DDG search drop in powered by ddg.patdryburgh.com
WARNING - This is a opinion-based fluff piece, read at your own risk. There’s no technical writeup or deep technical insight to be gained in this article, if ever there was in any of my posts to begin with.
tl;dr - the cure for impostor syndrome is growing the amount of slow, hard-fought knowledge you have in a given area. Don’t over-sell how much you know, don’t under-sell it. If you’ve actually read the documentation and/or code for a project, used a piece of code/methodology before in a relevant context, worked through problems with it, you have a certain amount of valuable expertise, even if you are not an expert – being an “expert” is only a matter of how much expertise you possess, and the cutoffs are endlessly subjective.
EDIT - After referencing this blog post in a bit of self-promotion on hacker news there was good discussion that prompts me to soften my stance on this. Here’s an excerpt:
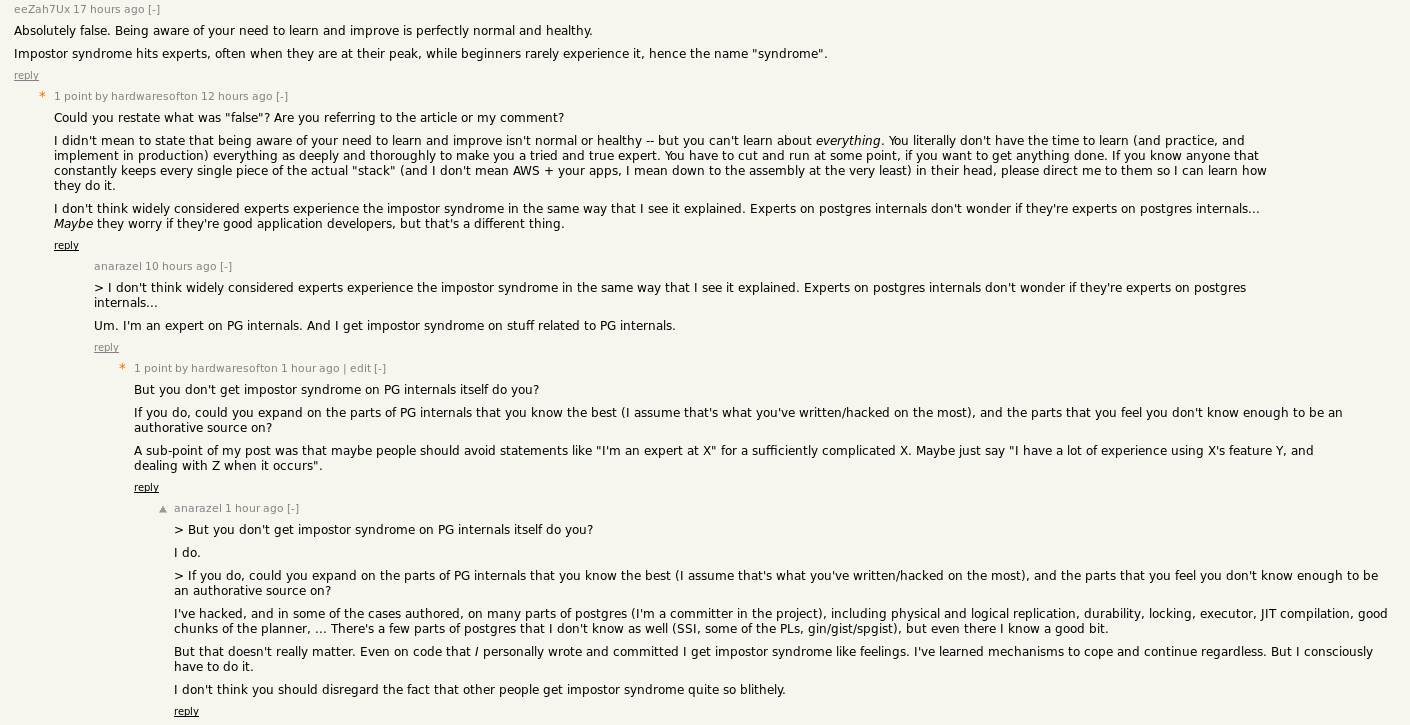
Postgres is one of the best written pieces of functional, stable open source software that exists today. Seeing as a committer to postgres has testified to feeling “impostor syndrome like” feelings on even the code he’s touched then clearly I’m being too hasty in writing it off. I still do believe that the best cure to the feeling of not knowing enough is to do some deep dives and build on your knowledge, and accept where you’ve chosen to go for breadth instead of depth of knowledge, but clearly it’s a little more than that. If I could rewrite this blog post, maybe I’d start with a line like “no one is an expert in every sense of the term on a large part of any sufficiently advanced technology”.
/EDIT
I’m tired of people noting that they suffer form “impostor syndrome” in tech, and the wave of commiseration that often follows. So much of technology/methodology is reasonably deterministic (we try very hard to make it so), and we profess our field to be meritocratic (it’s very much not, but that’s a topic for another fluff post), that it’s always been weird to me when people develop feelings of being a fraud in this environment. Usually, you either know, or you don’t know, or you don’t know that you don’t know. I find it hard to believe that anyone who’s obtained slow, hard-fought knowledge could have the problem of feeling like an impostor in at least the very small very specific area they gained knowledge of. They’ve axiomatically atleast gained expertise in that first 1/3rd of the possibility space – things they know (and know thoroughly).
While this isn’t really meant to be an overly personal, I almost never feel like a fraud, because I try to keep a good grasp on how well I know what I consider myself to know. Things I’ve:
It’s entirely possible that I should feel like a fraud but don’t – but in that case this whole blog post is moot and you should stop reading now. Instead of the possibility that I’m just sadly mistaken, I’d rather believe that the reason I don’t feel like a fraud is because the things I believe I know the most have been things I’ve gained painfully slow, hardfought knowledge about. When I struggle with a piece of tech something for days/months/years, and it takes me on trips through the documentation, to the code, back to my implementation, and ultimately to some concepts I may or may not have known, then all the way back to a fix/resolution, there’s no way I can feel like a fraud about that. If you’ll allow me a bit (maybe a lot) of hyperbole, that’s blood sweat and tears – I “fought” for that fix/resolution. Expertise gained during the exploration of the given system and experimentation is expertise, even if just a drop in an ocean of possible things you could have expertise in.
I’m absolutely NOT a PostgreSQL expert, but I have run a postgres cluster before, and have executed queries against it. I don’t feel like a fraud not knowing exactly how the Postgres binary is optimized, every single subsystem in postgres, because I do not profess to be an expert in Postgres, and (probably) neither should you. There’s a very very very very small amount of people in the world who should claim the title of being Postgres experts. Even if you wrote the subsystem someone has is asking about, it’s possible for someone to use it in a context that’s completely foreign to you, instantly leaving you with posslbly close to zero applicable expertise. That’s just the combinatorically explosive nature of implementation and use of technology.
Here’s a silly imaginary example. Let’s say you invented the pen – you may then might be the the worlds foremost expert on pens, for a while at least. However, if someone comes along, takes one of your pens into space and runs into some issues using it and comes up with some solutions, that person now possesses some expertise that not even the world’s foremost expert on pens possesses. That person may lack 99% of the known knowledge of pens, but they now possess 1% of the known knowledge (namely how to optimize pens for usage in space) that others simply cannot know until the knowledge is shared somehow.
In the end, all anyone ever has, expert or not, is pieces of the space of known knowledge on any given subject. You can have a bunch of the pieces, or a relative few, or you can have none – it’s just about impossible to have all of them, unless the space is pretty small.
How do you get more pieces (i.e. slow, hard-fought knowledge)? Unless you’re deep in research (I.E. Leslie Lamport working on ordering in a distributed system or team at MIT & John McCarthy discovering LISP), which is to say you’re turning unknown/unverified knowledge into known knowledge and creating new pieces, the vast majority of the new (to you) knowledge you attain is going to be by reading, being taught, or experimentation. Different kinds of knowledge be attained in different ways, and the same knowledge can be reinforced by learning it repeatedly in different ways. Those are the only tools available to be an “expert” in anything, until humankind figures out a way to transplant knowledge, as far as I know.
So back to the issue of impostor syndrome. Assuming what I’ve said is true (which is indeed a leap), why should anyone feel like a fraud? I think it boils down to roughly two things:
For #1, this is possibly a radical thought, but maybe people should stop over-selling themselves to prospective employers, others, and themselves as knowing more than they know? The oft-quoted platitude “the more you know the less you know” is by and large true – experts in a given sufficiently complex system very rarely think they know absolutely everything about the system. The attitude I’ve found from knowledgable people I’ve met is that they comment on things they know to be true, and are curious about everything else, willing to update their knowledge as necessary and move on.
As for #2, it happens to me all the time, and I think it’s inevitable, but it doens’t leave me feeling like an impostor. Why? Let’s go back to the postgres example. If someone’s asking me about sending queries to Postgres, or how to SELECT all the content out of a table, I can probably help with that. I have expertise in that area, despite not being a postgres expert. In this obviously trivial example, if the same person followed up with a question about how to reliably shard their postgres cluster among different nodes, though I have some knowledge in the area I recognize that I do not have enough that would count for expertise. In that situation, I try my best to say “I don’t know about that, but I do know about X which is where I would start looking”.
Regarding #3, there’s not much I can say about that – clearly this is why it’s a “syndrome”. Just a case of Sometimes people don’t think it be like it is, but it do, where I’m the party that just doesn’t know.
No single human is capable of completely understanding the sum total of technological advancements that added up to modern systems of today, even if you restrict the scope to something as relatively small as “web services”. Do you know why I think I can make such a brash absolute statement? It is highly highly improbable for someone to hold 50+ years worth of the history of computing and the insights (which almost always build together successively) within in their head – if you meet someone like that, please let me know so I can retract this statement immediately. To completely master a “stack” in the literal sense means knowing everything from mobile operating systems, to AWS to branch prediction on processors, maybe even down to the sand that makes your silicon. At that point you have no choice but to trade depth for breadth of knowledge, there’s simply too much to deep dive on.
Want to solve your impostor syndrome? Repeat after me (preferably in a tech interview): “While I wouldn’t consider myself an expert on A, I have read about A and done X, Y, and Z with it so I’m confident I can solve problems with it and debug it when things go wrong.” Maybe if enough people think like this then we can stop declaring ourselves to be rockstar full-stack tech ninjas to get jobs where we maintain some legacy application day in and day out.
When I hear people lament impostor syndrome, I often find myself prejudiced against them, deciding internally that they simply haven’t thought through this problem enough – I’m no genius, surely they would reach a similar conclusion. There’s so much out there to learn, no one can learn it all, but you can establish solid knowledge of small bits of it with effort, repitition, and experimentation. The process is there, it’s just boring – it’s hard work. I can’t imagine anyone who’s invested hundreds/thousands of hours into understanding a technology feeling like a fraud. On the other hand, If someone’s invested only tens of minutes/hours into understanding a technology and considers themselves an impostor, it’s more likely that they’re just a novice, and need to understand themselves as so and that’s it.
If you don’t want to be a fraud, or feel like one, do the hard work of learning and researching and experimenting with the technology. If you somehow manage to do all this and still feel like a fraud, in that very specific subset, please contact me so I can take down this post. If you somehow manage to do all the hard work and feel like you’re not an expert in the large umbrella of things the technology entails, realize that’s OK – it’s hard (just about impossible) to know everything.
When I make mistakes because of incomplete knowledge, whether it’s due to not reading the documentation I should have, or not understading the system I was changing well enough, I make the decision whether to deep dive (as long as is necessary) to understand what I fucked up, or whether it’s better (on various axes) to only shallowly understand it for now and move on. The answer varies, but in the end it’s a choice, and I believe form there I just need to communicate to others the decisions I’ve made in my learning trajectory and let them be the judge – “Yes I’ve listed Postgres on my resume, I understand it reasonably well – I couldn’t tell you about coordinating HA postgres clusters while maintaining high write throughput loads for thousands of clients, but I can definitely write a JOIN or two, and know roughly where to look for the knowledge I would need to solve the other thing, along with the persistence to find a solution”.
Somewhere deep down I’m getting the feeling I just set up a strawman and unsympathetically pummeled it for a good 10 minutes. At the very least I hope the bout was entertaining to read.
PS I pick PostgreSQL as an example in this post a lot because it’s what I and probably many others consider to be the best open source relational database ever built. It is a complex beast, but developed by many many conscientious, intelligent engineers, with tradeoffs made in a generally principled, roughly democratic way. There is incredible knowledge on systems built as well as postgres in books like the Architecture of Open Source Applications (AOSA), which are completely available for free. Papers from journals are made available all the time, MIT open sources coursework, textbooks are available for free on the internet (legally or illegally). Knowledge is so freely available (assuming of course you’ve already satisfied other needs and have an internet connection and free time to seek it out) these days that technological ignorance in the tech space, where it could be argued to be your job to keep abreast of technology in your space, is a ongoing decision, not something to be quietly lamented.