DDG search drop in powered by ddg.patdryburgh.com
tl;dr - I used a self-hosted Baserow instance as the backend for a landing page announcing my most ambitious endeavor yet (a cloud provider called NimbusWS).
Baserow 1.7 has just been released!. Lots of big features in this new release, like Lookups (which look like a way to do JOINs) -- and someting I pontificated in this very post, webhooks!
Building landing pages is fun, but I always hesitate a little bit when it comes time to store the data that they collect (emails, product preferences, etc). In the past I’ve built lightweight SQLite-based apps, built out full apps that just happen to have the functionality to support a landing page (this is a bad idea, putting the cart before the horse), and more but I’ve never had a flow that was really well suited to lightweight pages aimed to get your early customers.
Building the ingest is easy, but back-office ergonomics are hard. You can easily POST some data over but if you want to easily peruse and maybe even modify data for yourself and other possibly non-technical users you often need to build on something like Django and make use of Django Admin (Rails also seems to have a project called RailsAdmin), etc. I’m not a fan of using languages which don’t place due emphasis on compile time type checking these days so Python/Ruby/“Plain” Javascript are out for me (even with typing and mypy) and Rails is out for me (even though sorbet exists) – this means I need to get my easy admin flows elsewhere. Note that this is the opposite of a pragmatic decision but if you’re here you hopefully already know that I am a world class yak shaver.
“No code” has been a popular buzzword lately, and like other buzzwords there’s a lot of chaff but the No-Code movement has certainly spawned a bunch of very helpful new tools for those who can code, one of those being Airtable and more related to this particular post, Baserow. Baserow is a F/OSS self-hosted Airtable alternative that makes it easy to interact with a local Postgres instance that holds your data. That’s really attractive to me becuase it means that I can in theory have my application data held in postgres, and the same databases or separate ones be served by and easily modifiable via Baserow.
So of course the next question is whether I can actually go all the way – for a landing page since we don’t need a “whole” application – what if I just use Baserow as the backend? Turns out you can, and that’s what I did, for NimbusWS’s landing page. The rest of this article is wordsoup on how I did it with the relevant code.
Before I get started I do want to note some other solutions to this problem (what I’m doing may not be the right solution for you and there are others):
I’m not going to discuss any of those other solutions (we’ll see if I switch in the future I guess!), but let’s get into how I built a simple landing page with Baserow.
tl;dr - a landing page
Recently I’ve been starting to move towards one of the biggest dreams I’ve ever dared to dream – running a cloud provider. I’ve had the sneaking suspicion that most of the giants (hardware, operating systems, programming languages, runtimes, higher level frameworks) s have gotten tall enough to make this a possibility for even a company as small as mine. I’m not quite so enthusiastic about running my own hardware in the data center just yet (so this is drastically less ambitious than something like Oxide computers), but for now what I’m focusing on is running a cloud provider that goes anywhere – as in can be used across clouds. A single cloud, across multiple providers.
I’ve the managed service provider I’m building Nimbus Web Services (“NimbusWS”) and I’m starting with Cache (redis/memcached) and Object Storage (S3-alikes), which are the simplest services I can think of. These services will run on Hetzner – the best cost/feature tradeoff cloud and dedicated server provider I’ve come across so far. As I work towards building this service, one of the things that’s smart to do (which I’ve learned the hard way of course) is to start gathering the first hundred customers who will join me for the journey – building my legacy customer base of first adopters – the OGs. Over time I’ll work towards building more services and adding more platforms to run on and of course attracting more customers, but the beginning is important, as it always is.
Lofty goals aside – I need a landing page. It struck me that while I have posted a Google form about what people want out of managed services for Hetzner and got some data – what I really need to do is collect more data via a more accessible medium and lighter signal requirement – a landing page.
There are a lot of ways this could be more streamlined, for example:
I’m not going to do any of that – we’ll be building this minimally the hard/dumb/expensive-in-the-short-term way.
tl;dr I chose the least practical option, upgrading a library I wrote myself to Parcel 2, to use from raw HTML which isn’t even server-side rendered
I deliberated a little bit on just how to make this landing page, basically my choices with my current skill set look like this:
A good question is why to do any of this at all – if all I’m trying to do is make a landing page there are a LOT of options out there which are “No-Code”:
Writing it myself is almost surely a waste of time to start with, there are tons of resources out there that will build landing pages for free/minimal cost. Of course, that’s not why this blog exists – we’re here because I like to yak shave, and sometimes for an audience. so of course, I’ve picked the least practical option – upgrading my existing landing-gear project to Parcel 2, and using the components from HTML.
For any readers earlier in their career that might read this – the choice I’ve just made is the wrong one. Mostly because it precludes SSR, but also because NextJS/NuxtJS/Svelte are the better systems to build on, and they’ll scale up to a full site as well have have larger ecosystems and all that. All I have to do is a little bit of work in another repo then build one HTML page though, how hard could that be!
So at the end of the day, what do I actually have?
Normally, even for this such a small app I’d generally build the usual 3 tier architecture:

Let’s add Baserow in there and attach it to the same DB:

With this theoretical setup we can view and edit tables as spreadsheets with Baserow. This is cool (assuming it even works), but we’ve two competing ideas on how data should be written to the DB… One of them is actually very easy to modify well for both technical and non-technical users. Like any proper database, Postgres handles multiple writers with ease and while maintaining data integrity, but Baserow is much newer software – maybe it’d be best to let Baserow do the writes so it doesn’t have to do any excessive syncing when the world changes underneath it?

And with just the move of some magic diagram arrows we’ve got writes going through Baserow rather the app making DB calls itself. This makes our app easier, and our data more accessible to non-technical people. Using Baserow as an API ensures that the writes flow through Baserow.
NOTE I’m fairly certain that writes don’t have to go through Baserow, but it’s actually quite convenient for this to happen, and it should lessen the need for Baserow to do other syncing.
This kind of setup is probably not appropriate for high throughput/complexity applications, but probably perfect for landing pages.
I’m spending some innovation tokens on the frontend with Parcel 2 so I’ll try to resist getting too fancy with the backen – maximum productivity with minimal safety. For me this means:
If you’re following along at home for some reason – Baserow does have a free-for-now online version @ https://baserow.io and you can set it up yourself. I’ve set it up myself so I already went through the following steps:
NimbusWS)leads)After you do all this, you should have an API key that looks something like this:
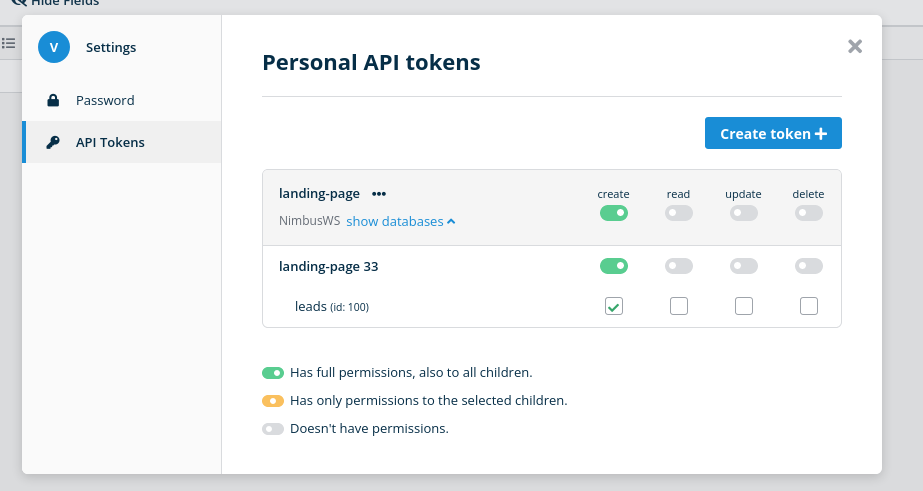
Obviously we’ll need a few things to be able to interact with the Baserow API:
12 factor apps are the way to live, so ENV is my config weapon of choice here, let’s have the following:
BASEROW_HOSTBASEROW_PORTBASEROW_API_TOKENHere’s a smattering of code that makes it happen:
// (somewhere near where you manage your types)
export interface BaserowInstance {
host: string;
port: parseInt;
apiKey: string;
}
// (in your code somewhere before the server starts) Gather baserow instance config
const baserow: BaserowInstance = {
host: process.env.BASEROW_HOST ?? Constants.DEFAULT_BASEROW_HOST,
port: parseInt(process.env.BASEROW_PORT || `${Constants.DEFAULT_BASEROW_PORT}`, 10),
apiKey: process.env.BASEROW_API_KEY ?? Constants.DEFAULT_BASEROW_API_KEY,
};
I’ll do a tiny tiny bit of yak shaving here so this project is much more reusable for me in the future – it just makes sense to make this endpoint a little dynamic, since the baserow API key is tied to a single user and group:
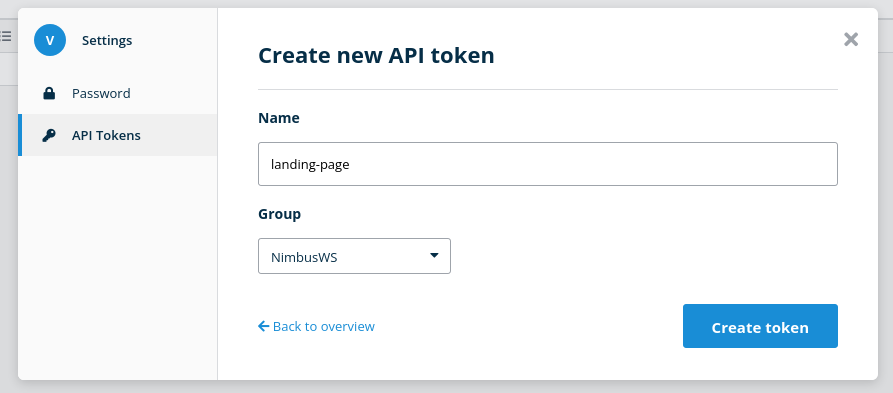
But there are many more layers to actually creating a record – we need the DB and table name – but those would be a shame to hardcode. We should be able to get away with an endpoint like this:
PUT /api/databases/:databaseName/tables/:tableName
An endpoint like that and we don’t have to specify the database and table names up front! Turns out we don’t even need to do this much because Table IDs happen to be unique, so the appropriate endpoint only needs the table ID. Let me just give you the real code:
// Generic endpoint that passes things through to baserow
app.put(
"/tables/:tableId",
async (req: RequestWithBody<any>, res: Response) => {
try {
// If baserow information wasn't specified, return early
if (!baserow?.host) {
logger?.error("baserow not configured properly");
res.status(500).send({ status: "error" });
return;
}
logger?.info(`received write to baserow: ${JSON.stringify(req.body)}`);
// Attempt to parse the table ID into a number
const tableId = parseInt(req.params.tableId, 10);
if (typeof tableId !== "number") {
logger?.error(`invalid table ID submitted: ${JSON.stringify(req.params.tableId)}`);
res.status(400).send({ status: "error" });
return;
}
// Make request to Baserow
await baserowAxios.post(
`/api/database/rows/table/${tableId}/`,
req.body,
{
params: { user_field_names: "true" },
},
);
res.json({ status: "success" });
return;
} catch (err: any) {
logger?.error(`error processing table write: ${err?.message}`);
// Attempt to retreive response data from the error
const responseData = err?.response?.data;
if (responseData) {
logger?.error(`response.data? ${JSON.stringify(responseData, null, ' ')}`);
}
res
.status(err?.response?.statusCode ?? 500)
.json({ status: "error" });
}
},
);
There’s a bit more that you could do here, like resolving table names to IDs dynamically at the API layer but I’ve chosen to just have the frontends know what the IDs of the databases are.
Of course, as all simple sounding things go, a bunch of little things went wrong, and you’re getting the post-suffering code that worked free of charge!
user_field_namesMake sure to set user_field_names so you can use field names as keys in the objects you pass. Not sure why this isn’t the default but field_<Field ID> was probably the first thing they started with or something?
axios/node-fetch!The following code:
// Build axios instance for
const baserowAxios = axios.create({
baseURL: baserow.host,
headers: {
"Authorization": `Token ${baserow.apiKey}`,
},
});
// ... and later ...
// Make request to Baserow
const response = await axios.post(
`${baserow.host}/api/database/rows/table/${tableId}`,
req.body,
{ params: { user_field_names: "true" }},
);
logger?.info(`received response from Baserow: ${util.inspect(response)}`);
Does not work and will result in a request that looks like this (if you console.log(util.inspect(response))):
socketPath: undefined,
method: 'GET',
maxHeaderSize: undefined,
insecureHTTPParser: undefined,
path: '/api/database/rows/table/101/?user_field_names=true',
_ended: true,
res: IncomingMessage {
_readableState: [ReadableState],
The request does not succeed, despite returning a 200 – it gets turned into a GET for some reason.
The fix is to make sure a trailing slash is specified like so:
await baserowAxios.post(
`/api/database/rows/table/${tableId}/`, // <--- Here's that trailing slash
data,
{ params: { user_field_names: "true" } },
);
node-fetch over axios)Typescript is the best scripting language (i.e. Ruby, Python, Perl, etc) by far, in my opinion. One of the best things about Typescript is that Javascript below it changes and has some good decisions baked in (simplicity of the single threaded runtime assumption, first class functions, prototypal inheritance over class-based inheritance). They’re not all good decisions but there are some pretty big stumbling blocks – Java didn’t have first-class funtions until Java 1.8 despite them being suggested in 1.1 IIRC.
Anyway, the “lower level” javascript language also tacks on features and has a rapidly moving ecosystem so you often get lots of experimentation (some of it being ultimately useful). It can be insane to be a part of because of just how vibrant and energetic (and wrong, sometimes) the community is, but the fact that someone made Coffeescript (which was contentious) enabled someone else to make Typescript down the road.
The benefit of a rapidly moving ecosystem is a double edged sword – and it showed itself with using ESM modules. Just to import and use node-fetch in a manner that used to work perfectly fine, I had to dig into the world of making Typescript ESM imports work, which leads to a nonsensical importing of .js files from a .ts file. Resources that helped:
I should probably really dig down deep and understand fully exactly why I should be excited about the ESM module changes but I guess I’m just not that much of a diehard JS developer. I’m sure I’ll get to it someday.
nullsFirst of all, there doesn’t seem to be constraint configuration ability in Baserow yet (and IDs are numeric and not based on a given column), so it’s possible to put in two rows with the same email for example. Along with the duplicates, you have to be really careful that data which gets through has non-null fields, because completely undefined stuff WILL cause new row inserts – all columns are nullable by default.
If you choose to use a “multi select” on the Baserow side, you must convert the entries to their foreign key IDs – unfortunately what Baserow understands right now is an array of PKs, despite the fact that underlying Postgres supports:
text[] (simple text array) columnsjsonb columnshstore columnsI needed to add a function to do the conversion, which wasn’t a huge deal but was a little inconvenient. The ideal solution might be if Baserow supported ENUM types on the backend and used <enum_type>[] (enum arrays), but this workaround isn’t too bad (I should probably donate to Baserow if I want to see the other things happen sooner rather than later!).
You can generally find all the PKs in the generated documentation (which is very handy!) for your table (you can view documentation from the API key creation pane).
Just because you can, doesn’t mean you should – In the end I was a little uncomfortable just letting Baserow have near direct access to the outside world (and passing req.body straight through to Baserow), so you probably do want to do some schema validation (see the next section) at the API layer. I haven’t done a security audit of Baserow, I assume they follow basic security hygiene like using parametrized queries and things like that, but if I haven’t looked then I probably shouldn’t risk it.
I’ll cover what I actually did in the next section
Unfortunately simply baking your Baserow Table IDs into the frontend is pretty fragile – on the plus side you can pre-compile your front end (a completely static distribution), but obviously you have to completely rebuild and redeploy the application to change this – kind fo a bummer for staging environments (where you ideally want to deploy the exact same container image to all environments).
One of the common things you’d want to do is be able to make and test a staging environment — you’d think you could do the following:
staging-<the table name> but it actually doesn’t matter, since the ID identifies the table in our setup)You’d be right but if you use a multi-select or anything that uses foreign keys, you will run into an issue foreign keys are different across databases. That’s an obvious fact, but as far as I know there’s no simple way to get enum mappings for various values (this is probably possible through the API if you know what the multi-select is called), which is a bit of a pain.
There’s actually no good, easy solution for this, so I’ve just used the exact same database for staging and production (which is a horrible idea of course, but the staging environment actually won’t even be up long). As far as complex solutions go, you could create an ENV-driven translation layer for your multi-select values (ex. something like MULTI_SELECT_X=value:122,another:123)… But I’m not going to do that. As I’d discussed before, some better ENUM support would be fantastic (or even just support for Postgres ARRAY).
PRIVATE_BACKEND_URL if you use a non-public URL from your APIThe Baserow documentation covers this explicitly but I forgot while I was deploying and spent some time wondering why I was getting 400s.
If you’re going to access the Baserow isntance’s API (backend) through a non-public URL, you must specify the PRIVATE_BACKEND_URL ENV variable, otherwise your requests will return a 400 (with no further useful information). So you might have a PUBLIC_BACKEND_URL of https://baserow.mycloudprovider.tld/backend (in this scenario you have a load balancer that terminates TLS and forwards /backend/* to Baserow’s backend), but if on your cloud provider you’re going to be accessing your instance @ baserow.internal.local, then you want to set PRIVATE_BACKEND_URL to http://baserow.internal.local:8000 (your backend API is hitting baserow’s backend directly).
Make sure to set both PRIVATE_BACKEND_URL and PUBLIC_BACKEND_URL.
With what we’ve discussed so far we’re taking an incoming request from frontend (text traveling in a HTTP request body), and after bodyParser is done with it feeding it straight through to Baserow. That should make you feel a little uncomfortable (if it doesn’t consider thinking a little more about the security aspect of things!). I can cut down on the likelihood of a malicious payload coming in by at the very least doing some validation.
We could easily add some JSON Schema based validation or server-side validation to compliment Baserow though, so let’s do something since we do have Typescript handy! I wanted to use ts-interface-builder which I’ve been meaning to try out, but it feels like overkill here so we’ll do some very simple validation:
type ServiceFK = number
interface EarlyAccessRequestBody {
email: string;
services: ServiceFK[];
}
function isEarlyAccessRequestBody(obj: any): obj is EarlyAccessRequestBody {
return obj
&& typeof obj === 'object' && Object.keys(obj).length === 2
&& "email" in obj && obj.email && typeof obj.email === "string"
&& "services" in obj && obj.services && Array.isArray(obj.services);
}
// ... down where you have the actual handler code ...
// PUT /early-access
app.put(
"/early-access",
async (req: RequestWithBody<EarlyAccessRequestBody>, res: Response) => {
try {
// Ensure request body is valid
if (!isEarlyAccessRequestBody(req.body)) {
res
.status(400)
.json({
status: "error",
message: "Invalid request",
})
return;
}
logger?.info(`received early access signup: ${JSON.stringify(req.body)}`);
const data = {
email: req.body.email,
services: req.body.services,
};
// Make request to Baserow
const response = await baserowAxios.request({
method: "POST",
url: `/api/database/rows/table/${baserow.earlyAccessTableID}/`,
data,
params: { user_field_names: true },
});
logger?.info(`received response from baserow: ${JSON.stringify(response.data)}`);
res.send({ status: "success" });
return;
} catch (err: any) {
logger?.error(`error processing early access signup: ${err?.message}`);
logger?.error(`response? signup: ${JSON.stringify(err?.response, null, ' ')}`);
res
.status(500)
.json({ status: "error" });
}
},
)
Very simple code there to validate the request body that get by bodyParser and ends up in the handler. There is some more low-hanging fruit there – ServiceFK could be more strictly checked, etc.
In the future ts-interface-builder would be a marked improvement and might even be nice as a Parcel Transformer plugin (maybe one that looked for every types.ts file?) but for now, let’s move on since we have at least a smidge of validation at least.
Always good to at least consider security up front – apart from the obvious things like serving over HTTPS (thanks to LetsEncrypt), and closing ports, firewalls and all that stuff, the two important specific web security bits we’ll need to think about are CORS and CSRF.
We’ll want to at least use CORS, as we don’t want people AJAX PUT-ing to our site from random places at the very least. Normally this would be the spot for helmet or a similar library:
BUT since I’m running Traefik in front of the app, it’s way easier to set up my CORS options (unfortunately Traefik does not make CORS easier to understand, just easier to modify):
---
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: example-traefik-middleware
namespace: default
spec:
headers:
forceSTSHeader: true
stsPreload: true
contentTypeNosniff: true
browserXssFilter: true
stsIncludeSubdomains: true
stsSeconds: 63072000
frameDeny: true
sslRedirect: true
contentSecurityPolicy: |
default-src 'none';form-action 'none';frame-ancestors 'none';base-uri 'none'
accessControlAllowMethods: # <-- Here's the important bit!
- "PUT"
accessControlAllowOriginList:
- "https://baserow.domain.tld"
accessControlMaxAge: 100
addVaryHeader: true
referrerPolicy: "same-origin"
NOTE CORS only applies to calls from JS! So if our endpoint was actually a GET or POST forms on other sites on the internet could attempt to use it. There’s a great resource out there on CSRF I recommend reading through. Since forms can’t PUT I should be good with CORS on the endpoint. PUT also generally makes semantic sense so I don’t mind – I really am only allowing the PUT operation.
Even though we won’t be needing it now, assuming we were using a normal HTML form and/or POST request, a good way to protect ourselves from other websites abusing this endpoint would be via Cross Site Request Forgery (protection) – CSRF:
We have a few options in the ecosystem for easily implementing CSRF protection even though we won’t:
There’s not so much of a benefit to implementing CSRF protection if we have CORS set and are using an API driven approach (someone could easily automate doing a request to grab a CSRF token before doing the POST or whatever), so CORS is enough for now.
And just like that (with the magic of editing like on a cooking show), the site is complete! A quick recording to show things working and what it looks like to interact with:
And of course the Enterprise support option also works:
(You can see where I get confused because the right alert didn’t show up! don’t worry, that’s fixed in the published version).
One thing I personally like is being able to get an email when people sign up. A notification subsystem would be a cool feature for Baserow itself but for now I’ll add it on the server side. It’s a snap with nodemailer (the silent hero of the NodeJS email ecosystem). I’ll leave the implementation as an exercise for you, dear reader.
NOTE A “Notification subsystem” did get added to Baserow 1.7
Baserow API keys table permissions can be created so one of the things you could actually do is expose the whole Baserow API to the frontend application itself. I’m not sure just how well Baserow is built security wise so it’s a bit unwise to hit the internet with such a wide attack vector, but it’s certainly an interesting prospect in the future – outside of people making spurrious entries, it seems like a create-only key with very limited database permissions could work perfect for powering survey sites, sites like Typeform, etc.
Since this isn’t just a marketing post for NimbusWS I wanted to share another thought I had – the nice thing about using a “proper” database with constraints and data integrity guarantees is that you can use other tools that are built without worrying that they’ll write bad data. What I’m getting at is that I could actually spin up an instance of PostgREST, an automatic API for Postgres databases to interact with the database powering Baserow!
With the right settings (ensuring the DB user is not a super user, cannot delete, etc) I can expose this right on the internet with appropriate security (CORS +/- CSRF) and have my requests go straight to PostgREST. I won’t do that in this post but it might be a fun exercise for any of those with a bit too much time on their hands at home.
By combining these tools a pretty nice flow has emerged for me. Getting the landing page up was fantastic, and finally getting a chance to kick the tires on Baserow today and seeing how useful it can be has been fantastic, and hopefully this post gives people ideas for how to use this “no code” tool as a very useful and attractive “less code” tool.