: rethinkdb-master
spec:
hostname: rethinkdb-master
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- XXX.XXX.XXX.XXX
containers:
- name: rethinkdb
image: rethinkdb:2.3.5
# set the canonical address for this node to a custom one
command: ["rethinkdb"]
args:
- --bind
- "all"
- --canonical-address
- "rethinkdb-master:29015"
- --canonical-address
- "$(MY_POD_IP):29015"
volumeMounts:
- name: rdb-local-data
mountPath: /data
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumes:
- name: rdb-local-data
hostPath:
path: /var/data/rethinkdb
---
apiVersion: v1
kind: Service
metadata:
name: rethinkdb-master
labels:
app: rethinkdb-master
spec:
ports:
- port: 28015
name: rdb-api
- port: 29015
name: rdb-cluster-api
selector:
app: rethinkdb-master
So there’s the StatefulSet and the Service that make the rethinkdb master node work. I was able to safely kubectl apply this configuration.
I’d like to think that here all you need to do is change a few options and the image that’s being used around and you’d easily have a Postgres node.
After kubectl applying the previous configuration, the obvious next step was to check the pod logs and make sure it was working properly:
Recursively removing directory /data/rethinkdb_data/tmp
Initializing directory /data/rethinkdb_data
Running rethinkdb 2.3.5~0jessie (GCC 4.9.2)...
Running on Linux 4.11.12-coreos-r1 x86_64
Loading data from directory /data/rethinkdb_data
Listening for intracluster connections on port 29015
Listening for client driver connections on port 28015
Listening for administrative HTTP connections on port 8080
Listening on cluster addresses: 127.0.0.1, 172.17.0.8, ::1, fe80::42:acff:fe11:8%104
Listening on driver addresses: 127.0.0.1, 172.17.0.8, ::1, fe80::42:acff:fe11:8%104
Listening on http addresses: 127.0.0.1, 172.17.0.8, ::1, fe80::42:acff:fe11:8%104
Server ready, "rethinkdb_0_fs4" 7f42b2d8-bea9-45d1-abab-f7900960b31f
A newer version of the RethinkDB server is available: 2.3.6. You can read the changelog at <https://github.com/rethinkdb/rethinkdb/releases>.
This all looks right, so the next step was to port-forward to the pod, and access the admin console that RethinkDB provides:
kubectl port-forward rethinkdb-master-0 5000:8080
Success! connecting to localhost:5000 in my local browser after setting up the port-forward I saw the RethinkDB administration interface, and although it was pretty slow, it was definitely working properly.
As a final test, connecting to the database from a python container, here’s what I did:
kubectl run -it --image=python python-test /bin/bash# pip install rethinkdb (install the python client driveer for RethinkDB)Python 3.6.2 (default, Jul 24 2017, 19:47:39)
[GCC 4.9.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import rethinkdb as r
>>> conn = r.connect(host="rethinkdb")
>>> r.db_list().run(conn)
['rethinkdb', 'test']
As you can see, with this set up, the random Python container I set up was able to access RethinkDB – if we can access it like this, it shouldn’t be a problem for any other apps that get started up in the future.
After the database was set up, I took some time to check cAdvisor to see what my machine usage/utilization was at. If you’re unfamiliar with how to check it:
kubectl get pods -n kube-systemkubectl port-forward <api server pod name> 8888:4194 -n kube-systemlocalhost:8888 in your browserI was able to confirm that resource usage did indeed go up, and I still had lots of space left over (yay dedicated hardware).
To prepare ourselves to go viral and reach true 20xx web scale (tm), we obviously need to figure out how to create a distributed cluster of RethinkDB instances. Jokes aside, the configuration that I’ve shown so far is only good for setting up a single master instance of the database (one replica, with the node affinity settings pinning it to one node).
Since RethinkDB makes clustering so easy, I wanted to also go through setting up a cluster of nodes.
Since I don’t actually have two machines in my cluster, creating another data folder and starting up another pod will have to do. The plan is to simulate having two pods running on different hosts, by spinning up two different rethinkdb instances with different data folders, and by putting this rethinkdb instance in it’s own pod. At this point I wondered whether this new pod would also need a service – technically it only needs to be access the master node, and then the master should be able to use the ClusterIP of the node to respond to it… Probably. At this point I wasn’t sure so I just kept going, creating a folder named /var/data/rethinkdb-slave on the host to store the data for the slave instance.
RethinkDB only needs to be started with the --join option for it to attempt to connect to an existing cluster. At this point, I had my master node set up to be accessible through DNS @ rethinkdb, so I thought it would be as simple as adding --join rethinkdb:29015 (29015 is the default port for intracluster connections). At this point I found out that I needed to actually change to using command AND args in the pod specification, it wasn’t enough to just tack on some more args.
Before figuring out exactly what the resource configuration should look like, I figured I should get my hands dirty and just get it to work first. To get into a running pod and start trying things out I ran: kubectl run -it --image=rethinkdb:2.3.5 test-rethinkdb --command -- /bin/bash
This put me in a pod running the rethinkdb image, with everything it had to offer, but with the default command changed to /bin/bash, so I get a shell to use. This enables me to do things like ensure DNS was pointing to the right things (particularly rethinkdb should be pointing to the master pod) and to test out the arguments that I needed to use to run rethinkdb. Doing this, I found that rethinkdb --join rethinkdb:29015 worked if I did it from the bash prompt, so that was my starting point. While this command started rethinkdb properly,m it produced a different error during rethinkdb startup (visible from the console) about inconsistent routing information.
The “inconsistent routing information” errors that I was receiving caused some head scratching for a bit, but after a while of looking at it, I was convinced it was due to a mismatch between the IP the slave THOUGHT it had (what it broadcast to the master as how to reach it), and how it was ACTUALLY accessible. RethinkDB’s error message for this was great, and suggested that I check out the command line options for rethinkdb, leading me straight to the --canonical-address option. At this point my seemingly working understanding of the issue is that the slave accesses the master pod and registers itself, but the master can’t communicate back to the slave pod.
Since I know I’m going to put all of this in a resource configuration, it didn’t make sense for me to experiment with things like --canonical-address <current cluster ip of the pod I created>. Though you can easily find out the ClusterIP of the pod you’ve started, obviously as different pods get created this could change. What I needed to do was find the ClusterIP of the current node in the ENV variables set up by Kubernetes. After some light searching (using the env command), I find that the ENV variable I want is MY_POD_IP, perfectly named. After making that change, the inconsistent routing error was gone, so it looked like everything was working. Time to make the experimentation I did more permanent, by porting it to a proper resource configuration that I can kubectl apply.
After getting the ephemeral pod working, it was time to cement some of the stuff into a proper resource configuration. After some steps trying to set everything I get the inconsistent routing information error again:
error: Received inconsistent routing information (wrong address) from 10.3.239.250:29015 (expected_address = peer_address [rethinkdb:29015], other_peer_addr = peer_address [127.0.0.1:29015, 172.17.0.8:29015, ::1:29015, fe80::42:acff:fe11:8%104:29015]), closing connection. Consider using the '--canonical-address' launch option.
It looks like the master node is suffering from the same problem as the initial slave that I set up! It doesn’t know that it’s supposed to be accessible from @ rethinkdb:29015, either. This led to updating the configuration. There’s a bunch of trial and error I went through here, but I’m just going to cut it out because a lot of it had to do with figuring out how to properly supply command and args in the resource configuration. Here’s what the finished configuration for a slave deployment looks like:
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: rethinkdb-slave-deployment
spec:
replicas: 1
template: # pod template
metadata:
labels:
app: rethinkdb-slave
spec:
containers:
- name: rethinkdb-slave
image: rethinkdb:2.3.5
command: ["rethinkdb"]
args:
- --bind
- "all"
- --join
- "rethinkdb-master:29015"
- --canonical-address
- "$(MY_POD_IP):29015"
volumeMounts:
- name: rdb-local-data
mountPath: /data
env:
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
volumes:
- name: rdb-local-data
hostPath:
path: /var/data/rethinkdb-data-2
NOTE rethinkdb-master, NOT rethinkdb is the eventual service DNS name that I ended up on, since the master and the slaves are in separate deployments (the master managed by a StatefulSet, the one slave in a regular deployment) I wanted to be sure that it was clear in the future that the service only contained ONE node, the master node.
After kubectl applying this configuration, everything seems to be working fine, but of course, I’m very paranoid at this point, the next step is to port-forward to the pod and see what rethinkdb says about the cluster itself. kubectl port-forward rethinkdb-master-0 5000:8080 and we’re off to the races.
A quick look at the super helpful RethinkDB administration inteface is enough to confirm that everything is working (I can see the second node). Just to make sure, I even replicated a test database to the second node, and everything worked just fine.
Here’s a screenshot I took after it was working:
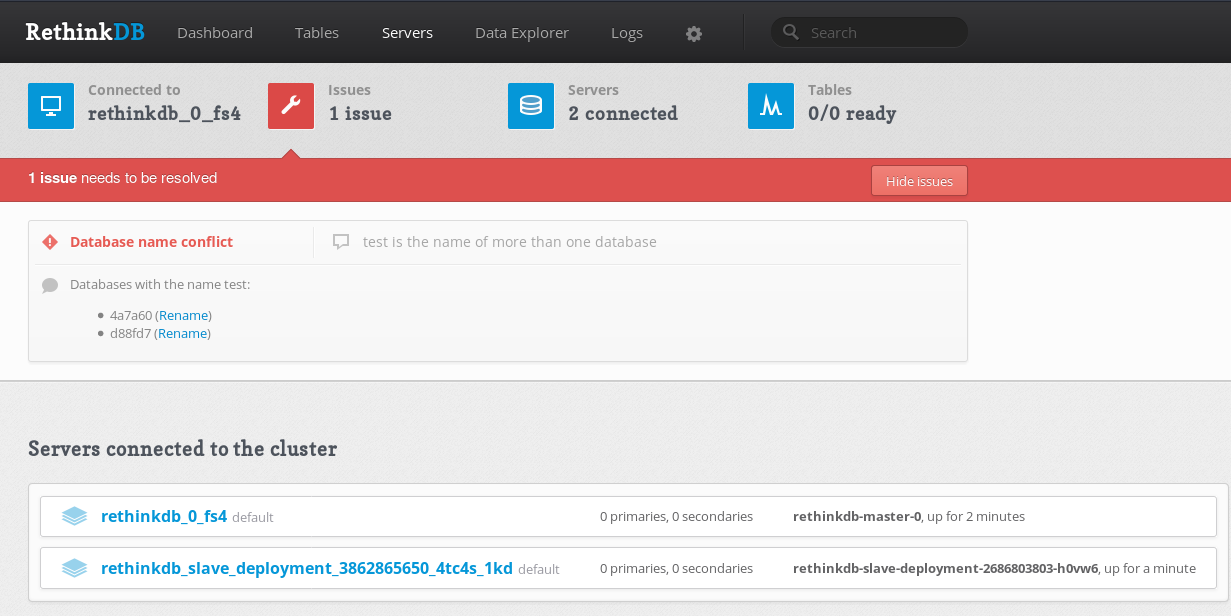
While I think the single StatefulSet for the master node is fine/correct/axiomatic Kubernetes, the HA/cluster set up is almost likely the wrong way to go about it. What doesn’t sit right with me about what I’ve done is the fact that I need TWO deployments to make the distributed system work (one for the master and another for slaves) – this doesn’t seem right. Likely, what I should be doing is making a single StatefulSet Making two different deployments for one distributed system seems to be off/the wrong way of doing things, but since this is what I got working, this is what I’ve put on the blog post.
If I had to try and correct the HA set up, I’d think that what I should have done would be:
This would give me a resource configuration that when applied would create the master node (on a consistent machine), and then create the slave nodes as well, on every node in the Kubernetes cluster EXCEPT the master.
I’ve chosen to leave this for another day, since I don’t have multiple nodes (or a need for HA) just yet.
After all this experimentation, I think I can summarize what I’ve done in a few steps:
--canonical-address for the master rethinkdb node is the service DNS name--join the master by it’s DNS name, and have their --canonical-address(es) set to their ClusterIPs (using ENV)Check out the RethinkDB Architecture docs if you’re interested in learning more about all the awesome stuff RethinkDB has to offer.