DDG search drop in powered by ddg.patdryburgh.com
tl;dr - stream-of-consciousness notes as I stumbled through upgrading a k0s cluster from single-node to HA control plane. You probably shouldn’t attempt to do this though, just make a new HA-from-day-one cluster and move your workloads over.
Recently I went through the somewhat traumatic experience of upgrading a k0s Kubernetes cluster from a single master (I was running 1 controller+worker node with other worker-only nodes) to a group of HA controller-only nodes with the same set of workers. Looking around the internet I couldn’t find much on how to do the conversion (the k0s documentation are excellent, but don’t quite cover how to convert), so I had to somewhat piece it together.
The better way to do what I did was probably to build a new cluster and move workloads over one by one (it’s possible to even put in place some networking to make the switchover seamless). In retrospect, that was the better idea. But you’re not here for the clean yak shaves.
I left myself some stream-of-consciousness notes so I’m sharing them here for anyone that might come after and attempt to do this, but I do want to note that you should almost certainly just make a new cluster.
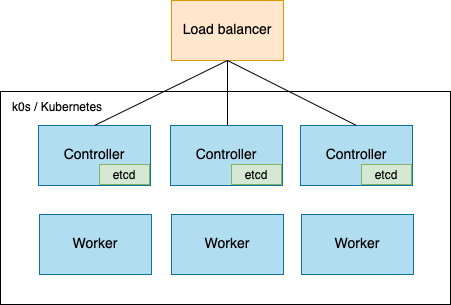
Before undergoing this change the cluster was 3-4 beefy machines running k0s:

Where I want to get to is the following:

Obviously the issue here will be how to get from 1 worker acting as a worker and controller to a completely different set of nodes serving as the controllers.
Well it’s simple (in theory):
As the k0s docs are pretty good, there is a great page on control plane HA which is worth reading:
Before starting it was important (for me) to take a backup with k0s since it was almost guaranteed something would go wrong eventually (things did go wrong).
Even if the control plane goes down, if your DNS is targeting worker nodes, apps should not go down immediately, giving you time to correct issues or revert (as long as you have a backup).
controller+worker role node)Since I’m running workloads on the main node, those workloads were at risk (the master node is likely to go down/have issues) – redeploying workloads where necessary and kubectl draining the master node should prevent unnecessary downtime.
Another thing that’s worth taking a direct backup of is etcd – this is included in the k0s backup but knowing how to take a backup with etcd and how the data is laid out on disk is a good-to-know.
With a backup in place we can keep calm and restore from backup if/when necessary.
To make sure all workloads will be safe from control plane failures as we do this migration (and/or restarting the main node), you can evict all workloads from the node and mark it unschedulable.
This is also a great time to set up the load balancer, and connect it to the new controller node we just stood up.
A load balancer is required (as of now) for the HA control plane used by k0s.
The k0s documentation on setting up nodes is worth reading and should be followed – in our case we’re going from a --single setup to a HA setup so some consideration is required.
First we’ll want to create a new controller node, and since I’m using hcloud I have to do all the usual node hardeining tasks – installing ufw, fail2ban, ensuring only required ports are open, etc.
On your existing controller, take a backup of your k0s config file (usually @ /etc/k0s/k0s.yaml) for safe keeping.
We’re going to modify this file, but it will be somewhat in-between the single-master and HA settings.
At this point, for k0s config I didn’t insert the HA load balancer as the external address, so the config is essentially a mishmash. Do not put the load balancer related address in just yet.
api:
address: XXX.XXX.XXX.XXX # IP address of the controller+worker node
externalAddress: node-1.k8s.cluster.domain.tld # DNS name of the controller + worker node
extraArgs:
http2-max-streams-per-connection: "1000"
k0sApiPort: 9443
port: 6443
sans:
- XXX.XXX.XXX.XXX
- YYY.YYY.YYY.YYY # another node
- node-1.k8s.cluster.domain.tld
- 127.0.0.1
Note that we’re using the previous master’s IP & DNS name as the address/externalAddress so we’re not following the map for k0s HA just yet.
The SANs include the new node and the old node and whatever else was there previously.
One thing we will set to the new load balancer (which currently has one node) is the ETCD peer address. The original master which is running etcd will be able to connect to the load balancer and make a connection the the etcd node there (attached to the one new controller node).
The following ports should be open on the new controller and load balancer:
22, // SSH (for k0sctl)
6443, // k8s
8132, // konnectivity
9443, // k0s api (for cluster join)
2380, // etcd (controller <-> controller)
k0sctl.yamlNow we want to update the k0s YAML cluster configuration. We’re not going to add the load balancer in here just yet either.
At this point, only one entry should have controller+worker as the role (the rest would be worker roles).
---
apiVersion: k0sctl.k0sproject.io/v1beta1
kind: Cluster
metadata:
name: frodo
spec:
k0s:
version: 1.21.1+k0s.0
# NOTE: with only one node, draining has to be skipped w/ --no-drain
hosts:
- role: controller+worker
ssh:
address: <the current main node you already have>
user: root
port: 22
keyPath: ~/.ssh/path/to/your/id_rsa
# New controller only node
- role: controller
ssh:
address: <address of the new first HA node>
user: root
port: 22
keyPath: ~/.ssh/path/to/your/id_rsa
- role: worker
ssh:
address: <a worker>
user: root
port: 22
keyPath: ~/.ssh/path/to/your/id_rsa
# ... more worker nodes down here ....
--single from the k0scontroller systemd unit configurationk0scontroller is the process that runs on controller nodes (or controller+worker nodes), and it’s controlled by systemd, so it’s configuration is specified in a unit file.
On your current master (node with role controller+worker) --single was specified specified which prevents new nodes from joining. The reason nodes can’t join a cluster with a --single controller is that the k0s join API is not running at port 9443 like it usually is in a HA setup.
Removing the --single flag from your k0scontroller systemd service configuration (see /etc/systemd/system) will enable k0s to start running the join API
We’ve got teh cluster ready to accept a new node, but we haven’t actually joined the new node yet!
You’ll need a controller role join token, every time, for every new controller. So on the current master, run the following:
$ k0s token create --role=controller --expiry=48h > /tmp/controller-join.token
Copy the file generated @ /tmp/controller-join.token to the new controller node that has been set up.
You can attach the new node manually (assuming you copied the controller join token to /tmp/controller-join.token) by running the following:
$ k0s install controller --token-file /tmp/controller-join.token -c /etc/k0s/k0s.yaml
$ k0s start
On the original master, you should see a log like this coming out of k0scontroller:
INFO[2021-12-06 13:37:31] etcd API, adding new member: https://NNN.NNN.NNN.NNN:2380
If you see the etcd members update then you know that you’re on the right path (assuming XXX.XXX.XXX.XXX is the original controller+worker and YYY.YYY.YYY.YYY is the new load balancer address):
root@node-1 ~ # export ETCDCTL_API=3
root@node-1 ~ # etcdctl --endpoints=https://127.0.0.1:2379 --key=/var/lib/k0s/pki/etcd/server.key --cert=/var/lib/k0s/pki/etcd/server.crt --insecure-skip-tls-verify member list
4419ae2057d1f048, started, ctrl-0.k8s, https://YYY.YYY.YYY.YYY:2380, https://127.0.0.1:2379
880b4bba1672d7b3, started, node-1.k8s, https://XXX.XXX.XXX.XXX:2380, https://127.0.0.1:2379
It’s very likely that the old master will be picked as the new leader and the other (newly added) nodes will be followers.
At first, you will want to edit /etc/k0s/k0s.yaml such that the old leader is the external address:
---
apiVersion: k0s.k0sproject.io/v1beta1
kind: Cluster
metadata:
name: k0s
spec:
telemetry:
enabled: false
api:
externalAddress: XXX.XXX.XXX.XXX #YYY.YYY.YYY.YYY
sans: ["XXX.XXX.XXX.XXX","YYY.YYY.YYY.YYY"]
NOTE: XXX.XXX.XXX.XXX is the original node and YYY.YYY.YYY.YYY is the new load balancer (at this point with 1 new controller node attached).
I did something like this, then restarted k0scontroller (the systemd service that is installed by k0s) on the nodes.
For all subsequent controllers the config in k0sctl.yaml should work just fine.
At this point you might find that ETCD is stuck at 3 nodes in the member list, rather than 4 – it’s important to make sure all 4 are in.
Do NOT settle for the following:
root@ctrl-2:~# export ETCDCTL_API=3
root@ctrl-2:~# etcdctl --endpoints=https://127.0.0.1:2379 --key=/var/lib/k0s/pki/etcd/server.key --cert=/var/lib/k0s/pki/etcd/server.crt --insecure-skip-tls-verify member list
4419ae2057d1f048, started, ctrl-0.k8s, https://ZZZ.ZZZ.ZZZ.ZZZ:2380, https://127.0.0.1:2379
880b4bba1672d7b3, started, node-1.k8s, https://XXX.XXX.XXX.XXX:2380, https://127.0.0.1:2379
af37193f16df15b4, started, ctrl-2.k8s, https://AAA.AAA.AAA.AAA:2380, https://127.0.0.1:2379
Once you’ve got the 4 node setup, we can move on to removing the extraneous node.
At this point we cna atempt to remove the original node from the etcd cluster. This is a destructive operation so be very careful when performing it:
root@ctrl-0:~# etcdctl --endpoints=https://127.0.0.1:2379 --key=/var/lib/k0s/pki/etcd/server.key --cert=/var/lib/k0s/pki/etcd/server.crt --insecure-skip-tls-verify member remove 880b4bba1672d7b3
Member 880b4bba1672d7b3 removed from cluster b3e7667b2e90a09
After doing this you can check the members again.
k0sctl.yamlAt this point you’ll want to rewrite k0sctl.yaml with all the new controller nodes with the correct types:
k0sctl applyBEWARE: if you partially specify the external address in k0s:config:spec…, you will override all the other stuff with defaults, which could result in trying to switch from calico to kuberouter. (k0scontroller will fail to start though, so you’re safe from that)
Through all this, your workloads should be fine, as they should be happily running on the other cluster worker nodes (and pointed to via DNS).
At this point, you can switch back to your regular kubectl flow, and check on the nodes:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node-1.k8s NotReady <none> 184d v1.21.1-k0s1
node-2.k8s NotReady <none> 43d v1.21.1-k0s1
node-3.k8s NotReady <none> 67d v1.21.1-k0s1
node-5.k8s NotReady <none> 77d v1.21.1-k0s1
It’s a bit terrifying to see so many NotReadys, but the reason is obviously – we haven’t told the nodes that they should be connecting to the new controller set just yet.
k0sctl sporadically failed during apply but I just ignored that and kept going
Since we want the worker nodes to connect to the new controllers, we need to generate new join tokens.
Two steps should set up a node:
You can find where the token should go by checking the contents of /etc/systemd/system/k0scontroller.service, Ex:
[Unit]
Description=k0s - Zero Friction Kubernetes
Documentation=https://docs.k0sproject.io
ConditionFileIsExecutable=/usr/bin/k0s
After=network-online.target
Wants=network-online.target
[Service]
StartLimitInterval=5
StartLimitBurst=10
ExecStart=/usr/bin/k0s worker --config=/var/lib/k0s/config.yaml --labels="storage=nvme,storage.zfs=true,storage.localpv-zfs=true,storage.longhorn=true" --token-file=/var/lib/k0s/worker.token
RestartSec=120
Delegate=yes
KillMode=process
LimitCORE=infinity
TasksMax=infinity
TimeoutStartSec=0
LimitNOFILE=999999
Restart=always
[Install]
WantedBy=multi-user.target
In the example above the token file is @ /var/lib/k0s/worker.token (take a backup!).
Update the node’s /var/lib/k0s/config.yaml or /etc/k0s/k0s.yaml (if present), with the new address/externalAddress (both should be pointing to the load balancer). Be on the lookout for anywhere the old master node IP is being used. If your external address is the IP address for the API that’s fine too
Next, update /var/lib/k0s/kubelet.conf & /var/lib/kubelet-bootstrap.conf with the new load balancer address. Beware of your old cluster certificate not working (for kubectl).
Here’s an example of what the bootstrap file would look like:
apiVersion: v1
clusters:
- cluster:
server: https://your.new.api.address:6443 # https://the.old.ip.address
certificate-authority-data: <redacted>
name: k0s
contexts:
- context:
cluster: k0s
user: kubelet-bootstrap
name: k0s
current-context: k0s
kind: Config
preferences: {}
users:
- name: kubelet-bootstrap
user:
token: xxxxxx.aaaaaaaaaaaaaaaa # redacted
After makingt hese changes, restart (stop, start) k0sworker maually on every machine, and run k0sctl apply to prevent the workers from picking up the old IP addresses.
NOTE during all this all your workloads should continue to run – your ingress controller(s) are sitting on the worker nodes being pointed at by DNS/load balancers and are happily taking incoming traffic and giving it to pods. nothing we’ve done so far should have upset your CNI plugin or pods directly.
bufio.Scanner token too longWhen I was doing this I ran into the following error in worker logs (after k0sctl apply):
Dec 07 10:21:48 node-5.eu-central-1 k0s[3029082]: time="2021-12-07 10:21:48" level=info msg="I1207 10:21:48.163618 3030291 fs.go:131] Filesystem UUIDs: map[014715bb-a61f-469b-80b1-fa38726ea950:/dev/sde 06548ab2-5fed-4c6a-a1ee-b4c4a2cbc833:/dev/sdc 5fbac445-af53-40e4-a37f-975736a8d787:/dev/md2 64c368c1-5769-467e-8626-3881ba8cbe25:/dev/md1 7762831980165748493:/dev/nvme0n1p5 7f43769e-4a6b-4433-9884-968373e7fc50:/dev/sdd 93bf0ee8-0623-4f8b-a369-abafc312b310:/dev/sda 9b79a669-3b62-499c-a994-b068466c95af:/dev/md0 a5ca05fd-4fd8-462e-a3e8-8e3be7590bd1:/dev/sdb d6bd0261-d26e-4009-b448-acb54b02aa37:/dev/sdf f334a003-af04-4a61-b11e-dd912d979517:/dev/zd0]" component=kubelet
Dec 07 10:21:48 node-5.eu-central-1 k0s[3029082]: time="2021-12-07 10:21:48" level=error msg="Error while reading from Writer: bufio.Scanner: token too long" component=kubelet
Dec 07 10:21:48 node-5.eu-central-1 k0s[3029082]: time="2021-12-07 10:21:48" level=warning msg="signal: broken pipe" component=kubelet
Dec 07 10:21:48 node-5.eu-central-1 k0s[3029082]: time="2021-12-07 10:21:48" level=info msg="respawning in 5s" component=kubelet
The way to get past it is to restart the node(s).
I think this had to do with the block devices that a system like longhorn sets up:
root@node-5 ~ # lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 8G 0 disk /var/lib/k0s/kubelet/pods/970041a9-24ae-4a13-9d6a-f086f8199c66/volume-subpaths/pvc-c7d9885e-4661-4897-9567-f57cdc705a74/pg/0
sdb 8:16 0 1G 0 disk /var/lib/k0s/kubelet/pods/a6f25e10-522a-406c-9add-6cc7085e7f34/volumes/kubernetes.io~csi/pvc-75cab383-60ff-488c-b049-096f05e147e4/
sdc 8:32 0 4G 0 disk /var/lib/k0s/kubelet/pods/22dd0618-82e0-4e23-a84f-6db1180bf7e7/volumes/kubernetes.io~csi/pvc-22586f91-8a47-4dfb-b4d6-c1ac32e6ccf6/
sdd 8:48 0 16G 0 disk /var/lib/k0s/kubelet/pods/a6f25e10-522a-406c-9add-6cc7085e7f34/volumes/kubernetes.io~csi/pvc-b3c5677e-36f0-4987-9fdf-d305b77d1926/
sde 8:64 0 1G 0 disk /var/lib/k0s/kubelet/pods/d2d82dc2-5bf2-413f-bd97-86b99390c553/volumes/kubernetes.io~csi/pvc-8a85d0f0-9713-45b3-b6e9-448a69a6859c/
sdf 8:80 0 1G 0 disk /var/lib/k0s/kubelet/pods/a6f25e10-522a-406c-9add-6cc7085e7f34/volumes/kubernetes.io~csi/pvc-ed13ef28-6a27-4200-8a3d-de7530201d51/
zd0 230:0 0 150G 0 disk /var/lib/longhorn
nvme1n1 259:0 0 477G 0 disk
├─nvme1n1p1 259:1 0 32G 0 part
│ └─md0 9:0 0 32G 0 raid1 [SWAP]
├─nvme1n1p2 259:2 0 1G 0 part
│ └─md1 9:1 0 1022M 0 raid1 /boot
├─nvme1n1p3 259:3 0 128G 0 part
│ └─md2 9:2 0 127.9G 0 raid1 /
├─nvme1n1p4 259:4 0 1K 0 part
└─nvme1n1p5 259:5 0 316G 0 part
nvme0n1 259:6 0 477G 0 disk
├─nvme0n1p1 259:7 0 32G 0 part
│ └─md0 9:0 0 32G 0 raid1 [SWAP]
├─nvme0n1p2 259:8 0 1G 0 part
│ └─md1 9:1 0 1022M 0 raid1 /boot
├─nvme0n1p3 259:9 0 128G 0 part
│ └─md2 9:2 0 127.9G 0 raid1 /
├─nvme0n1p4 259:10 0 1K 0 part
└─nvme0n1p5 259:11 0 316G 0 part
After a restart lsblk is much shorter:
root@node-5 ~ # lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:0 0 477G 0 disk
├─nvme0n1p1 259:2 0 32G 0 part
│ └─md0 9:0 0 32G 0 raid1 [SWAP]
├─nvme0n1p2 259:3 0 1G 0 part
│ └─md1 9:1 0 1022M 0 raid1 /boot
├─nvme0n1p3 259:4 0 128G 0 part
│ └─md2 9:2 0 127.9G 0 raid1 /
├─nvme0n1p4 259:5 0 1K 0 part
└─nvme0n1p5 259:6 0 316G 0 part
nvme1n1 259:1 0 477G 0 disk
├─nvme1n1p1 259:7 0 32G 0 part
│ └─md0 9:0 0 32G 0 raid1 [SWAP]
├─nvme1n1p2 259:8 0 1G 0 part
│ └─md1 9:1 0 1022M 0 raid1 /boot
├─nvme1n1p3 259:9 0 128G 0 part
│ └─md2 9:2 0 127.9G 0 raid1 /
├─nvme1n1p4 259:10 0 1K 0 part
└─nvme1n1p5 259:11 0 316G 0 part
All those disks will get recreated but it looks like kubelet has a problem if they’re present at startup.
This process was a PITA. Can’t help but wonder if it’s this hard with regular kubeadm but given that the cluster purrs along just about in every other instance, k0s is still my favorite. Most of this complexity is probably endemic, though it was a bit annoying trying to view logs with k0scontroller/k0sworker showing a fast moving mixed stream of logs.
If you run k0sctl your main node will get tainted – you may need to remove the taints if something goes wrong or you want to revert:
$ k taint nodes node-1.k8s node.kubernetes.io/unreachable:NoSchedule-
node/node-1.k8s untainted
$ k taint nodes node-1.k8s node.kubernetes.io/unreachable:NoExecute-
node/node-1.k8s untainted
Note that very important workloads like Calico or Traefik will get stuck and won’t be able to restart their DaemonSet pods on the previous-controller+worker node (which was part of your cluster).
ETCD is likely to start failing, despite some certs and k0s being operational:
Dec 06 12:43:19 frodo-ctrl-0 k0s[3260]: {"level":"warn","ts":"2021-12-06T12:43:19.842Z","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-7611dc43-189d-4ec2-a4e9-31ec8e1304af/127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Dec 06 12:43:19 frodo-ctrl-0 k0s[3260]: time="2021-12-06 12:43:19" level=error msg="health-check: Etcd might be down: context deadline exceeded"
Dec 06 12:43:20 frodo-ctrl-0 k0s[3260]: {"level":"warn","ts":"2021-12-06T12:43:20.844Z","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-1f3fb077-f989-4c8c-aa9a-ee9e5862aae7/127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Dec 06 12:43:20 frodo-ctrl-0 k0s[3260]: time="2021-12-06 12:43:20" level=error msg="health-check: Etcd might be down: context deadline exceeded"
Dec 06 12:43:21 frodo-ctrl-0 k0s[3260]: {"level":"warn","ts":"2021-12-06T12:43:21.845Z","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-18684a14-e6fa-4392-8dcc-35fafe16a5bf/127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Dec 06 12:43:21 frodo-ctrl-0 k0s[3260]: time="2021-12-06 12:43:21" level=error msg="health-check: Etcd might be down: context deadline exceeded"
The single controller node should be running etcd (unless you’ve picked kine, in which you probably don’t have to worry about this at all, congratulations)
root@node-1 ~ # pgrep etcd -la
34537 /var/lib/k0s/bin/etcd --cert-file=/var/lib/k0s/pki/etcd/server.crt --peer-trusted-ca-file=/var/lib/k0s/pki/etcd/ca.crt --log-level=info --advertise-client-urls=https://127.0.0.1:2379 --peer-client-cert-auth=true --initial-advertise-peer-urls=https://XXX.XXX.XXX.XXX:2380 --trusted-ca-file=/var/lib/k0s/pki/etcd/ca.crt --key-file=/var/lib/k0s/pki/etcd/server.key --peer-cert-file=/var/lib/k0s/pki/etcd/peer.crt --name=node-1.eu-central-1 --auth-token=jwt,pub-key=/var/lib/k0s/pki/etcd/jwt.pub,priv-key=/var/lib/k0s/pki/etcd/jwt.key,sign-method=RS512,ttl=10m --listen-client-urls=https://127.0.0.1:2379 --client-cert-auth=true --enable-pprof=false --data-dir=/var/lib/k0s/etcd --listen-peer-urls=https://XXX.XXX.XXX.XXX:2380 --peer-key-file=/var/lib/k0s/pki/etcd/peer.key
You can talk to the etcd node from the the single controller like so:
root@node-1 ~ # export ETCDCTL_API=3
root@node-1 ~ # etcdctl --endpoints=https://127.0.0.1:2379 --key=/var/lib/k0s/pki/etcd/server.key --cert=/var/lib/k0s/pki/etcd/server.crt --insecure-skip-tls-verify member list
880b4bba1672d7b3, started, node-1.eu-central-1, https://XXX.XXX.XXX.XXX:2380, https://127.0.0.1:2379
This will be important later when we want to remove some nodes from the etcd cluster (and in general for diagnostics).
Konnectivity is a massive pain in my neck, and I figured it would be. Konnectivity’s job is to make control plane -> worker comms possible, but it’s a bit more complicated of a set up than the node-to-node SSH tunnels that previous versions of kubernetes used.
Turns out it will sometmes fail to find a backend for seemingly no reason at all:
Dec 06 13:42:30 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:42:30" level=info msg="Trace[952303301]: [30.003698446s] [30.003698446s] END" component=kube-apiserver
Dec 06 13:42:30 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:42:30" level=info msg="I1206 13:42:30.936356 5715 trace.go:205] Trace[176610740]: \"Proxy via grpc protocol over uds\" address:10.96.71.211:443 (06-Dec-2021 13:42:00.932) (total time: 30004ms):" component=kube-apiserver
Dec 06 13:42:30 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:42:30" level=info msg="Trace[176610740]: [30.004029084s] [30.004029084s] END" component=kube-apiserver
Dec 06 13:42:30 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:42:30" level=info msg="I1206 13:42:30.936998 5715 trace.go:205] Trace[1123926905]: \"Proxy via grpc protocol over uds\" address:10.96.71.211:443 (06-Dec-2021 13:42:00.932) (total time: 30003ms):" component=kube-apiserver
Dec 06 13:42:30 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:42:30" level=info msg="Trace[1123926905]: [30.003979291s] [30.003979291s] END" component=kube-apiserver
Dec 06 13:42:30 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:42:30" level=info msg="I1206 13:42:30.939681 5715 trace.go:205] Trace[735764735]: \"Proxy via grpc protocol over uds\" address:10.96.71.211:443 (06-Dec-2021 13:42:00.932) (total time: 30007ms):" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.752966 5715 clientconn.go:948] ClientConn switching balancer to \"pick_first\"" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.753448 5715 clientconn.go:897] blockingPicker: the picked transport is not ready, loop back to repick" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="E1206 13:40:03.754883 5768 server.go:385] \"Failed to get a backend\" err=\"No backend available\"" component=konnectivity
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.752285 5715 clientconn.go:106] parsed scheme: \"\"" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.753796 5715 clientconn.go:106] scheme \"\" not registered, fallback to default scheme" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.753842 5715 passthrough.go:48] ccResolverWrapper: sending update to cc: {[{/run/k0s/konnectivity-server/konnectivity-server.sock <nil> 0 <nil>}] <nil> <nil>}" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.753918 5715 clientconn.go:948] ClientConn switching balancer to \"pick_first\"" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.753945 5715 clientconn.go:897] blockingPicker: the picked transport is not ready, loop back to repick" component=kube-apiserver
Dec 06 13:40:03 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:03" level=info msg="I1206 13:40:03.755660 5715 passthrough.go:48] ccResolverWrapper: sending update to cc: {[{/run/k0s/konnectivity-server/konnectivity-server.sock <nil> 0 <nil>}] <nil> <nil>}" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.731130 5715 clientconn.go:948] ClientConn switching balancer to \"pick_first\"" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.731161 5715 clientconn.go:897] blockingPicker: the picked transport is not ready, loop back to repick" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.736462 5768 server.go:385] \"Failed to get a backend\" err=\"No backend available\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.738132 5768 server.go:385] \"Failed to get a backend\" err=\"No backend available\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.738157 5768 server.go:385] \"Failed to get a backend\" err=\"No backend available\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.740480 5715 client.go:111] DialResp not recognized; dropped" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.740942 5715 client.go:111] DialResp not recognized; dropped" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.741034 5715 client.go:111] DialResp not recognized; dropped" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.741788 5768 server.go:385] \"Failed to get a backend\" err=\"No backend available\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.742527 5768 server.go:354] \"Stream read from frontend failure\" err=\"rpc error: code = Canceled desc = context canceled\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.742581 5768 server.go:385] \"Failed to get a backend\" err=\"No backend available\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.742854 5768 server.go:354] \"Stream read from frontend failure\" err=\"rpc error: code = Canceled desc = context canceled\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.742870 5715 client.go:111] DialResp not recognized; dropped" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.743197 5768 server.go:354] \"Stream read from frontend failure\" err=\"rpc error: code = Canceled desc = context canceled\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="I1206 13:40:04.743160 5715 client.go:111] DialResp not recognized; dropped" component=kube-apiserver
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.743419 5768 server.go:354] \"Stream read from frontend failure\" err=\"rpc error: code = Canceled desc = context canceled\"" component=konnectivity
Dec 06 13:40:04 frodo-ctrl-0 k0s[5682]: time="2021-12-06 13:40:04" level=info msg="E1206 13:40:04.743453 5768 server.go:354] \"Stream read from frontend failure\" err=\"rpc error: code = Canceled desc = context canceled\"" component=konnectivity
If things go bad, know that you can always reset on the newer controller node (NOT the original controller+worker node!):
root@ctrl-0:~# k0s reset
INFO[2021-12-06 13:01:43] Uninstalling the k0s service
INFO[2021-12-06 13:01:43] no config file given, using defaults
INFO[2021-12-06 13:01:43] deleting user: etcd
INFO[2021-12-06 13:01:43] deleting user: kube-apiserver
INFO[2021-12-06 13:01:43] deleting user: konnectivity-server
INFO[2021-12-06 13:01:43] deleting user: kube-scheduler
INFO[2021-12-06 13:01:43] deleting k0s generated data-dir (/var/lib/k0s) and run-dir (/run/k0s)
INFO[2021-12-06 13:01:43] k0s cleanup operations done. To ensure a full reset, a node reboot is recommended.
root@ctrl-0:~# rm -rf /etc/systemd/system/k0scontroller.service
root@ctrl-0:~# systemctl daemon-reload
You should see something like the above for removing the new controller node from the cluster.
If anything goes catastrophically wrong, remove all the new nodes and restore k0s from backup.
When you start the main node you can:
The ETCD peer address in /etc/k0s/k0s.yaml on the new node being added
k0sctl applyexternalAddress on every node individuallyThe new controller nodes need to start using the konnectivity interface one by one and make connections to the services so that they can communicate…
See the relevant issue on k0s
While I was doing this myself I had two major pieces of infrastructure go awry:
apt-get upgrade, and due to improper DKMS installation, in-kernel ZFS regressedFor this reason 10.96.0.1 was not accessible – that address is the API server itself. It seemed like Calico wasn’t pulling together the networking quite right.
crictlLearn aout and download critctl from the kubernetes-sigs/cri-tools repo.
The setup should look like this:
root@node-2 ~ # cat /etc/crictl.yaml
runtime-endpoint: unix:///run/k0s/containerd.sock
image-endpoint: unix:///run/k0s/containerd.sock
timeout: 2
debug: true
pull-image-on-create: false
It looks like calico is having the same problem as everything else, can’t connect to the API server
2021-12-07 14:45:29.823 [INFO][9] startup/startup.go 458: Hit error connecting to datastore - retry error=Get "https://10.96.0.1:443/api/v1/nodes/foo": dial tcp 10.96.0.1:443: connect: connection refused
2021-12-07 14:45:30.824 [INFO][9] startup/startup.go 458: Hit error connecting to datastore - retry error=Get "https://10.96.0.1:443/api/v1/nodes/foo": dial tcp 10.96.0.1:443: connect: connection refused
2021-12-07 14:45:31.825 [INFO][9] startup/startup.go 458: Hit error connecting to datastore - retry error=Get "https://10.96.0.1:443/api/v1/nodes/foo": dial tcp 10.96.0.1:443: connect: connection refused
2021-12-07 14:45:32.825 [INFO][9] startup/startup.go 458: Hit error connecting to datastore - retry error=Get "https://10.96.0.1:443/api/v1/nodes/foo": dial tcp 10.96.0.1:443: connect: connection refused
2021-12-07 14:45:33.826 [INFO][9] startup/startup.go 458: Hit error connecting to datastore - retry error=Get "https://10.96.0.1:443/api/v1/nodes/foo": dial tcp 10.96.0.1:443: connect: connection refused
The errors that were pointing to an issue with Calico looked like the following:
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="E1207 14:56:58.732060 363426 kuberuntime_manager.go:729] \"killPodWithSyncResult failed\" err=\"failed to \\\"KillPodSandbox\\\" for \\\"88d25b61-00cd-4940-8969-17a72f08f954\\\" with KillPodSandboxError: \\\"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\\\\\"8832012d4bbb773b4b361c6d59e1b2a75ac60e8ece9420e7b43ef33345b7c160\\\\\\\": error getting ClusterInformation: Get \\\\\\\"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\\\\\\\": dial tcp 10.96.0.1:443: connect: connection refused\\\"\"" component=kubelet
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="E1207 14:56:58.732119 363426 pod_workers.go:190] \"Error syncing pod, skipping\" err=\"failed to \\\"KillPodSandbox\\\" for \\\"88d25b61-00cd-4940-8969-17a72f08f954\\\" with KillPodSandboxError: \\\"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\\\\\"8832012d4bbb773b4b361c6d59e1b2a75ac60e8ece9420e7b43ef33345b7c160\\\\\\\": error getting ClusterInformation: Get \\\\\\\"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\\\\\\\": dial tcp 10.96.0.1:443: connect: connection refused\\\"\" pod=\"kubevirt/virt-handler-5grtb\" podUID=88d25b61-00cd-4940-8969-17a72f08f954" component=kubelet
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="time=\"2021-12-07T14:56:58.758461835+01:00\" level=error msg=\"StopPodSandbox for \\\"745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61\\\" failed\" error=\"failed to destroy network for sandbox \\\"745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61\\\": error getting ClusterInformation: Get \\\"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\\\": dial tcp 10.96.0.1:443: connect: connection refused\"" component=containerd
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="E1207 14:56:58.758643 363426 remote_runtime.go:144] \"StopPodSandbox from runtime service failed\" err=\"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61\\\": error getting ClusterInformation: Get \\\"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\\\": dial tcp 10.96.0.1:443: connect: connection refused\" podSandboxID=\"745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61\"" component=kubelet
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="E1207 14:56:58.758675 363426 kuberuntime_manager.go:958] \"Failed to stop sandbox\" podSandboxID={Type:containerd ID:745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61}" component=kubelet
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="E1207 14:56:58.758709 363426 kuberuntime_manager.go:729] \"killPodWithSyncResult failed\" err=\"failed to \\\"KillPodSandbox\\\" for \\\"c975301e-1261-4ad7-a607-c569dac68094\\\" with KillPodSandboxError: \\\"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\\\\\"745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61\\\\\\\": error getting ClusterInformation: Get \\\\\\\"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\\\\\\\": dial tcp 10.96.0.1:443: connect: connection refused\\\"\"" component=kubelet
Dec 07 14:56:58 node-3.eu-central-1 k0s[363389]: time="2021-12-07 14:56:58" level=info msg="E1207 14:56:58.758735 363426 pod_workers.go:190] \"Error syncing pod, skipping\" err=\"failed to \\\"KillPodSandbox\\\" for \\\"c975301e-1261-4ad7-a607-c569dac68094\\\" with KillPodSandboxError: \\\"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\\\\\"745155de13d48c4ad58201c13fb1e8fee02fc746a94aed96abd0cd70b127be61\\\\\\\": error getting ClusterInformation: Get \\\\\\\"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\\\\\\\": dial tcp 10.96.0.1:443: connect: connection refused\\\"\" pod=\"monitoring/node-exporter-5f4rw\" podUID=c975301e-1261-4ad7-a607-c569dac68094" component=kubelet
Every workload that needs CNI network is failing to start, all at the same time. Some of them are not failing, like kube-proxy, since it’s a fundamental part of the network setup and works somewhat at the same level of CNI, it’s not dependent on CNI running properly
Well, is this 10.96.0.1? Of course, it’s the API server, which normally sits at the very beginning of the service CIDR (my service CIDR is 10.96.0.0/12), it’s the kubernetes API server.
Looks like connections are failing to get to the kubernetes API server inside the cluster.
After HOURS of being lost, it turns out the issue is that the API server (a Service named kubernetes, inside your cluster) which lives in the default namespace had an old Endpoint:
$ kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 185d
postgres ClusterIP 10.103.44.224 <none> 5432/TCP 3d12h
There’s that address that none of the workloads can hit (10.96.0.1), and here’s the endpoints:
$ kubectl get endpoints -n default
NAME ENDPOINTS AGE
kubernetes XXX.XXX.XXX.XXX:6443 185d
postgres <none> 3d12h
With the new HA setup we’re going into, this is obviously the wrong way to access the cluster – at this point we should be using the load balancer. That address shouldn’t be XXX.XXX.XXX.XXX, it should be YYY.YYY.YYY.YYY (the new load balancer).
Changing the endpoint manually via kubectl edit endpoint kubernetes -n default was enough to fix the kubernetes service. After fixing this, every workload that was stuck was able to resolve itself.
It looks like you do sometimes get what you pay for – 3 “2 vCPU” nodes weren’t enough to run the relatively little traffic that my API server sees. I do have quite a few operators going so maybe this is reasonable but usage was spiking to 100% and 200%.
I rescaled from CPX11 to CX21s, one by one. Before scaling the usage looked like this:
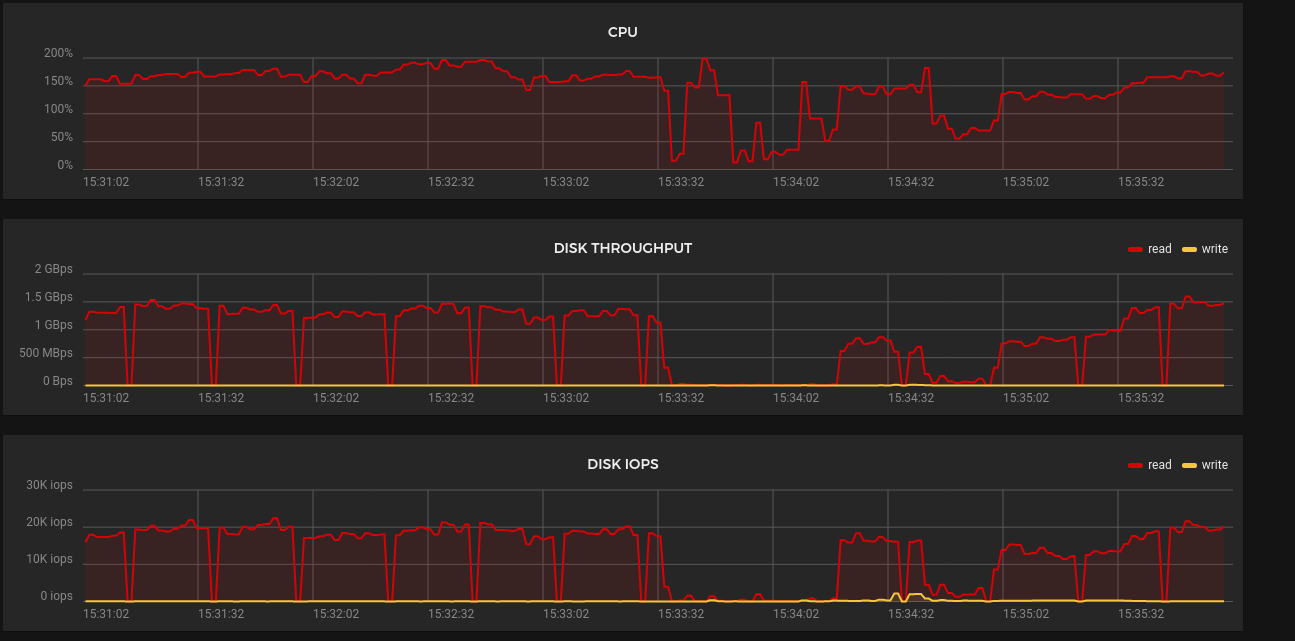
And after:
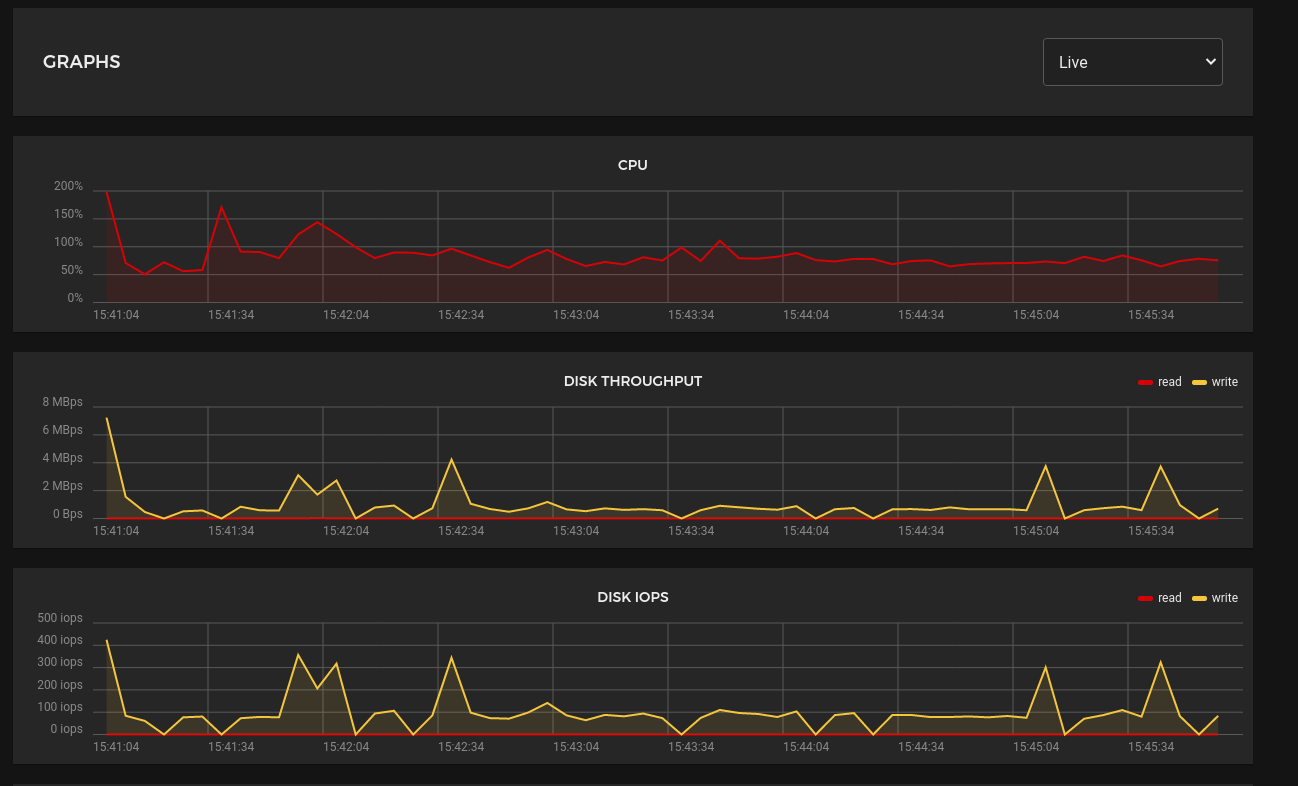
At this point I’m starting to think that I should have just gone with a single controller node after all.
At this point the TCO for this HA setup is actually around 19.60EUR (~$24 USD as of 12/08/2021):
TCO for the cheapest single node controller I could get my hands on would be:
That was the cheapest auction server I could find as of 12/08, but it does come with 8 dedicated vCores, and 32GB of RAM. Plenty powerful for a cluster of <5 worker nodes that needed to be orchestrated.
On the slightly more expensive side I could also have gone with
In retrospect I think going with the single node with server auction drives was the best choice… Technically the cheapest option is 3 nodes + load balancer, but the pain of managing 3 ETCD instances, the load balancer, and added complexity is not ideal.
You’re probably going to have to go through every workload on k8s and rollout restart them.
You’re also going to have to forcibly remove terminated but persistent pods (when a pod is 0/1 containers and stuck in Terminating but is still not gone). These can hold up long-running replicasets/deployments/daemonsets.
A lot of the time what will tip you off is that the services will not have endpoints, or there will be n-1 pods for a given DS when there are n nodes.
While working on this, it looks like there’s a bug with k8s. The symptoms look like the following:
Dec 08 14:31:46 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:46" level=info msg="I1208 14:31:46.992802 4160960 dynamic_cafile_content.go:167] Starting client-ca-bundle::/var/lib/k0s/pki/ca.crt" component=kubelet
Dec 08 14:31:46 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:46" level=info msg="I1208 14:31:46.994200 4160960 manager.go:165] cAdvisor running in container: \"/sys/fs/cgroup/cpu,cpuacct/system.slice/k0sworker.service\"" component=kubelet
Dec 08 14:31:51 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:51" level=info msg="I1208 14:31:51.999124 4160960 fs.go:131] Filesystem UUIDs: map[5fbac445-af53-40e4-a37f-975736a8d787:/dev/md2 64c368c1-5769-467e-8626-3881ba8cbe25:/dev/md1 7762831980165748493:/dev/nvme0n1p5 9b79a669-3b62-499c-a994-b068466c95af:/dev/md0 f334a003-af04-4a61-b11e-dd912d979517:/dev/zd0]" component=kubelet
Dec 08 14:31:52 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:52" level=error msg="Error while reading from Writer: bufio.Scanner: token too long" component=kubelet
Dec 08 14:31:52 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:52" level=warning msg="signal: broken pipe" component=kubelet
Dec 08 14:31:52 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:52" level=info msg="respawning in 5s" component=kubelet
Dec 08 14:31:57 node-5.eu-central-1 k0s[4057424]: time="2021-12-08 14:31:57" level=info msg=Restarted component=kubelet
Can you figure out what’s wrong there? How about where that line is coming from? Well I couldn’t, I had to actually clone the kubernetes code base so I could better search and find the issue.
The inner part of the line (Error while reading from writer) comes from kubernetes/vendor/github.com/sirupsen/logrus/writer.go. Luckily the code is pretty easy to read and understand (thanks Golang!).
Based on where the error is occurring, we can probably assume that the logger is choking on a line… that’s printed near “Filesystem UUIDs”… That we can find in the cadvisor codebase @ kubernetes/vendor/github.com/google/cadvisor/fs/fs.go (again, thanks to vendored deps in Golang). You can view the relevant line in fs.go online.
Two ideas immediately came to mind:
klog only tries to print this line if the verbosity is at least(?) level 1, so an easy way to test this is to set it to 0 and see if I can get away with itIt looks like the quick workaround for me is setting kubelet to 0 verbosity. I filed an issue against google/cadvisor and called it a day.
Well, I’m not sure who will read this eventually, but if you ever think about doing the swap from 1 controller to 3 yourself, don’t do it. Just make a new cluster, your life will be easier. Maybe while you’re there make sure your workloads are easier to migrate anyway.
For those who will ignore the advice above and try to convert the existing cluster, hopefully these notes are helpful to you. My pain, your gain.