DDG search drop in powered by ddg.patdryburgh.com
tl;dr - In order to test storage performance I set up a completely automated test bed for all the storage plugins, this article chronicles the installations of some of the plugins. It’s particularly long because I made lots of mistakes. Mostly useless sections are prefaced with a notice on why you can skip them, skim the ToC and click on anything you like.
The GitLab repository is up! You can skip this entire article and just go there.
NOTE: This a multi-part blog-post!
In part 1 we got some nice automation for server set up, pre-requisite installation and Kubernetes install. Now it’s time to install the storage plugins themselves so we can get to testing them.
Cluster operators will probably gain the most insight (if any) here, whereas Sysadmins might have liked Part 1 better.
OK, so we’ve got a machine that’s ready, and a k8s cluster (of one, for now) install that is purring along, time to actually install the relevant storage provider(s).
This is where things get spicy, and other cluster operators may find some insights.
STORAGE_PROVIDER=rook-ceph-lvmJust a heads up, you should skip/skim this LVM section if you don’t want to wade through me making almost every possible mistake in the book getting Ceph running, generally the only legitimate issue I ran into that isn’t attributable to user error in some way was downgrading to 15.2.6 to avoid issues with handling partitions. (Ceph recently changed how
ceph-volume batchworks).Reading the titles for the subsections should be enough to get an idea of what I had to change. Maybe refer to these sections if and only if you have issues down the road installing Ceph yourself.
Assuming you provisioned drives correctly (I have one drive free and 1 large partition as a result of the setup scripts), the basic rook simple is real easy, just install the operator with some curl | kubectl apply command right? Nope, we do things the hard way here – My first step when installing software is to decompose the large all-in-one YAML that comes and make some reasonably named pieces. A look at the actual pieces of a Rook install:
$ tree .
.
├── 00-rook-privileged.psp.yaml
├── cephblockpool.crd.yaml
├── cephclient.crd.yaml
├── cephcluster.crd.yaml
├── cephfilesystem.crd.yaml
├── cephnfs.crd.yaml
├── cephobjectrealm.crd.yaml
├── cephobjectstore.crd.yaml
├── cephobjectstoreuser.crd.yaml
├── cephobjectzone.crd.yaml
├── cephobjectzonegroup.crd.yaml
├── cephrbdmirror.crd.yaml
├── default.rbac.yaml
├── Makefile
├── objectbucketclaim.crd.yaml
├── objectbucket.crd.yaml
├── rook-ceph-admission-controller.rbac.yaml
├── rook-ceph-admission-controller.serviceaccount.yaml
├── rook-ceph-cmd-reporter.rbac.yaml
├── rook-ceph-cmd-reporter.serviceaccount.yaml
├── rook-ceph-mgr.rbac.yaml
├── rook-ceph-mgr.serviceaccount.yaml
├── rook-ceph.ns.yaml
├── rook-ceph-operator-config.configmap.yaml
├── rook-ceph-operator.deployment.yaml
├── rook-ceph-osd.rbac.yaml
├── rook-ceph-osd.serviceaccount.yaml
├── rook-ceph-system.rbac.yaml
├── rook-ceph-system.serviceaccount.yaml
├── rook-csi-cephfs-plugin-sa.rbac.yaml
├── rook-csi-cephfs-plugin-sa.serviceaccount.yaml
├── rook-csi-cephfs-provisioner-sa.rbac.yaml
├── rook-csi-cephfs-provisioner-sa.serviceaccount.yaml
├── rook-csi-rbd-plugin-sa.rbac.yaml
├── rook-csi-rbd-plugin-sa.serviceaccount.yaml
├── rook-csi-rbd-provisioner-sa.rbac.yaml
├── rook-csi-rbd-provisioner-sa.serviceaccount.yaml
└── volume.crd.yaml
The files in the list above do contain some combined resource files (ex. .rbac.yaml files have applicable Role, ClusterRole, RoleBinding and ClusterRoleBindings in them). Note that I have left out a CephCluster object, and CephBlockPools and StorageClass objects as well.
CephFilesystemMirror)? Nope, I downloaded the wrong resourcesMy first try to get this stuff installed resulted in some errors on the operator side:
$ k logs rook-ceph-operator-868df94867-xpm4p
... happy log messages ...
2021-04-01 08:57:16.696834 E | operator: gave up to run the operator. failed to run the controller-runtime manager: no matches for kind "CephFilesystemMirror" in version "ceph.rook.io/v1"
failed to run operator
: failed to run the controller-runtime manager: no matches for kind "CephFilesystemMirror" in version "ceph.rook.io/v1"
OK, looks like I missed a CRD – CephFilesystemMirror needs to be installed and isn’t (btw it’s super awesome that Rook supports the relatively new RBD mirroring features of ceph). But why wasn’t CephFilesystemMirror in crds.yaml? Not sure but I found the CRD under the pre 1.16 folder…
Was I on the right version? Well it turns out I downloaded the wrong version (off of master) of the YAML needed – version 1.5.9 is what I wanted to get. After fixing that things got much better:
$ k get pods
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-4ghbn 0/3 ContainerCreating 0 13s
csi-cephfsplugin-provisioner-5bcd6dc5bb-tgrhj 6/6 Running 0 13s
csi-rbdplugin-f9r4p 0/3 ContainerCreating 0 14s
csi-rbdplugin-provisioner-64796f88cb-9xdtz 7/7 Running 0 14s
rook-ceph-agent-nf4cp 1/1 Running 0 38s
rook-ceph-operator-757bbbc4c6-mw4c4 1/1 Running 0 45s
No mention of the CephFilesystemMirror, and lots more activity going on with new pods being created.
allowMultiplePerNode to true Another issue that came up was mon (Monitor) pods not being able to be duplicated on the same machine (since the default setting is 3, and there’s only one node, they all go on the same node):
$ k logs rook-ceph-operator-757bbbc4c6-mw4c4
... happy log messages ....
2021-04-01 09:19:25.433006 I | ceph-cluster-controller: reconciling ceph cluster in namespace "rook-ceph"
2021-04-01 09:19:25.435642 I | ceph-cluster-controller: clusterInfo not yet found, must be a new cluster
2021-04-01 09:19:25.448532 E | ceph-cluster-controller: failed to reconcile. failed to reconcile cluster "rook-ceph": failed to configure local ceph cluster: failed to perform validation before cluster creation: cannot start 3 mons on 1 node(s) when allowMultiplePerNode is false
OK, great, this issue is fairly simple to understand – the CephCluster I made needs to have allowMultiplePerNode (which refers to monitors, no idea why they wouldn’t just name this allowMultipleMonsPerNode) needs to be set to true. Generally there is expected to be one mon per node, so I only need one.
/var/lib/kubelet folders (issue with k0s)NOTE This section is me solving this problem (the missing dirs) the wrong way. Do not just add the folders/make sure they’re there – the folders do get created properly in /var/lib/k0s/kubelet
I ran into another issue – after setting allowMultiplePerNode to true (which you can see in the logs), everything looks OK, except two plugin pods are stuck in ContainerCreating:
$ k get pods
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-4ghbn 0/3 ContainerCreating 0 25m
csi-cephfsplugin-provisioner-5bcd6dc5bb-tgrhj 6/6 Running 0 25m
csi-rbdplugin-f9r4p 0/3 ContainerCreating 0 25m
csi-rbdplugin-provisioner-64796f88cb-9xdtz 7/7 Running 0 25m
rook-ceph-agent-nf4cp 1/1 Running 0 25m
rook-ceph-crashcollector-all-in-one-01-69797d9bdc-p4lwh 1/1 Running 0 17m
rook-ceph-mgr-a-56d6dc845c-lbrh2 1/1 Running 0 17m
rook-ceph-mon-a-6fb56d8474-24zfg 1/1 Running 0 18m
rook-ceph-mon-b-64cf75db46-nmxc5 1/1 Running 0 18m
rook-ceph-mon-c-777449bf5b-596jh 1/1 Running 0 17m
rook-ceph-operator-757bbbc4c6-mw4c4 1/1 Running 0 26m
Let’s look at rbdplugin first (we won’t be using CephFS for this experiment anyway):
$ k describe pod csi-rbdplugin-f9r4p
... other information ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 31m default-scheduler Successfully assigned rook-ceph/csi-rbdplugin-f9r4p to all-in-one-01
Warning FailedMount 31m kubelet MountVolume.SetUp failed for volume "plugin-mount-dir" : hostPath type check failed: /var/lib/kubelet/plugins is not a directory
Warning FailedMount 29m kubelet Unable to attach or mount volumes: unmounted volumes=[registration-dir pods-mount-dir], unattached volumes=[plugin-mount-dir ceph-csi-config keys-tmp-dir plugin-dir registration-dir rook-csi-rbd-plugin-sa-token-zgn8d pods-mount-dir host-run-mount host-dev host-sys lib-modules]: timed out waiting for the condition
Warning FailedMount 27m kubelet Unable to attach or mount volumes: unmounted volumes=[pods-mount-dir registration-dir], unattached volumes=[pods-mount-dir plugin-mount-dir rook-csi-rbd-plugin-sa-token-zgn8d lib-modules plugin-dir keys-tmp-dir ceph-csi-config host-run-mount registration-dir host-dev host-sys]: timed out waiting for the condition
Warning FailedMount 24m kubelet Unable to attach or mount volumes: unmounted volumes=[pods-mount-dir registration-dir], unattached volumes=[host-sys keys-tmp-dir rook-csi-rbd-plugin-sa-token-zgn8d pods-mount-dir host-dev ceph-csi-config host-run-mount plugin-dir registration-dir plugin-mount-dir lib-modules]: timed out waiting for the condition
Warning FailedMount 11m (x3 over 15m) kubelet (combined from similar events): Unable to attach or mount volumes: unmounted volumes=[registration-dir pods-mount-dir], unattached volumes=[lib-modules registration-dir rook-csi-rbd-plugin-sa-token-zgn8d host-sys ceph-csi-config keys-tmp-dir plugin-mount-dir host-dev host-run-mount plugin-dir pods-mount-dir]: timed out waiting for the condition
Warning FailedMount 4m52s (x20 over 31m) kubelet MountVolume.SetUp failed for volume "pods-mount-dir" : hostPath type check failed: /var/lib/kubelet/pods is not a directory
Warning FailedMount 48s (x23 over 31m) kubelet MountVolume.SetUp failed for volume "registration-dir" : hostPath type check failed: /var/lib/kubelet/plugins_registry/ is not a directory
It looks like the /var/lib/kubelet/plugins directory is not present and expected to be there. This is something I might have expected k0s to put in… And indeed it is there?
root@all-in-one-01 ~ # tree /var/lib/kubelet
/var/lib/kubelet
├── device-plugins
│ ├── DEPRECATION
│ └── kubelet.sock
└── plugins
├── rook-ceph.cephfs.csi.ceph.com
└── rook-ceph.rbd.csi.ceph.com
4 directories, 2 files
Very weird… OK let’s ignore that event and assume it got resolved. The other folders /var/lib/kubelet/pods and /var/lib/kubelet/plugins_registry both do not actually exist – I’ll add the folders manually for now and kill the pod and see what happens.
That seems to have fixed the problem:
$ k get pods
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-4ghbn 0/3 ContainerCreating 0 37m
csi-cephfsplugin-provisioner-5bcd6dc5bb-tgrhj 6/6 Running 0 37m
csi-rbdplugin-provisioner-64796f88cb-9xdtz 7/7 Running 0 37m
csi-rbdplugin-x785n 3/3 Running 0 3s
rook-ceph-agent-nf4cp 1/1 Running 0 38m
rook-ceph-crashcollector-all-in-one-01-69797d9bdc-p4lwh 1/1 Running 0 29m
rook-ceph-mgr-a-56d6dc845c-lbrh2 1/1 Running 0 29m
rook-ceph-mon-a-6fb56d8474-24zfg 1/1 Running 0 30m
rook-ceph-mon-b-64cf75db46-nmxc5 1/1 Running 0 30m
rook-ceph-mon-c-777449bf5b-596jh 1/1 Running 0 30m
rook-ceph-operator-757bbbc4c6-mw4c4 1/1 Running 0 38m
Adding the missing folders has solved both CSI pod ContainerCreating issues so it looks like there’s an undocumented (or maybe it was documented and I didn’t see it?) requirement on these folders to exist on the host machine. I filed a bug so hopefully it’s an easy fix.
NOTE Again, this is not the way to fix this**
All the containers are running now, let’s take a step back and remember how many OSDs we expect to have – 1 OSD for the remaining space on the primary OS disk and 1 OSD for the second disk. We should have two pieces of storage (a partition and a whole disk), and 1 OSD for each of those pieces of storage. I have useAllNodes: true and useAllDevices: true set in the Cluster configuration, so Rook should be able to pick up these two pieces automatically.
Let’s see if the Ceph Dashboard matches our expectations (note that the port used is 7000 when TLS is turned off!):
$ k port-forward svc/rook-ceph-mgr-dashboard :7000 -n rook-ceph
I am greeted with the Ceph Dashboard login:
OK cool, but what’s the password? Well you can get that from the rook-ceph-dashboard-password secret:
$ export CEPH_PASSWORD=`kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo`
$ echo $CEPH_PASSWORD
With the username admin and the password, I am greeted with this:
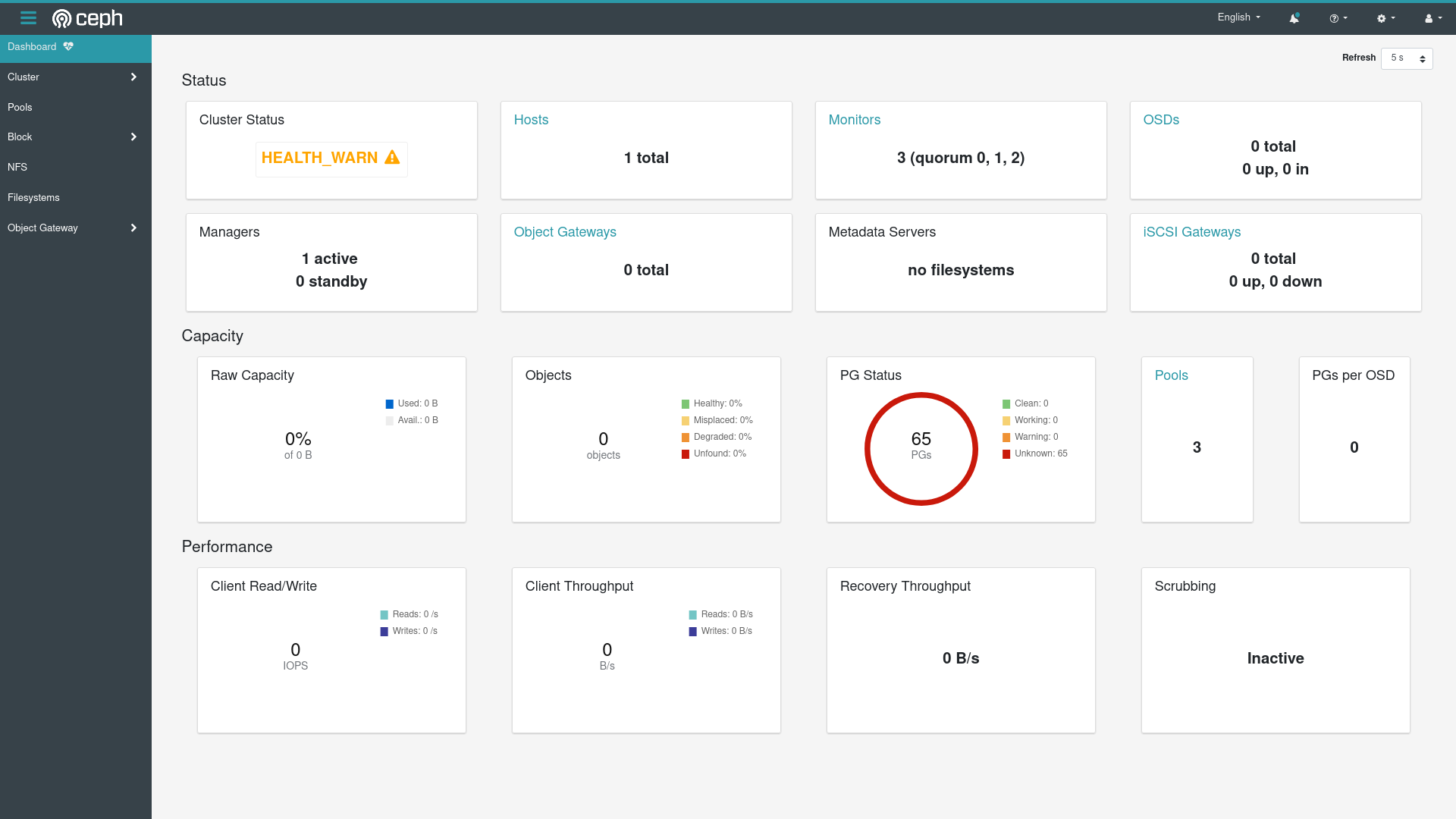
OK at least having the monitors in a quorum is good, but Ceph definitely still isn’t completely up – there are no OSDs.
Clicking around I get a lot of incomplete data and suggestions to install the Ceph Orchestrator… Rook doesn’t have docs on how to do this just yet so I’ll leave it off for now, though it’s also a bit weird that I’d use the rook module to manipulate rook from inside ceph… When I’ve installed Rook so it can manage Ceph!
Anyway, looks like the host I’m on has no devices so my fears about the OSDs are true – Ceph doesn’t know about any of the disk space I’m trying to give it:
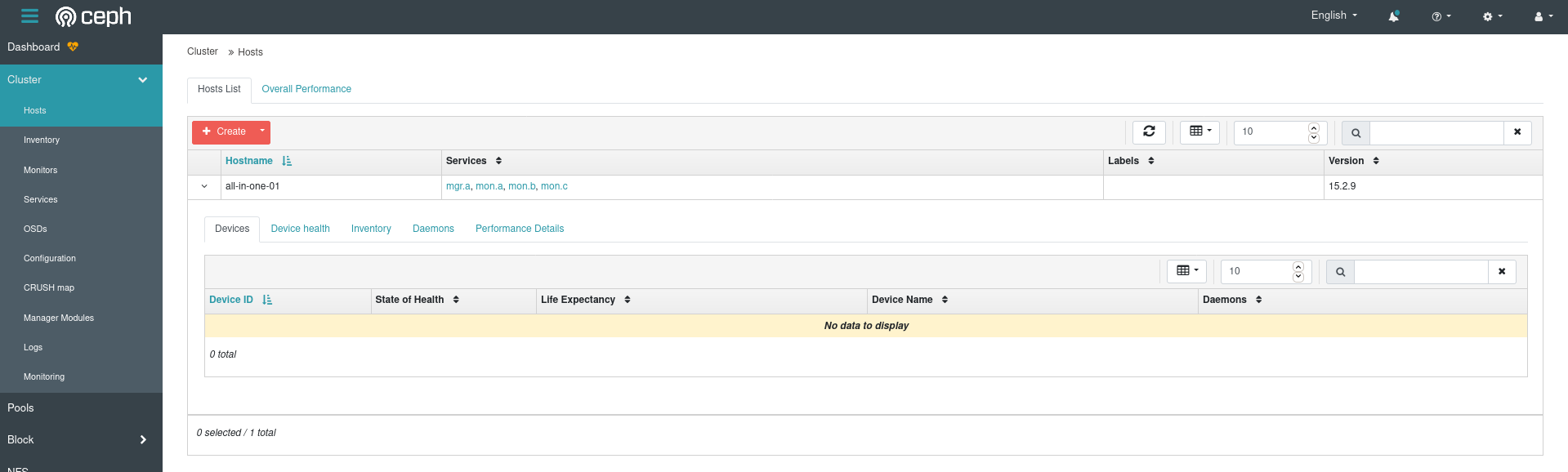
Since I’m pretty well aware of what I want my devices to look like, I’ll try specifying them explicitly in the Cluster config, and changing that:
nodes:
- name: "all-in-one-01"
devices:
- name: "nvme1n1" # hard-coded values are bad...
- name: "nvme1n1p5" # this is also bad...
(NOTE, there is a typo, nvme1n1p5 should be nvme0n1p5)
After ~30 seconds the dashboard kicked me out and I had to set up the port-forward again which is probably a good sign (the config reloaded, I assume) – unfortunately the problems were not gone, Cluster was still in health warn status:
PG_AVAILABILITY: Reduced data availability: 65 pgs inactive
POOL_NO_REDUNDANCY: 1 pool(s) have no replicas configured
TOO_FEW_OSDS: OSD count 0 < osd_pool_default_size 3
Looking at the host I still see no devices. I can see the following errors:
2021-04-01 10:47:59.205336 E | op-osd: timed out waiting for 1 nodes: &{values:map[all-in-one-01:{}]}
2021-04-01 10:47:59.222434 E | ceph-cluster-controller: failed to reconcile. failed to reconcile cluster "rook-ceph": failed to configure local ceph cluster: failed to create cluster: failed to start ceph osds: 1 failures encountered while running osds on nodes in namespace "rook-ceph". timed out waiting for 1 nodes: &{values:map[all-in-one-01:{}]}
... more logs that are generally informational ....
There should definitely be some more information in that all-in-one-01:{} area… Taking a look at the list of pods, I see that the OSD pods that Rook is supposed to create are just not there. I got lucky and caught one of the pods doing some setup:
$ k get pods
k logs NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-4ghbn 3/3 Running 0 92m
csi-cephfsplugin-provisioner-5bcd6dc5bb-tgrhj 6/6 Running 0 92m
csi-rbdplugin-provisioner-64796f88cb-9xdtz 7/7 Running 0 92m
csi-rbdplugin-x785n 3/3 Running 0 54m
rook-ceph-agent-nf4cp 1/1 Running 0 92m
rook-ceph-crashcollector-all-in-one-01-69797d9bdc-p4lwh 1/1 Running 0 84m
rook-ceph-mgr-a-56d6dc845c-lbrh2 1/1 Running 0 84m
rook-ceph-mon-a-6fb56d8474-24zfg 1/1 Running 0 85m
rook-ceph-mon-b-64cf75db46-nmxc5 1/1 Running 0 85m
rook-ceph-mon-c-777449bf5b-596jh 1/1 Running 0 84m
rook-ceph-operator-757bbbc4c6-mw4c4 1/1 Running 0 93m
rook-ceph-osd-prepare-all-in-one-01-rjzbn 0/1 CrashLoopBackOff 4 3m3s
That pod had a nice error message inside it for me:
$ k logs -f rook-ceph-osd-prepare-all-in-one-01-rjzbn
... other log messages ...
could not get the node for topology labels: could not find node "all-in-one-01" by name: nodes "all-in-one-01" is forbidden: User "system:serviceaccount:rook-ceph:rook-ceph-osd" cannot get resource "nodes" in API group "" at the cluster scope
OK, so I seem to have messed up some RBAC, I’m missing some Role/ClusterRole from common.yaml, in particular a combination that would have given the OSD pods access to operations on Node objects. Looks like what I needed/missed was the rook-ceph-osd ClusterRole.
CephClustersIn an attempt to trigger the prepare- job above again I deleted and re-created the CephCluster and I definitely didn’t enjoy that. basically everything broke, I had to wait for mons to regain quorum, the dashboard service went down all together (and never came back up), etc. It was a big PITA, I should have just changed a label or something to get things to flush. Be particularly careful doing this – maybe it’s just that my configuration was still wrong but the logs look pretty not great:
2021-04-01 10:59:40.806656 I | op-mon: parsing mon endpoints:
2021-04-01 10:59:40.806670 W | op-mon: ignoring invalid monitor
2021-04-01 10:59:40.812130 I | cephclient: writing config file /var/lib/rook/rook-ceph/rook-ceph.config
2021-04-01 10:59:40.812254 I | cephclient: generated admin config in /var/lib/rook/rook-ceph
2021-04-01 10:59:40.882237 E | ceph-cluster-controller: failed to get ceph daemons versions, this typically happens during the first cluster initialization. failed to run 'ceph versions'. unable to get monitor info from DNS SRV with service name: ceph-mon
[errno 2] RADOS object not found (error connecting to the cluster)
. : unable to get monitor info from DNS SRV with service name: ceph-mon
[errno 2] RADOS object not found (error connecting to the cluster)
There were some more errors in the manager:
2021-04-01 11:09:49.473315 I | cephclient: generated admin config in /var/lib/rook/rook-ceph
2021-04-01 11:10:04.560250 E | ceph-cluster-controller: failed to get ceph daemons versions, this typically happens during the first cluster initialization. failed to run 'ceph versions'. timed out
. : timed out
.
2021-04-01 11:10:04.560277 I | ceph-cluster-controller: cluster "rook-ceph": version "15.2.9-0 octopus" detected for image "ceph/ceph:v15.2.9"
2021-04-01 11:10:04.595820 I | op-mon: start running mons
2021-04-01 11:10:04.598623 I | op-mon: parsing mon endpoints: a=10.96.23.125:6789
2021-04-01 11:10:04.607378 I | cephclient: writing config file /var/lib/rook/rook-ceph/rook-ceph.config
2021-04-01 11:10:04.607489 I | cephclient: generated admin config in /var/lib/rook/rook-ceph
2021-04-01 11:10:05.985547 I | op-mon: targeting the mon count 3
2021-04-01 11:10:51.227775 W | op-mon: failed to set Rook and/or user-defined Ceph config options before starting mons; will retry after starting mons. failed to apply default Ceph configurations: failed to set one or more Ceph configs: failed to set ceph config in the centralized mon configuration database; you may need to use the rook-config-override ConfigMap. output: timed out
. : timed out
. : failed to set ceph config in the centralized mon configuration database; you may need to use the rook-config-override ConfigMap. output: timed out
. : timed out
. : failed to set ceph config in the centralized mon configuration database; you may need to use the rook-config-override ConfigMap. output: timed out
. : timed out
.
2021-04-01 11:10:51.227795 I | op-mon: creating mon b
2021-04-01 11:10:51.249919 I | op-mon: mon "a" endpoint is [v2:10.96.23.125:3300,v1:10.96.23.125:6789]
2021-04-01 11:10:51.256386 I | op-mon: mon "b" endpoint is [v2:10.101.150.216:3300,v1:10.101.150.216:6789]
2021-04-01 11:10:51.429911 I | cephclient: writing config file /var/lib/rook/rook-ceph/rook-ceph.config
2021-04-01 11:10:51.430046 I | cephclient: generated admin config in /var/lib/rook/rook-ceph
2021-04-01 11:10:52.229852 I | cephclient: writing config file /var/lib/rook/rook-ceph/rook-ceph.config
2021-04-01 11:10:52.229981 I | cephclient: generated admin config in /var/lib/rook/rook-ceph
2021-04-01 11:10:52.233234 I | op-mon: 1 of 2 expected mon deployments exist. creating new deployment(s).
2021-04-01 11:10:52.237046 I | op-mon: deployment for mon rook-ceph-mon-a already exists. updating if needed
2021-04-01 11:10:52.244688 I | op-k8sutil: deployment "rook-ceph-mon-a" did not change, nothing to update
2021-04-01 11:10:52.633347 I | op-mon: updating maxMonID from 0 to 1 after committing mon "b"
2021-04-01 11:10:53.031041 I | op-mon: waiting for mon quorum with [a b]
2021-04-01 11:10:53.632406 I | op-mon: mon b is not yet running
2021-04-01 11:10:53.632428 I | op-mon: mons running: [a]
2021-04-01 11:11:13.719001 I | op-mon: mons running: [a b]
^[e2021-04-01 11:11:33.801858 I | op-mon: mons running: [a b]
OK, so the cluster is doing some self healing (since I did destroy it ). I figured I’d wait for all 3 mons to establish a quorum, but eventually nothing went right. I can’t make contact with Ceph from the agent:
$ k exec -it rook-ceph-agent-nf4cp -- /bin/bash
[root@all-in-one-01 /]# ceph s
$ k exec -it rook-ceph-operator-848d87c78d-fsd9z -- /bin/bash
[root@rook-ceph-operator-848d87c78d-fsd9z /]# ceph -s
Error initializing cluster client: ObjectNotFound('RADOS object not found (error calling conf_read_file)',)
Looks like the Ceph cluster just isn’t present (which would explain the dashbaord not coming back up), but it’s not clear exactly what the failure is the mons are running (all 3 are there), but I also see warnings like the following:
2021-04-02 01:32:45.256775 W | op-mon: failed to set Rook and/or user-defined Ceph config options before starting mons; will retry after starting mons. failed to apply default Ceph configurations: failed to set one or more Ceph configs: failed to set ceph config in the centralized mon configuration database; you may need to use the rook-config-override ConfigMap. output: timed out
. : timed out
. : failed to set ceph config in the centralized mon configuration database; you may need to use the rook-config-override ConfigMap. output: timed out
. : timed out
. : failed to set ceph config in the centralized mon configuration database; you may need to use the rook-config-override ConfigMap. output: timed out
. : timed out
After reading an issue related to the crash-collector keyring not found in the rook repo, I got the idea to check the output of the mon pods. I see a lot of errors that look like this:
debug 2021-04-02T01:41:00.617+0000 7f1c1d55b700 0 log_channel(audit) log [DBG] : from='admin socket' entity='admin socket' cmd=mon_status args=[]: finished
debug 2021-04-02T01:41:00.953+0000 7f1c19ce3700 1 mon.a@0(probing) e3 handle_auth_request failed to assign global_id
debug 2021-04-02T01:41:01.753+0000 7f1c19ce3700 1 mon.a@0(probing) e3 handle_auth_request failed to assign global_id
debug 2021-04-02T01:41:03.349+0000 7f1c19ce3700 1 mon.a@0(probing) e3 handle_auth_request failed to assign global_id
debug 2021-04-02T01:41:03.553+0000 7f1c19ce3700 1 mon.a@0(probing) e3 handle_auth_request failed to assign global_id
debug 2021-04-02T01:41:03.953+0000 7f1c19ce3700 1 mon.a@0(probing) e3 handle_auth_request failed to assign global_id
debug 2021-04-02T01:41:04.101+0000 7f1c184e0700 -1 mon.a@0(probing) e3 get_health_metrics reporting 10568 slow ops, oldest is log(1 entries from
So I think I may have another missing RBAC issue, centered around the mons, but when I check common.yaml again I don’t see anything missing. When I exec into the mon and try to run ceph -s I get the following:
$ k exec -it rook-ceph-mon-a-798b6d9d66-l6wh8 -- /bin/bash
[root@rook-ceph-mon-a-798b6d9d66-l6wh8 /]# ceph -s
unable to get monitor info from DNS SRV with service name: ceph-mon
[errno 2] RADOS object not found (error connecting to the cluster)
Hmn, the ceph-mon service isn’t present? Is the mon trying to retreive the other mon addresses by checking the Service DNS entries? It sure seems like it, and if I check the servicews the ceph-mon service is certainly not there:
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
csi-cephfsplugin-metrics ClusterIP 10.107.77.72 <none> 8080/TCP,8081/TCP 16h
csi-rbdplugin-metrics ClusterIP 10.98.145.46 <none> 8080/TCP,8081/TCP 16h
rook-ceph-mon-a ClusterIP 10.96.23.125 <none> 6789/TCP,3300/TCP 14h
rook-ceph-mon-b ClusterIP 10.101.150.216 <none> 6789/TCP,3300/TCP 14h
rook-ceph-mon-c ClusterIP 10.101.17.73 <none> 6789/TCP,3300/TCP 14h
For some reason it looks like the mon service (that I assume makes all 3 available) didn’t get restarted. There’s a “monitors are the only pods running” common issue which might have offered some answers, but unfortunately this case was not the same. I know my operator can connect to the mons and they have quorum due to the logs, but the mons themselves seem to have issues.
I’m just going to teardown this cluster completely and try again, trying to change the cluster has seemingly made crucial parts of infrastructure not self-heal. A bit disappointed wiht Rook/Ceph’s ease-of-install here. Turns out there are alot of other things that need to be done to properly reset the disks that are used by rook as well. If the cluster never even got started I guess I don’t have to do that?
In the end I needed to just tear down the cluster completely, and run the tear down instructions (including removing /var/lib/rook).
After a hard reset (taking the machine from blank slate to k8s installed again), let’s and install Ceph via Rook again, in the folder all I have to do is run make to try again, and watch everything get created again. This time the following things are different:
common.yaml file)ceph-mon Service will come up and not go down (it’s a bit of a red flag that this isn’t self-healing, what if it is deleted again for some reason?)This time I managed to get wind of very good log messages in the setup pod that comes and goes:
2021-04-02 02:23:16.904804 I | cephosd: skipping device "nvme0n1p1" because it contains a filesystem "swap"
2021-04-02 02:23:16.904808 I | cephosd: skipping device "nvme0n1p2" because it contains a filesystem "ext4"
2021-04-02 02:23:16.904812 I | cephosd: skipping device "nvme0n1p3" because it contains a filesystem "ext4"
2021-04-02 02:23:16.904817 D | exec: Running command: udevadm info --query=property /dev/nvme0n1p4
2021-04-02 02:23:16.908080 D | exec: Running command: lsblk /dev/nvme0n1p4 --bytes --nodeps --pairs --paths --output SIZE,ROTA,RO,TYPE,PKNAME,NAME,KNAME
2021-04-02 02:23:16.909299 D | exec: Running command: ceph-volume inventory --format json /dev/nvme0n1p4
2021-04-02 02:23:17.331330 I | cephosd: skipping device "nvme0n1p4": ["Insufficient space (<5GB)"].
2021-04-02 02:23:17.331350 I | cephosd: skipping device "nvme0n1p5" because it contains a filesystem "ext4"
2021-04-02 02:23:17.331355 I | cephosd: skipping device "nvme1n1p1" because it contains a filesystem "linux_raid_member"
2021-04-02 02:23:17.331360 I | cephosd: skipping device "nvme1n1p2" because it contains a filesystem "linux_raid_member"
2021-04-02 02:23:17.331366 I | cephosd: skipping device "nvme1n1p3" because it contains a filesystem "linux_raid_member"
2021-04-02 02:23:17.331463 I | cephosd: configuring osd devices: {"Entries":{}}
2021-04-02 02:23:17.331469 I | cephosd: no new devices to configure. returning devices already configured with ceph-volume.
2021-04-02 02:23:17.331625 D | exec: Running command: stdbuf -oL ceph-volume --log-path /tmp/ceph-log lvm list --format json
2021-04-02 02:23:17.580235 D | cephosd: {}
2021-04-02 02:23:17.580269 I | cephosd: 0 ceph-volume lvm osd devices configured on this node
2021-04-02 02:23:17.580279 W | cephosd: skipping OSD configuration as no devices matched the storage settings for this node "all-in-one-01"
OK, so things have gone well in that I have at least a concrete place to start – the config and kubernetes configuration I’ve arrived at now is correct, but my set up of the machine is not, since containing a filesystem disqualifies a partition from being picked up, none of them are being picked up. The good news is it looks like I can leave the all-node/device scanning on, and just make sure to remove filesystems on nvme0n1p5 (the “leftover” bits of the primary OS-carrying disk) and nvme1n1.
It’s unclear to me how to make the Ceph cluster attempt to prepare the OSDs with Rook to check my settings again (and see the logs), but at the very least I can get the disk(s) in order and try again from the beginning. I’ll need to remove the offending the file systems. In the Ceph documentation there are docs on how to prepare a disk, and more specifically the zap command, so let’s try zapping that first partition (the “leftover” space on Disk 1):
root@all-in-one-01 ~ # ceph-volume lvm zap /dev/nvme0n1p5
--> Zapping: /dev/nvme0n1p5
--> Unmounting /dev/nvme0n1p5
Running command: /usr/bin/umount -v /dev/nvme0n1p5
stderr: umount: /root-disk-remaining (/dev/nvme0n1p5) unmounted
Running command: /usr/bin/dd if=/dev/zero of=/dev/nvme0n1p5 bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.00992182 s, 1.1 GB/s
--> Zapping successful for: <Partition: /dev/nvme0n1p5>
OK, so far so good, let’s try the entirety of disk 2:
root@all-in-one-01 ~ # ceph-volume lvm zap --destroy /dev/nvme1n1
--> Zapping: /dev/nvme1n1
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/nvme1n1p2: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
--> RuntimeError: could not complete wipefs on device: /dev/nvme1n1p2
Uh oh, it looks like at this opint in the process, something is already using the disk (which should be empty) might be easier to solve this earlier in the process (during the initial setup automation). I modified the ansible storage-plugin-setup.yml playbook with the following:
- name: Prepare leftover storage on disk 1 (NVMe)
tags: [ "drive-partition-prep" ]
when: storage_plugin in target_plugins
block:
# Ensure expected disk and partition exist
- name: Check that NVMe disk 0 exists
ansible.builtin.stat:
path: /dev/nvme0n1
register: nvme_disk_0
# Manage leftover partition on first disk
- name: Check that nvme0n1p5 (remaining space on disk 1) exists
ansible.builtin.stat:
path: /dev/nvme0n1p5
register: nvme_disk_0_partition_5
when: nvme_disk_0
- name: Zero the remaining space on the first disk (this takes a long time)
ansible.builtin.command: |
dd if=/dev/zero of=/dev/nvme0n1p5 bs=4096 status=progress
when: nvme_disk_0.stat.exists and nvme_disk_0_partition_5.stat.exists and disk_secure_wipe == "yes"
- name: Run zap on the leftover space in the first volume
ansible.builtin.command: |
ceph-volume lvm zap /dev/nvme0n1p5
when: nvme_disk_0_partition_5.stat.exists
vars:
target_plugins:
- rook-ceph-lvm
- name: Prepare entirety of disk 2 (NVMe)
tags: [ "drive-partition-prep" ]
when: storage_plugin in target_plugins
block:
# Ensure disk 2 exists
- name: Check that nvme1n1 (disk 2) exists
ansible.builtin.stat:
path: /dev/nvme1n1
register: nvme_disk_1
- name: Check that nvme1n1 has partitions
ansible.builtin.stat:
path: /dev/nvme1n1p1
register: nvme_disk_1_partition_1
- name: Zero the second disk with DD (this takes a long time)
ansible.builtin.command: |
dd if=/dev/zero of=/dev/nvme1n1 bs=4096 status=progress
when: nvme_disk_1.stat.exists and nvme_disk_1_partition_1.stat.exists and disk_secure_wipe == "yes"
- name: Clear the partition table of the second disk
ansible.builtin.command: |
sgdisk --zap-all -- /dev/nvme1n1
when: nvme_disk_1.stat.exists and nvme_disk_1_partition_1.stat.exists
vars:
target_plugins:
- rook-ceph-lvm
After getting the disks zapped properly the logs look a little bit better though there’s still an error:
2021-04-02 03:59:04.310696 D | exec: Running command: stdbuf -oL ceph-volume --log-path /tmp/ceph-log lvm batch --prepare --bluestore --yes --osds-per-device 1 /dev/nvme0n1p5 --report
2021-04-02 03:59:04.712163 D | exec: usage: ceph-volume lvm batch [-h] [--db-devices [DB_DEVICES [DB_DEVICES ...]]]
2021-04-02 03:59:04.712210 D | exec: [--wal-devices [WAL_DEVICES [WAL_DEVICES ...]]]
2021-04-02 03:59:04.712217 D | exec: [--journal-devices [JOURNAL_DEVICES [JOURNAL_DEVICES ...]]]
2021-04-02 03:59:04.712228 D | exec: [--auto] [--no-auto] [--bluestore] [--filestore]
2021-04-02 03:59:04.712235 D | exec: [--report] [--yes]
2021-04-02 03:59:04.712240 D | exec: [--format {json,json-pretty,pretty}] [--dmcrypt]
2021-04-02 03:59:04.712245 D | exec: [--crush-device-class CRUSH_DEVICE_CLASS]
2021-04-02 03:59:04.712250 D | exec: [--no-systemd]
2021-04-02 03:59:04.712256 D | exec: [--osds-per-device OSDS_PER_DEVICE]
2021-04-02 03:59:04.712261 D | exec: [--data-slots DATA_SLOTS]
2021-04-02 03:59:04.712266 D | exec: [--block-db-size BLOCK_DB_SIZE]
2021-04-02 03:59:04.712271 D | exec: [--block-db-slots BLOCK_DB_SLOTS]
2021-04-02 03:59:04.712276 D | exec: [--block-wal-size BLOCK_WAL_SIZE]
2021-04-02 03:59:04.712281 D | exec: [--block-wal-slots BLOCK_WAL_SLOTS]
2021-04-02 03:59:04.712286 D | exec: [--journal-size JOURNAL_SIZE]
2021-04-02 03:59:04.712291 D | exec: [--journal-slots JOURNAL_SLOTS] [--prepare]
2021-04-02 03:59:04.712296 D | exec: [--osd-ids [OSD_IDS [OSD_IDS ...]]]
2021-04-02 03:59:04.712300 D | exec: [DEVICES [DEVICES ...]]
2021-04-02 03:59:04.712307 D | exec: ceph-volume lvm batch: error: /dev/nvme0n1p5 is a partition, please pass LVs or raw block devices
failed to configure devices: failed to initialize devices: failed ceph-volume report: exit status 2
Looks like /dev/nvme0n1p5 is found now, but due to being a partition, ceph-volume lvm batch doesn’t work properly with it. According to the docs specific parittions can be used, so it’s weird that this would be a problem.
Maybe I could make the LVM module myself and give it to Rook?
I started looking into LVM stuff and found some resources to get me started quickly:
The creation directions looked something like this
$ pvcreate /dev/nvme0n1p5 # device (?)
$ vgcreate disk1_leftover_vg /dev/nvme0n1p5 # volume group
$ lvcreate -l 100%FREE -n disk1_leftover_lv disk1_leftover # (logical volume)
I tried to feed the logical volume name disk1_leftover_lv in the CephCluster in the nodes section but that didn’t work either. Turns out LVM support with the current Ceph version is iffy when used with Rook:
Since there’s some doubt, I figured I wouldn’t go with LVM at all (?) I removed the LV and ran lsblk -f:
root@all-in-one-01 ~ # pvremove --force --force /dev/nvme0n1p5
WARNING: PV /dev/nvme0n1p5 is used by VG disk1_leftover_vg.
Really WIPE LABELS from physical volume "/dev/nvme0n1p5" of volume group "disk1_leftover_vg" [y/n]? y
WARNING: Wiping physical volume label from /dev/nvme0n1p5 of volume group "disk1_leftover_vg".
Labels on physical volume "/dev/nvme0n1p5" successfully wiped.
root@all-in-one-01 ~ # lvremove disk1_leftover_vg
Do you really want to remove and DISCARD active logical volume disk1_leftover_vg/disk1_leftover_lv? [y/n]: y
Logical volume "disk1_leftover_lv" successfully removed
root@all-in-one-01 ~ # lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
nvme1n1
├─nvme1n1p1
├─nvme1n1p2
└─nvme1n1p3
nvme0n1
├─nvme0n1p1 swap fb9b8ba6-ef16-4575-a7b3-fd2ac4881eec [SWAP]
├─nvme0n1p2 ext4 5b09db7e-e1c0-4f07-a816-e4b113386265 754.1M 16% /boot
├─nvme0n1p3 ext4 5b9ff1c6-030d-457e-85b0-fb387e7cb81a 19.2G 30% /
├─nvme0n1p4
└─nvme0n1p5
Hmnnn did it always look this way? Theoretically now p4/p5 would be able to be used, because they don’t have FSTYPE set…?. I could have sworn this is how it was set up before, but re-saving the CephCluster with this disk layout actually worked. There’s now one OSD pod showing up:
$ k get pods
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-provisioner-5bcd6dc5bb-rdscw 6/6 Running 0 40m
csi-cephfsplugin-tnx9n 3/3 Running 0 40m
csi-rbdplugin-provisioner-64796f88cb-mgrhz 7/7 Running 0 40m
csi-rbdplugin-txvzn 3/3 Running 0 40m
rook-ceph-agent-qk5dd 1/1 Running 0 41m
rook-ceph-crashcollector-all-in-one-01-664845465d-n6jgb 1/1 Running 0 24s
rook-ceph-mgr-a-7f8d68c875-srlnr 1/1 Running 0 42s
rook-ceph-mon-a-6f7bc8d5f9-hgtn7 1/1 Running 0 62s
rook-ceph-mon-b-85b4c58bbf-cjx9g 1/1 Running 0 2m22s
rook-ceph-mon-c-6f7dd5654c-tvvcm 1/1 Running 0 72s
rook-ceph-operator-757bbbc4c6-9dlxp 1/1 Running 0 25m
rook-ceph-osd-0-96f658fbd-vcq4m 1/1 Running 0 24s <---- this one!
rook-ceph-osd-prepare-all-in-one-01-9tll2 0/1 Completed 0 33s <---- prepare suceeded this time!
“Task failed successfully” I guess. I looked at the logs to try and find out which drive got picked up out:
$ k logs rook-ceph-osd-0-96f658fbd-vcq4m
... happy logs ...
debug 2021-04-02T05:23:31.937+0000 7fbc39e04f40 1 bluefs add_block_device bdev 1 path /var/lib/ceph/osd/ceph-0/block size 414 GiB
Based on the size (414GB) it must be the leftover space on the OS disk… Which means that some combination of adding and removing the LVM LVs could have made the difference? I’m absolutely baffled. Unfortunately I actually changed 2 things at the same time – I also did the fallback to 15.2.6 on the CephCluster change.
Just to make sure, lsblk -f output confirms that ceph now has control of the partition:
root@all-in-one-01 ~ # lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
nvme1n1
├─nvme1n1p1
├─nvme1n1p2
└─nvme1n1p3
nvme0n1
├─nvme0n1p1 swap fb9b8ba6-ef16-4575-a7b3-fd2ac4881eec [SWAP]
├─nvme0n1p2 ext4 5b09db7e-e1c0-4f07-a816-e4b113386265 754.1M 16% /boot
├─nvme0n1p3 ext4 5b9ff1c6-030d-457e-85b0-fb387e7cb81a 18.2G 33% /
├─nvme0n1p4
└─nvme0n1p5 LVM2_member uV73WG-htxp-Udel-UJlH-25rL-pifF-0DxA35
└─ceph--a08ffc2d--f60e--4234--8af4--fb1a7b786cfe-osd--data--d5b583bc--fb84--4adf--aad5--df0e877d1b08
ceph_bluestore
This is great, but why in the world does the fully clear drive still get ignored? I have to tear everything down and figure out why this worked (and figure out why the whole drive that is specified is being ignored as well). Did messing with LVM (maybe adding and removing a logical volume left enough metadata for Ceph to pick up on?) or the version change fix it…
After a hard reset (easy as a single make command for me) here’s what lsblk -f looks like:
root@all-in-one-01 ~ # lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
nvme1n1
nvme0n1
├─nvme0n1p1 swap 3787acfd-0cf5-4b97-bc06-5d7c4e5c6954 [SWAP]
├─nvme0n1p2 ext4 4003c1ef-379b-48fb-99a0-54e4ce5aee95 825.4M 9% /boot
├─nvme0n1p3 ext4 2101a61f-33ca-48db-bdd3-b49254b2b9aa 24.3G 12% /
├─nvme0n1p4
└─nvme0n1p5
OK, so the drives are zapped/cleared appropriately – that looks much better than the mess I was making with LVM. To see if messing with LVM made the difference (changes that didn’t stay), I tried installing rook again, with automatic storage device pickup (useAllNodes: true and useAllDevices: true):
$ k logs rook-ceph-osd-prepare-all-in-one-01-4mpq4
2021-04-02 07:01:51.542166 D | exec: Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-1/keyring
2021-04-02 07:01:51.542168 D | exec: Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-1/
2021-04-02 07:01:51.542172 D | exec: Running command: /usr/bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 1 --monmap /var/lib/ceph/osd/ceph-1/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-1/ --osd-uuid b221a4c5-98d6-4029-93aa-fd71ca3b058b --setuser ceph --setgroup ceph
2021-04-02 07:01:51.542174 D | exec: --> ceph-volume lvm prepare successful for: ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43
2021-04-02 07:01:51.560994 D | exec: Running command: stdbuf -oL ceph-volume --log-path /tmp/ceph-log lvm list --format json
2021-04-02 07:01:51.994158 D | cephosd: {
"0": [
{
"devices": [
"/dev/nvme1n1"
],
"lv_name": "osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404",
"lv_path": "/dev/ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897/osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404",
"lv_size": "<476.94g",
"lv_tags": "ceph.block_device=/dev/ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897/osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404,ceph.block_uuid=dTJgw1-0ybj-dxox-PdWY-Jxor-nnYD-h2XiSN,ceph.cephx_lockbox_secret=,ceph.cluster_fsid=e56951de-f7cf-48fc-975a-6148a9ab7c57,ceph.cluster_name=ceph,ceph.crush_device_class=None,ceph.encrypted=0,ceph.osd_fsid=e6f53351-3168-4515-9a51-75dd0477274d,ceph.osd_id=0,ceph.osdspec_affinity=,ceph.type=block,ceph.vdo=0",
"lv_uuid": "dTJgw1-0ybj-dxox-PdWY-Jxor-nnYD-h2XiSN",
"name": "osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404",
"path": "/dev/ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897/osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404",
"tags": {
"ceph.block_device": "/dev/ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897/osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404",
"ceph.block_uuid": "dTJgw1-0ybj-dxox-PdWY-Jxor-nnYD-h2XiSN",
"ceph.cephx_lockbox_secret": "",
"ceph.cluster_fsid": "e56951de-f7cf-48fc-975a-6148a9ab7c57",
"ceph.cluster_name": "ceph",
"ceph.crush_device_class": "None",
"ceph.encrypted": "0",
"ceph.osd_fsid": "e6f53351-3168-4515-9a51-75dd0477274d",
"ceph.osd_id": "0",
"ceph.osdspec_affinity": "",
"ceph.type": "block",
"ceph.vdo": "0"
},
"type": "block",
"vg_name": "ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897"
}
],
"1": [
{
"devices": [
"/dev/nvme0n1p5"
],
"lv_name": "osd-data-11386012-bbec-436e-bda6-a861a0e32c43",
"lv_path": "/dev/ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43",
"lv_size": "413.93g",
"lv_tags": "ceph.block_device=/dev/ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43,ceph.block_uuid=fgnybC-D45W-S1eE-QrfK-pHwl-DRCO-jafPxM,ceph.cephx_lockbox_secret=,ceph.cluster_fsid=e56951de-f7cf-48fc-975a-6148a9ab7c57,ceph.cluster_name=ceph,ceph.crush_device_class=None,ceph.encrypted=0,ceph.osd_fsid=b221a4c5-98d6-4029-93aa-fd71ca3b058b,ceph.osd_id=1,ceph.osdspec_affinity=,ceph.type=block,ceph.vdo=0",
"lv_uuid": "fgnybC-D45W-S1eE-QrfK-pHwl-DRCO-jafPxM",
"name": "osd-data-11386012-bbec-436e-bda6-a861a0e32c43",
"path": "/dev/ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43",
"tags": {
"ceph.block_device": "/dev/ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43",
"ceph.block_uuid": "fgnybC-D45W-S1eE-QrfK-pHwl-DRCO-jafPxM",
"ceph.cephx_lockbox_secret": "",
"ceph.cluster_fsid": "e56951de-f7cf-48fc-975a-6148a9ab7c57",
"ceph.cluster_name": "ceph",
"ceph.crush_device_class": "None",
"ceph.encrypted": "0",
"ceph.osd_fsid": "b221a4c5-98d6-4029-93aa-fd71ca3b058b",
"ceph.osd_id": "1",
"ceph.osdspec_affinity": "",
"ceph.type": "block",
"ceph.vdo": "0"
},
"type": "block",
"vg_name": "ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211"
}
]
}
2021-04-02 07:01:51.994341 I | cephosd: osdInfo has 1 elements. [{Name:osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404 Path:/dev/ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897/osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404 Tags:{OSDFSID:e6f53351-3168-4515-9a51-75dd0477274d Encrypted:0 ClusterFSID:e56951de-f7cf-48fc-975a-6148a9ab7c57} Type:block}]
2021-04-02 07:01:51.994354 I | cephosd: osdInfo has 1 elements. [{Name:osd-data-11386012-bbec-436e-bda6-a861a0e32c43 Path:/dev/ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43 Tags:{OSDFSID:b221a4c5-98d6-4029-93aa-fd71ca3b058b Encrypted:0 ClusterFSID:e56951de-f7cf-48fc-975a-6148a9ab7c57} Type:block}]
2021-04-02 07:01:51.994361 I | cephosd: 2 ceph-volume lvm osd devices configured on this node
2021-04-02 07:01:51.994378 D | exec: Running command: stdbuf -oL ceph-volume --log-path /tmp/ceph-log raw list /mnt/all-in-one-01 --format json
2021-04-02 07:01:52.219325 D | cephosd: {}
2021-04-02 07:01:52.219354 I | cephosd: 0 ceph-volume raw osd devices configured on this node
2021-04-02 07:01:52.219395 I | cephosd: devices = [{ID:0 Cluster:ceph UUID:e6f53351-3168-4515-9a51-75dd0477274d DevicePartUUID: BlockPath:/dev/ceph-52ee3f53-4be2-44a8-82e2-a4d9c7482897/osd-data-079acaa7-02ae-4c9a-a6e7-a16680fde404 MetadataPath: WalPath: SkipLVRelease:false Location:root=default host=all-in-one-01 LVBackedPV:false CVMode:lvm Store:bluestore TopologyAffinity:} {ID:1 Cluster:ceph UUID:b221a4c5-98d6-4029-93aa-fd71ca3b058b DevicePartUUID: BlockPath:/dev/ceph-fb5c4837-8fe8-41db-9a1b-536823b6b211/osd-data-11386012-bbec-436e-bda6-a861a0e32c43 MetadataPath: WalPath: SkipLVRelease:false Location:root=default host=all-in-one-01 LVBackedPV:false CVMode:lvm Store:bluestore TopologyAffinity:}]
It’s working! Awesome, so the drive and the partitions were picked up automatically, successfully. The pod listing looks like the following:
$ k get pods
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-f7ngf 3/3 Running 0 7m16s
csi-cephfsplugin-provisioner-5bcd6dc5bb-w8thz 6/6 Running 0 7m15s
csi-rbdplugin-provisioner-64796f88cb-5pwj6 7/7 Running 0 7m16s
csi-rbdplugin-z6lbh 3/3 Running 0 7m16s
rook-ceph-agent-bk66n 1/1 Running 0 7m58s
rook-ceph-crashcollector-all-in-one-01-664845465d-k5h8w 1/1 Running 0 6m44s
rook-ceph-mgr-a-5ddf8b5867-nz9q4 1/1 Running 0 6m58s
rook-ceph-mon-a-5696c776d5-zcs25 1/1 Running 0 7m31s
rook-ceph-mon-b-b785486c7-x8z26 1/1 Running 0 7m23s
rook-ceph-mon-c-9d777db45-l7z9j 1/1 Running 0 7m9s
rook-ceph-operator-757bbbc4c6-9fntb 1/1 Running 0 8m16s
rook-ceph-osd-0-568cf65dcc-26gzl 1/1 Running 0 6m44s
rook-ceph-osd-1-5d65b45c9f-6v8dk 1/1 Running 0 6m44s
rook-ceph-osd-prepare-all-in-one-01-4mpq4 0/1 Completed 0 6m56s
Can I believe my eyes? Let’s look at the dashboard…
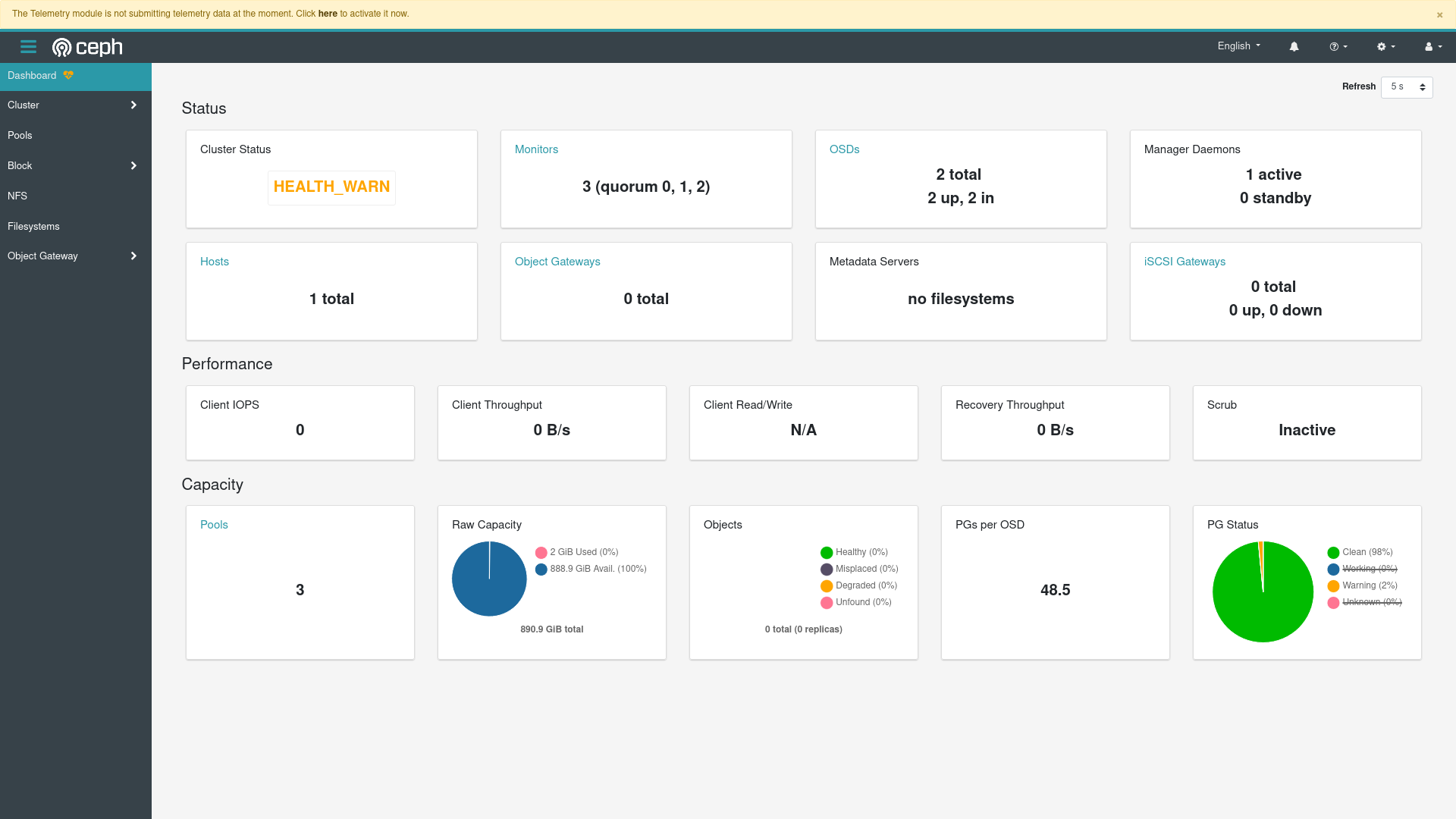
Looks like everything is indeed working great! The health warnings are actually all expected:
So at this point I’m pretty sure I can pin down what fixed it:
sgdisk and other tools (this is basically just user error)OK great, it looks like I’ve finally figured out the correct combination to get Ceph working, let’s try making a PersistentVolumeClaim that will generate a PersistentVolume and a one-off Pod to explore that data with and ensure it’s writeable, etc. I did this for both the single (non-HA) pool and the 2 replica (somewhat HA but not only at the OSD/drive level):
test-single.pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-single
namespace: default
spec:
storageClassName: rook-ceph-block-single-osd
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
test-single.pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: test-single
namespace: default
spec:
containers:
- name: alpine
image: alpine
command: ["ash", "-c", "while true; do sleep infinity; done"]
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 0.5
memory: "512Mi"
requests:
cpu: 0.5
memory: "512Mi"
volumeMounts:
- mountPath: /var/data
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: test-single
And it looks like everything is good PVCs is bound and the PV is created…
$ k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-single Bound pvc-9a0adccf-2cc1-4e4e-950e-fb3528399437 1Gi RWO rook-ceph-block-single-osd 24s
$ k get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-9a0adccf-2cc1-4e4e-950e-fb3528399437 1Gi RWO Delete Bound default/test-single rook-ceph-block-single-osd 112s
But of course it can’t be that simple!
ContainerCreating due to Rook CSI driver not being foundNOTE This section contains another example of me solving this problem (the rook CSI driver not being found due to /var/lib/kubelet not existing) the wrong way. Do not use a symlink to make /var/lib/kubelet point to /var/lib/k0s/kubelet – it will only partially work, the better way is to just change Rook’s configuration to point to the the k0s directory
The pod that uses the PV created by the PVC is of course stuck in ContainerCreating:
$ k describe pod test-single
... logs ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m34s (x19 over 14m) default-scheduler 0/1 nodes are available: 1 pod has unbound immediate PersistentVolumeClaims.
Warning FailedScheduling 2m40s default-scheduler 0/1 nodes are available: 1 persistentvolumeclaim "test-single" is being deleted.
Normal Scheduled 2m30s default-scheduler Successfully assigned default/test-single to all-in-one-01
Normal SuccessfulAttachVolume 2m30s attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-9a0adccf-2cc1-4e4e-950e-fb3528399437"
Warning FailedMount 27s kubelet Unable to attach or mount volumes: unmounted volumes=[data], unattached volumes=[data default-token-bphj6]: timed out waiting for the condition
Warning FailedMount 6s (x9 over 2m14s) kubelet MountVolume.MountDevice failed for volume "pvc-9a0adccf-2cc1-4e4e-950e-fb3528399437" : kubernetes.io/csi: attacher.MountDevice failed to create newCsiDriverClient: driver name rook-ceph.rbd.csi.ceph.com not found in the list of registered CSI drivers
Some sort of CSI failure – rook-ceph.rbd.csi.ceph.com wasn’t in the list of registered CSI drivers? Did the CSI plugin not register properly? I do remember those csi-rbdplugin and csi-cephfsplugin pods, maybe this is where I get to go in and debug those. Before I jump in, let me check the common issues page and see if theere’s anything… Oh, there’s also a CSI troubleshooting guide, awesome. It has a section on drive registration but basically that just tells me which precise containers to look at, guess I better take a look at the driver-registrar containers’ logs:
$ k logs csi-rbdplugin-6r58v -c driver-registrar
I0402 09:46:59.452770 16056 main.go:112] Version: v2.0.1
I0402 09:46:59.452807 16056 connection.go:151] Connecting to unix:///csi/csi.sock
I0402 09:47:00.456946 16056 node_register.go:55] Starting Registration Server at: /registration/rook-ceph.rbd.csi.ceph.com-reg.sock
I0402 09:47:00.457063 16056 node_register.go:64] Registration Server started at: /registration/rook-ceph.rbd.csi.ceph.com-reg.sock
I0402 09:47:00.457108 16056 node_register.go:86] Skipping healthz server because port set to: 0
Well doesn’t look like anything is wrong there… Maybe k0s has some issue with CSI setup..?
Yup, looks like it’s an issue with k0s, at least in my opinion (someone’s actually had a problem with the Hetzner CSI driver) – Rook is happily installing it’s stuff to /var/lib/kubelet (used by just about everything else) but k0s uses /var/lib/k0s/kubelet (in a bid to keep all the config in the same place, which I do commend. I guess I should have seen this coming when I created the folders, but I didn’t know that k0s was set up to not use /var/lib/kubelet. I added a step to my automation to make a symlink:
- name: Symlink /var/lib/kubelet into /var/lib/k0s/kubelet
ansible.builtin.file:
src: /var/lib/k0s/kubelet
dest: /var/lib/kubelet
state: link
when: ansible_facts.services["k0scontroller.service"] is not defined
/var/lib/kubelet/plugins/kubernetes.io/csi/pv/*/globalmount) is missingNote from the future: the symlinking in the previous section caused this problem, and all this debug was useless/misguided.
OK, so now that I’ve got that pesky symlink problem fixed I start from the top again (hard reset), and the cluster comes up, Rook is installed, but does the pod work? No, of course not, that would be too easy:
$ k describe pod test-single
... logs ...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m11s default-scheduler Successfully assigned default/test-single to all-in-one-01
Normal SuccessfulAttachVolume 4m10s attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-a615cd31-3845-4d09-8fec-23057769c3e6"
Warning FailedMount 2m8s kubelet Unable to attach or mount volumes: unmounted volumes=[data], unattached volumes=[data default-token-drkbt]: timed out waiting for the condition
Warning FailedMount 119s (x9 over 4m7s) kubelet MountVolume.MountDevice failed for volume "pvc-a615cd31-3845-4d09-8fec-23057769c3e6" : rpc error: code = InvalidArgument desc = staging path /var/lib/k0s/kubelet/plugins/kubernetes.io/csi/pv/pvc-a615cd31-3845-4d09-8fec-23057769c3e6/globalmount does not exist on node
The PVC is bound, and the PV is bound of course:
$ k get pvc -n default
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-single Bound pvc-a615cd31-3845-4d09-8fec-23057769c3e6 1Gi RWO rook-ceph-block-single-osd 12m
$ k get pv -n default
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-a615cd31-3845-4d09-8fec-23057769c3e6 1Gi RWO Delete Bound default/test-single rook-ceph-block-single-osd 12m
But somehow the mounting of this created PVC failed in the Pod itself, and if we take a look at the csi-rbdplugin pod we can see the error:
$ k logs -f csi-rbdplugin-s75h2 -c csi-rbdplugin
W0402 11:49:42.154890 19941 driver.go:173] EnableGRPCMetrics is deprecated
E0402 11:51:56.704008 19941 utils.go:136] ID: 6 Req-ID: 0001-0009-rook-ceph-0000000000000002-cffb3bc2-93a9-11eb-a142-0ed45baf5e45 GRPC error: rpc error: code = InvalidArgument desc = staging path /var/lib/k0s/kubelet/plugins/kubernetes.io/csi/pv/pvc-a615cd31-3845-4d09-8fec-23057769c3e6/globalmount does not exist on node
.io/csi/pv/pvc-a615cd31-3845-4d09-8fec-23057769c3e6/globalmount does not exist on node
E0402 11:58:08.876763 19941 utils.go:136] ID: 32 Req-ID: 0001-0009-rook-ceph-0000000000000002-cffb3bc2-93a9-11eb-a142-0ed45baf5e45 GRPC error: rpc error: code = InvalidArgument desc = staging path /var/lib/k0s/kubelet/plugins/kubernetes.io/csi/pv/pvc-a615cd31-3845-4d09-8fec-23057769c3e6/globalmount does not exist on node
My first instinct is that maybe this is a permissions issue? The folder structure leading up to the pvc looks to be there:
# tree /var/lib/k0s/kubelet/plugins
/var/lib/k0s/kubelet/plugins
├── kubernetes.io
│ └── csi
│ └── pv
├── rook-ceph.cephfs.csi.ceph.com
│ └── csi.sock
└── rook-ceph.rbd.csi.ceph.com
└── csi.sock
5 directories, 2 files
So basically, everything with regards to the actual PVC – pvc-..../ doesn’t seem to have gotten made. Let’s check with Ceph to see if this drive at least exists. The good news is that I can see the block device I created on the Ceph level:
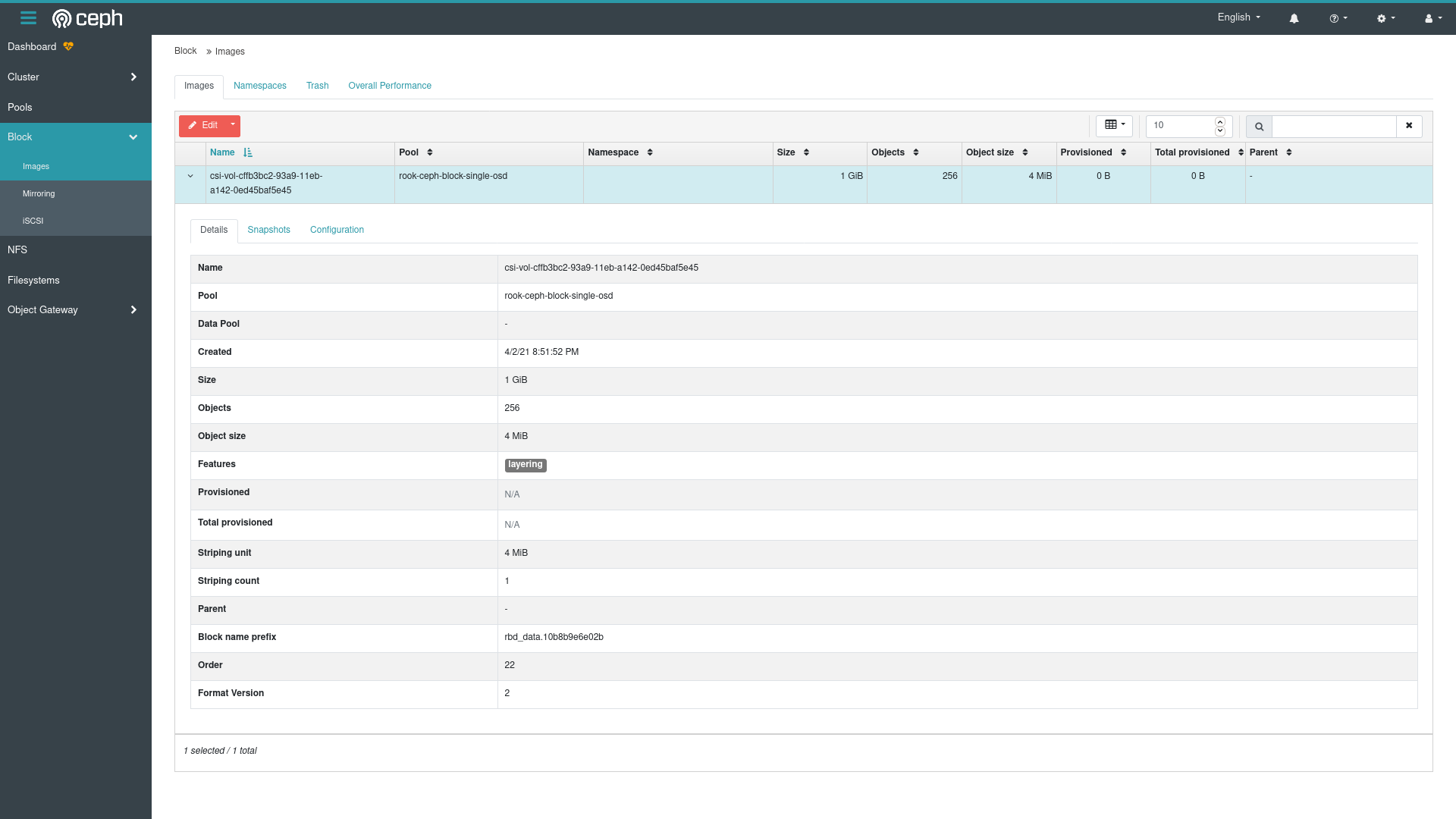
OK that’s good news, so the problem isn’t on the Ceph side, but must be somewhere on the Rook side – the Ceph block device got created, but it couldn’t be mounted onto the disk where Rook (and the rest of Kubernetes) expected it to be… Maybe some permissions issues, I wonder. The question is where to start looking for the rook side breakdown. We already know the csi-rbdplugin had an issue, but it’s trying to find something that isn’t there, the issue must have started somewhere else. Let’s check the rook agent:
$ k logs -f rook-ceph-agent-bf4mg
2021-04-02 11:48:59.111878 I | rookcmd: starting Rook v1.5.9 with arguments '/usr/local/bin/rook ceph agent'
2021-04-02 11:48:59.111916 I | rookcmd: flag values: --help=false, --log-flush-frequency=5s, --log-level=INFO, --operator-image=, --service-account=
2021-04-02 11:48:59.111919 I | cephcmd: starting rook ceph agent
2021-04-02 11:48:59.160808 I | flexvolume: listening on unix socket for Kubernetes volume attach commands "/flexmnt/ceph.rook.io~rook-ceph/.rook.sock"
2021-04-02 11:49:00.211342 I | flexvolume: listening on unix socket for Kubernetes volume attach commands "/flexmnt/ceph.rook.io~rook/.rook.sock"
2021-04-02 11:49:01.260174 I | flexvolume: listening on unix socket for Kubernetes volume attach commands "/flexmnt/rook.io~rook-ceph/.rook.sock"
2021-04-02 11:49:02.309211 I | flexvolume: listening on unix socket for Kubernetes volume attach commands "/flexmnt/rook.io~rook/.rook.sock"
2021-04-02 11:49:02.309226 I | agent-cluster: start watching cluster resources
Nope, nothing there, let’s try the provisioner?
$ k logs -f csi-rbdplugin-provisioner-64796f88cb-gw42g
error: a container name must be specified for pod csi-rbdplugin-provisioner-64796f88cb-gw42g, choose one of: [csi-provisioner csi-resizer csi-attacher csi-snapshotter csi-omap-generator csi-rbdplugin liveness-prometheus]
So that’s weird… There’s another csi-rbdplugin pod? Is that reasonable? Who knows. Anyway, let’s start there:
$ k logs -f csi-rbdplugin-provisioner-64796f88cb-gw42g -c csi-rbdplugin
W0402 11:49:48.370004 1 driver.go:173] EnableGRPCMetrics is deprecated
E0402 11:51:51.303554 1 omap.go:77] ID: 19 Req-ID: pvc-a615cd31-3845-4d09-8fec-23057769c3e6 omap not found (pool="rook-ceph-block-single-osd", namespace="", name="csi.volumes.default"): rados: ret=-2, No such file or directory
OK, there’s a nice hint – let’s check the omap-generator (globalmap??) if that’s where things are going wrong:
$ k logs -f csi-rbdplugin-provisioner-64796f88cb-gw42g -c csi-omap-generator
I0402 11:49:48.993282 1 leaderelection.go:242] attempting to acquire leader lease rook-ceph/rook-ceph.rbd.csi.ceph.com-rook-ceph...
I0402 11:49:48.999282 1 leaderelection.go:252] successfully acquired lease rook-ceph/rook-ceph.rbd.csi.ceph.com-rook-ceph
Nope, nothing there – The only other thing that seems like it could be related is the provisioner:
I0402 11:49:49.510779 1 controller.go:869] Started provisioner controller rook-ceph.rbd.csi.ceph.com_csi-rbdplugin-provisioner-64796f88cb-gw42g_3037aa66-26ba-4df8-8a06-a8e428ba79e4!
I0402 11:51:51.289530 1 controller.go:1317] provision "default/test-single" class "rook-ceph-block-single-osd": started
I0402 11:51:51.289664 1 event.go:282] Event(v1.ObjectReference{Kind:"PersistentVolumeClaim", Namespace:"default", Name:"test-single", UID:"a615cd31-3845-4d09-8fec-23057769c3e6", APIVersion:"v1", ResourceVersion:"2291", FieldPath:""}): type: 'Normal' reason: 'Provisioning' External provisioner is provisioning volume for claim "default/test-single"
I0402 11:51:52.756940 1 controller.go:1420] provision "default/test-single" class "rook-ceph-block-single-osd": volume "pvc-a615cd31-3845-4d09-8fec-23057769c3e6" provisioned
I0402 11:51:52.756979 1 controller.go:1437] provision "default/test-single" class "rook-ceph-block-single-osd": succeeded
E0402 11:51:52.767454 1 controller.go:1443] couldn't create key for object pvc-a615cd31-3845-4d09-8fec-23057769c3e6: object has no meta: object does not implement the Object interfaces
I0402 11:51:52.767529 1 controller.go:1317] provision "default/test-single" class "rook-ceph-block-single-osd": started
I0402 11:51:52.767555 1 controller.go:1326] provision "default/test-single" class "rook-ceph-block-single-osd": persistentvolume "pvc-a615cd31-3845-4d09-8fec-23057769c3e6" already exists, skipping
I0402 11:51:52.767566 1 event.go:282] Event(v1.ObjectReference{Kind:"PersistentVolumeClaim", Namespace:"default", Name:"test-single", UID:"a615cd31-3845-4d09-8fec-23057769c3e6", APIVersion:"v1", ResourceVersion:"2291", FieldPath:""}): type: 'Normal' reason: 'ProvisioningSucceeded' Successfully provisioned volume pvc-a615cd31-3845-4d09-8fec-23057769c3e6
OK, there’s some more useful information, with a tiny Error in between lots of successful-seeming informational log messages. couldn't create key for object pvc-...: object has no meta: object does not implement the Object interfaces is a weird error… Looks like there are some mentions of it in open tickets:
Using some of the advice from there (big thanks to @travisn), I took a look at the ceph cluster (k describe cephcluster), and outside of the cluster being in the HEALTH_WARN state (which is mentioned to be possibly benign from time to time), the cluster looks fine… After lots and ots of searching through logs I wasn’t able to find any more tidbits. It seems like the omap generator might be to blame:
# OMAP generator will generate the omap mapping between the PV name and the RBD image.
# CSI_ENABLE_OMAP_GENERATOR need to be enabled when we are using rbd mirroring feature.
# By default OMAP generator sidecar is deployed with CSI provisioner pod, to disable
# it set it to false.
CSI_ENABLE_OMAP_GENERATOR: "true"
RBD mirroring is generally a feature I don’t want to disable, but that might be a path forward. For now, I turned up the log level to "3" in the configmap and applyed that to the cluster to see if I can get some more information out of the csi-omap-generator on why it can’t create the map, and I got nothing from that either. I found something that seems to be similar, but unfortunately is related to CephFS.
What I did manage to find were some instructions for stale operations which were worth looking to. Since the attachment was actually working fine, and the mounts that are going badly, the issue may show up in the dmesg logs. Well while I was looking into this, I restarted the machine, which was a big no-no because now I’ve found another issue – restarting is causing the node breaks things.
While trying to debug the previous issues I ran into another very big problem – restarts don’t seem to be safe:
$ k logs rook-ceph-osd-1-59765fcfcd-p5mp5
debug 2021-04-02T13:59:19.854+0000 7f76bce47f40 0 set uid:gid to 167:167 (ceph:ceph)
debug 2021-04-02T13:59:19.854+0000 7f76bce47f40 0 ceph version 15.2.6 (cb8c61a60551b72614257d632a574d420064c17a) octopus (stable), process ceph-osd, pid 1
debug 2021-04-02T13:59:19.854+0000 7f76bce47f40 0 pidfile_write: ignore empty --pid-file
debug 2021-04-02T13:59:19.854+0000 7f76bce47f40 -1 bluestore(/var/lib/ceph/osd/ceph-1/block) _read_bdev_label failed to open /var/lib/ceph/osd/ceph-1/block: (13) Permission denied
debug 2021-04-02T13:59:19.854+0000 7f76bce47f40 -1 ** ERROR: unable to open OSD superblock on /var/lib/ceph/osd/ceph-1: (2) No such file or directory
The only issue that looks like this is one related to their CI environment which doesn’t inspire confidence. Following that issue leads to a Pull request with setup that fixes the issue with some UDEV rules… It looks like I’ll have to adopt these rules too?
With a little help from the PR, some examples of basic UDEV rules, and Stack Overflow, I figured out a decent rule to write to target only block devices that would be used by Ceph:
01-rook-udev.rules.j2:
KERNEL=="{{ kernel_name }}"
SUBSYSTEM=="block"
ACTION=="add"
RUN+="/bin/chown 167 /dev/{{ kernel_name }}"
With the following ansible:
- name: Add udev rules for rook (user 167)
tags: [ "drive-partition-prep", "udev" ]
when: storage_plugin in target_plugins and nvme_disk_0_partition_5.stat.exists
ansible.builtin.template:
src: 01-rook-udev.rules.j2
dest: /etc/udev/rules.d/01-rook.rules
owner: root
group: root
mode: 0644
vars:
target_plugins:
- rook-ceph-lvm
kernel_name: nvme0n1p5
aaaaand that didn’t work. The permissions changed, but it turns out that the folder is really empty:
$ sudo su -l ceph -s /bin/bash
ceph@all-in-one-01:~$ tree /var/lib/ceph/
/var/lib/ceph/
├── bootstrap-mds
├── bootstrap-mgr
├── bootstrap-osd
├── bootstrap-rbd
├── bootstrap-rbd-mirror
├── bootstrap-rgw
├── crash
│ └── posted
├── mds
├── mgr
├── mon
├── osd
└── tmp
13 directories, 0 files
Great. So not exactly sure what in the world is going on here, but I don’t even want to deal with this problem yet. I’ll deal with restarts once I can at least get the cluster working once (I only need it to work once to test it anyway). I filed an issue on the mount thing so hopefully someone has some ideas.
So to get back to a working state I’ve done another hard refresh (man I have done that a lot), and am going to go back to the idea of checking dmesg in the csi-rbdplugin pod for stale operations. Ceph is able to create the block devices, attaching them on the k8s side to the Pod is working, but the final mount operation is failing, so I’ve got some faith that this is hopefully a small last-mile permission problem. After a ton of looking around and trying to find more hints or ideas on places to look, I filed an issue.
At this point I’ve considered using FlexVolume instead (which is what I used when I used Rook like… 2 years ago now or something), even with the loss in functionality (seems silly to go into production without Snapshots when CSI is right there)… This is a crazy amount of work to do just to get a storage system going. Since I’ve already had some success with just rolling back Ceph, I figured I’d go back and give version 4.2.19 a try. At this point the build from fresh server to working k8s install + Rook is a single command, so it’s not hard to just change the cephVersion.image variable in the cluster and get off to the races. Of course, I can’t restart the cluster because then the permissions go haywire and all the OSDs break but I’m ignoring that issue for now.
Fascinating group of log messages:
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.464580 12314 reconciler.go:269] operationExecutor.MountVolume started for volume \"pvc-19e38923-5c71-4f2f-82d8-511863b193c7\" (UniqueName: \"kubernetes.io/csi/rook-ceph.rbd.csi.ceph.com^0001-0009-rook-ceph-0000000000000003-7ef70370-9422-11eb-8d73-92badb08eac8\") pod \"test-replicated\" (UID: \"d036a903-4c0c-403b-a4dc-aec3fd9bfddd\") " component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.464844 12314 operation_generator.go:556] MountVolume.WaitForAttach entering for volume \"pvc-19e38923-5c71-4f2f-82d8-511863b193c7\" (UniqueName: \"kubernetes.io/csi/rook-ceph.rbd.csi.ceph.com^0001-0009-rook-ceph-0000000000000003-7ef70370-9422-11eb-8d73-92badb08eac8\") pod \"test-replicated\" (UID: \"d036a903-4c0c-403b-a4dc-aec3fd9bfddd\") DevicePath \"\"" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.468230 12314 operation_generator.go:565] MountVolume.WaitForAttach succeeded for volume \"pvc-19e38923-5c71-4f2f-82d8-511863b193c7\" (UniqueName: \"kubernetes.io/csi/rook-ceph.rbd.csi.ceph.com^0001-0009-rook-ceph-0000000000000003-7ef70370-9422-11eb-8d73-92badb08eac8\") pod \"test-replicated\" (UID: \"d036a903-4c0c-403b-a4dc-aec3fd9bfddd\") DevicePath \"csi-14b95c316ca5e09921a9ac2da2316162f08de6eccc1ea1e3af7ab160e7f077ca\"" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.468405 12314 clientconn.go:106] parsed scheme: \"\"" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.468414 12314 clientconn.go:106] scheme \"\" not registered, fallback to default scheme" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.468429 12314 passthrough.go:48] ccResolverWrapper: sending update to cc: {[{/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock <nil> 0 <nil>}] <nil> <nil>}" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.468435 12314 clientconn.go:948] ClientConn switching balancer to \"pick_first\"" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.468468 12314 clientconn.go:897] blockingPicker: the picked transport is not ready, loop back to repick" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.471928 12314 clientconn.go:106] parsed scheme: \"\"" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.471942 12314 clientconn.go:106] scheme \"\" not registered, fallback to default scheme" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.471959 12314 passthrough.go:48] ccResolverWrapper: sending update to cc: {[{/var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock <nil> 0 <nil>}] <nil> <nil>}" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.471966 12314 clientconn.go:948] ClientConn switching balancer to \"pick_first\"" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="I0403 04:39:04.471995 12314 clientconn.go:897] blockingPicker: the picked transport is not ready, loop back to repick" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="E0403 04:39:04.472655 12314 csi_attacher.go:306] kubernetes.io/csi: attacher.MountDevice failed: rpc error: code = InvalidArgument desc = staging path /var/lib/k0s/kubelet/plugins/kubernetes.io/csi/pv/pvc-19e38923-5c71-4f2f-82d8-511863b193c7/globalmount does not exist on node" component=kubelet
Apr 03 04:39:04 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:04" level=info msg="E0403 04:39:04.472854 12314 nestedpendingoperations.go:301] Operation for \"{volumeName:kubernetes.io/csi/rook-ceph.rbd.csi.ceph.com^0001-0009-rook-ceph-0000000000000003-7ef70370-9422-11eb-8d73-92badb08eac8 podName: nodeName:}\" failed. No retries permitted until 2021-04-03 04:41:06.472820033 +0200 CEST m=+1797.712202585 (durationBeforeRetry 2m2s). Error: \"MountVolume.MountDevice failed for volume \\\"pvc-19e38923-5c71-4f2f-82d8-511863b193c7\\\" (UniqueName: \\\"kubernetes.io/csi/rook-ceph.rbd.csi.ceph.com^0001-0009-rook-ceph-0000000000000003-7ef70370-9422-11eb-8d73-92badb08eac8\\\") pod \\\"test-replicated\\\" (UID: \\\"d036a903-4c0c-403b-a4dc-aec3fd9bfddd\\\") : rpc error: code = InvalidArgument desc = staging path /var/lib/k0s/kubelet/plugins/kubernetes.io/csi/pv/pvc-19e38923-5c71-4f2f-82d8-511863b193c7/globalmount does not exist on node\"" component=kubelet
Apr 03 04:39:05 all-in-one-01 k0s[11853]: time="2021-04-03 04:39:05" level=info msg="time=\"2021-04-03T04:39:05.514389324+02:00\" level=info msg=\"ExecSync for \\\"38b89cdb77d23f3904ddf2f6e1076174d38d198a0f64e957fe2a537608816d0e\\\" with command [/bin/calico-node -felix-live] and timeout 1 (s)\"" component=containerd
I think I might have found the smoking gun! The kubelet is trying to communicate with the CSI plugin and it’s picking the wrong scheme to do it with? What schemes are there even? Is /var/lib/kubelet/plugins/rook-ceph.rbd.csi.ceph.com/csi.sock the right path? Looking around the internet I found a very helpful issue from the cloud-provider-openstack project (which has this PR linked). OpenEBS also has an issue filed on this but what’s weird is it’s closed, I’m not sure if this person’s set up was not working at all because of this or if it was a minor ignorable error. considering that the MountDevice failed call is right there, and the blockingPicker seems to have tried more than once, I think the communication between is what’s failing…
Looking into that took me through a few more rabbit holes:
None of these really quite fixed it, I tried the new canary releases for ceph-csi but they didn’t work either. Feels like I’m getting closer though. Checking dmesg I think I might have found the issue:
[79145.716611] [UFW BLOCK] IN=cali469bf91c522 OUT=calie153dd7e537 MAC=ee:ee:ee:ee:ee:ee:be:31:e4:9e:6b:e2:08:00 SRC=10.244.22.170 DST=10.244.22.147 LEN=60 TOS=0x00 PREC=0x00 TTL=63 ID=40793 DF PROTO=TCP SPT=46106 DPT=6800 WINDOW=64860 RES=0x00 SYN URGP=0 MARK=0x10000
That looks like UFW is blocking a pod! Which pods are 10.244.22.170 and 10.244.22.147?
$ k get pods -n rook-ceph -o=wide
csi-rbdplugin-provisioner-86687f9df-ktztr 7/7 Running 0 56m 10.244.22.170 all-in-one-01 <none> <none>
rook-ceph-osd-6-7c8869b5c4-wh2qr 1/1 Running 0 21h 10.244.22.147 all-in-one-01 <none> <none>
In the end this didn’t fix it either though I did happen upon some ufw rules that should be helpful for Calico. After a bit of more checking around and digging, I tried the bit at the bottom of the CSI common issues file:
/var/lib/rook/rook-ceph/client.admin.keyringrbd ls resulted in this:[root@all-in-one-01 /]# rbd ls --id=rook-ceph -m=10.102.8.74 --key=AQCeD2lg2h1xHxAAeViJzY4RKeH+x2pLFWGg3Q==
2021-04-04T01:12:24.295+0000 7f95a0265700 -1 monclient(hunting): handle_auth_bad_method server allowed_methods [2] but i only support [2]
rbd: couldn't connect to the cluster!
rbd: listing images failed: (13) Permission denied
Permission denied and couldn’t connect, is it a network issue? Turns out there’s also a ROOK_HOSTPATH_REQUIRES_PRIVILEGED option that I didn’t set – I wonder if that’s causing the permissions issue instead? The comments around it look like this:
# Whether to start pods as privileged that mount a host path, which includes the Ceph mon and osd pods.
# Set this to true if SELinux is enabled (e.g. OpenShift) to workaround the anyuid issues.
# For more details see https://github.com/rook/rook/issues/1314#issuecomment-355799641
- name: ROOK_HOSTPATH_REQUIRES_PRIVILEGED
value: "false"
Pretty sure I dont’ have SELinux turned on but I guess I’ll set that to true just in case… One more problem was the mgr pods seemed to never be able to get the metadata from the OSD:
debug 2021-04-04T03:14:47.312+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.0: (2) No such file or directory
debug 2021-04-04T03:14:47.312+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.1: (2) No such file or directory
debug 2021-04-04T03:14:48.296+0000 7fa991670700 1 mgr.server send_report Not sending PG status to monitor yet, waiting for OSDs
debug 2021-04-04T03:14:48.312+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.0: (2) No such file or directory
debug 2021-04-04T03:14:48.312+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.1: (2) No such file or directory
debug 2021-04-04T03:14:48.312+0000 7fa9981ca700 0 [devicehealth ERROR root] Fail to parse JSON result from daemon osd.0 ()
debug 2021-04-04T03:14:48.312+0000 7fa9981ca700 0 [devicehealth ERROR root] Fail to parse JSON result from daemon osd.1 ()
debug 2021-04-04T03:14:49.016+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.0: (2) No such file or directory
debug 2021-04-04T03:14:49.016+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.1: (2) No such file or directory
debug 2021-04-04T03:14:49.016+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.2: (2) No such file or directory
debug 2021-04-04T03:14:50.296+0000 7fa991670700 1 mgr.server send_report Not sending PG status to monitor yet, waiting for OSDs
debug 2021-04-04T03:14:50.616+0000 7fa99066e700 0 log_channel(audit) log [DBG] : from='client.4198 -' entity='client.admin' cmd=[{"prefix": "balancer mode", "mode": "upmap", "target": ["mon-mgr", ""], "format": "json"}]: dispatch
debug 2021-04-04T03:14:50.616+0000 7fa98de6c700 0 [balancer WARNING root] Handling command: '{'format': 'json', 'mode': 'upmap', 'prefix': 'balancer mode', 'target': ['mon-mgr', '']}'
debug 2021-04-04T03:14:50.868+0000 7fa99066e700 0 log_channel(audit) log [DBG] : from='client.4200 -' entity='client.admin' cmd=[{"prefix": "balancer on", "target": ["mon-mgr", ""], "format": "json"}]: dispatch
debug 2021-04-04T03:14:50.868+0000 7fa98de6c700 0 [balancer WARNING root] Handling command: '{'format': 'json', 'prefix': 'balancer on', 'target': ['mon-mgr', '']}'
debug 2021-04-04T03:14:52.096+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.0: (2) No such file or directory
debug 2021-04-04T03:14:52.096+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.1: (2) No such file or directory
debug 2021-04-04T03:14:52.096+0000 7fa9b3b22700 1 mgr finish mon failed to return metadata for osd.2: (2) No such file or directory
This proved to be a pretty valuable hint, because it turns out the fix was directory based – using a symlink to /var/lib/kubelet was wrong – I should have changed the path to the kubelet the Rook configuration all along:
# kubelet directory path, if kubelet configured to use other than /var/lib/kubelet path.
# ROOK_CSI_KUBELET_DIR_PATH: "/var/lib/kubelet"
ROOK_CSI_KUBELET_DIR_PATH: "/var/lib/k0s/kubelet"
So at this point I’ve made these changes:
sgdisk and other tools (this is basically just user error), including making sure the disk is unmounted and removed from fstabROOK_CSI_KUBELET_DIR_PATH to /var/lib/k0s/kubeletNow that I can at least get it working once, let’s give that restart issue one more look-see, it sure would be nice if I could safely restart my machine!
SKIP THIS! The real tip is in the title of this section! The following information was a ton of debug only to find out that there was a ceph system user installed by apt and what I should have done was to not install ceph from apt, because rook depends on the ceph user having UID/GID 167.
Remembering what the error looks like:
$ k logs -f rook-ceph-osd-9-6d6586f555-sns8m
debug 2021-04-04T05:49:14.396+0000 7fa68847bf40 0 set uid:gid to 167:167 (ceph:ceph)
debug 2021-04-04T05:49:14.396+0000 7fa68847bf40 0 ceph version 15.2.6 (cb8c61a60551b72614257d632a574d420064c17a) octopus (stable), process ceph-osd, pid 1
debug 2021-04-04T05:49:14.396+0000 7fa68847bf40 0 pidfile_write: ignore empty --pid-file
debug 2021-04-04T05:49:14.396+0000 7fa68847bf40 -1 bluestore(/var/lib/ceph/osd/ceph-9/block) _read_bdev_label failed to open /var/lib/ceph/osd/ceph-9/block: (13) Permission denied
debug 2021-04-04T05:49:14.396+0000 7fa68847bf40 -1 ** ERROR: unable to open OSD superblock on /var/lib/ceph/osd/ceph-9: (2) No such file or directory
The OSD pod sure thinks that file exists… but on the node that folder is empty:
root@all-in-one-01 ~ # tree /var/lib/ceph/
/var/lib/ceph/
├── bootstrap-mds
├── bootstrap-mgr
├── bootstrap-osd
├── bootstrap-rbd
├── bootstrap-rbd-mirror
├── bootstrap-rgw
├── crash
│ └── posted
├── mds
├── mgr
├── mon
├── osd
└── tmp
13 directories, 0 files
So what’s happening here? let’s take a look inside the running OSD pod?:
# ... lots of yaml ...
- mountPath: /var/lib/ceph/osd/ceph-9
name: activate-osd
name: activate-osd
# ... lots of yaml ...
- hostPath:
path: /var/lib/rook/rook-ceph/_dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a
type: DirectoryOrCreate
name: activate-osd
So very weirdly - the path that’s being bound to /var/lib/ceph/osd/ceph-9 inside the container is that monstrosity oustide the container. Looking at the disk I do see the folder:
root@all-in-one-01 ~ # tree -L 1 /var/lib/rook/rook-ceph/
/var/lib/rook/rook-ceph/
├── client.admin.keyring
├── crash
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-3efe9dd7-94cf-4c60-bbd8-fb76f88e077c
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-68d0783e-ad99-4812-a454-6457d9db5d12
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-a7f00e62-14de-4c40-9fbd-db614ee2f891
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-b27c7a1d-bce2-4cb4-bdba-0b46a0a27898
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-1ba471eb-e1d9-42ca-aeef-e3cd4835162d
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-2c083cba-1b76-445b-90d0-86dfb2b3c2ee
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-391a73fe-a6cf-42f0-a71b-7f3abf5d265e
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-636257eb-b6cb-4a12-94e3-d29a121c4cc7
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-ea4c3894-3eaa-4194-b858-07e487aee767
├── log
└── rook-ceph.config
12 directories, 2 files
And in the actual folder we’re look for:
root@all-in-one-01 /var/lib/rook/rook-ceph # tree /var/lib/rook/rook-ceph/_dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a
/var/lib/rook/rook-ceph/_dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a
├── block -> /dev/ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed/osd-data-8543592e-af5c-429a-be88-22dad3d3715a
├── ceph_fsid
├── fsid
├── keyring
├── ready
├── require_osd_release
├── type
└── whoami
0 directories, 8 files
And here’s the output of lsblk:
root@all-in-one-01 /var/lib/rook/rook-ceph # lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
nvme0n1
├─nvme0n1p1 swap 339ee4dd-d64e-4023-b450-e07f5e97cd70 [SWAP]
├─nvme0n1p2 ext4 367f6cae-729f-4fc7-82e2-38e59ff4d156 825.4M 9% /boot
├─nvme0n1p3 ext4 38dc66c5-3da8-40f0-85c0-45d85f300e2a 51.4G 13% /
├─nvme0n1p4
└─nvme0n1p5 LVM2_member Ye4exL-SbqS-d1So-sNlI-HlC1-uxqK-QQMrNw
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--b27c7a1d--bce2--4cb4--bdba--0b46a0a27898
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--a7f00e62--14de--4c40--9fbd--db614ee2f891
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--3efe9dd7--94cf--4c60--bbd8--fb76f88e077c
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--68d0783e--ad99--4812--a454--6457d9db5d12
└─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--8543592e--af5c--429a--be88--22dad3d3715a
nvme1n1 LVM2_member cxHkr0-G12z-jkNT-29qo-d63V-MPxW-8dr9nR
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--391a73fe--a6cf--42f0--a71b--7f3abf5d265e
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--2c083cba--1b76--445b--90d0--86dfb2b3c2ee
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--1ba471eb--e1d9--42ca--aeef--e3cd4835162d
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--ea4c3894--3eaa--4194--b858--07e487aee767
└─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--636257eb--b6cb--4a12--94e3--d29a121c4cc7
OK, so it looks like Rook has done the hard lifting of splitting up the drives into LVM logical volumes, one for every OSD (I still have 5 OSDs per piece of space, since it’s NVMe). As you might have noticed I’ve restarted the server to get things into a working state again… Now we know where everything points to when it works, let’s reboot and break everything one more time.
When the machine comes back up the pods are still broken, the lsblk output does look a little different, as the FSTYPE has been filled in for the ceph volumes:
root@all-in-one-01 ~ # lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
nvme1n1 LVM2_member cxHkr0-G12z-jkNT-29qo-d63V-MPxW-8dr9nR
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--391a73fe--a6cf--42f0--a71b--7f3abf5d265e ceph_bluestore
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--2c083cba--1b76--445b--90d0--86dfb2b3c2ee ceph_bluestore
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--1ba471eb--e1d9--42ca--aeef--e3cd4835162d ceph_bluestore
├─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--ea4c3894--3eaa--4194--b858--07e487aee767 ceph_bluestore
└─ceph--d8305429--ceab--4315--880c--629eba674800-osd--data--636257eb--b6cb--4a12--94e3--d29a121c4cc7 ceph_bluestore
nvme0n1
├─nvme0n1p1 swap 339ee4dd-d64e-4023-b450-e07f5e97cd70 [SWAP]
├─nvme0n1p2 ext4 367f6cae-729f-4fc7-82e2-38e59ff4d156 825.4M 9% /boot
├─nvme0n1p3 ext4 38dc66c5-3da8-40f0-85c0-45d85f300e2a 51.3G 13% /
├─nvme0n1p4
└─nvme0n1p5 LVM2_member Ye4exL-SbqS-d1So-sNlI-HlC1-uxqK-QQMrNw
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--b27c7a1d--bce2--4cb4--bdba--0b46a0a27898 ceph_bluestore
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--a7f00e62--14de--4c40--9fbd--db614ee2f891 ceph_bluestore
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--3efe9dd7--94cf--4c60--bbd8--fb76f88e077c ceph_bluestore
├─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--68d0783e--ad99--4812--a454--6457d9db5d12 ceph_bluestore
└─ceph--5ba64dde--cdb3--49e1--871f--3043ced761ed-osd--data--8543592e--af5c--429a--be88--22dad3d3715a ceph_bluestore
The folder is also still there, all the files are still in the same place:
root@all-in-one-01 ~ # tree -L 1 /var/lib/rook/rook-ceph/
/var/lib/rook/rook-ceph/
├── client.admin.keyring
├── crash
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-3efe9dd7-94cf-4c60-bbd8-fb76f88e077c
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-68d0783e-ad99-4812-a454-6457d9db5d12
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-a7f00e62-14de-4c40-9fbd-db614ee2f891
├── _dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-b27c7a1d-bce2-4cb4-bdba-0b46a0a27898
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-1ba471eb-e1d9-42ca-aeef-e3cd4835162d
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-2c083cba-1b76-445b-90d0-86dfb2b3c2ee
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-391a73fe-a6cf-42f0-a71b-7f3abf5d265e
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-636257eb-b6cb-4a12-94e3-d29a121c4cc7
├── _dev_ceph-d8305429-ceab-4315-880c-629eba674800_osd-data-ea4c3894-3eaa-4194-b858-07e487aee767
├── log
└── rook-ceph.config
12 directories, 2 files
All the devices look the same, and if we take a look inside the old device folder:
root@all-in-one-01 ~ # ls -l /var/lib/rook/rook-ceph/_dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a
total 32
lrwxrwxrwx 1 167 167 92 Apr 4 09:00 block -> /dev/ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed/osd-data-8543592e-af5c-429a-be88-22dad3d3715a
-rw------- 1 167 167 37 Apr 4 09:00 ceph_fsid
-rw------- 1 167 167 37 Apr 4 09:00 fsid
-rw------- 1 167 167 55 Apr 4 09:00 keyring
-rw------- 1 167 167 6 Apr 4 09:00 ready
-rw------- 1 167 167 3 Apr 4 08:20 require_osd_release
-rw------- 1 167 167 10 Apr 4 09:00 type
-rw------- 1 167 167 2 Apr 4 09:00 whoami
So the user and group are ceph:ceph (uid/gid 167), which is good, but for some reason maybe the OSDs aren’t running as that user? If they were running as root then they’d definitely be able to see the folder as well.. I’m sensing some issues possibly with the PodSecurityPolicy or something. One interesting thing is that the OSD pod actually seems to run as the root user (uid 0):
containers:
- args:
- --foreground
- --id
- "9"
- --fsid
- 6d0f3f65-0bd5-4e17-bee7-91c3cc494c5b
- --setuser
- ceph
- --setgroup
- ceph
- --crush-location=root=default host=all-in-one-01
- --log-to-stderr=true
- --err-to-stderr=true
- --mon-cluster-log-to-stderr=true
- '--log-stderr-prefix=debug '
- --default-log-to-file=false
- --default-mon-cluster-log-to-file=false
- --ms-learn-addr-from-peer=false
command:
- ceph-osd
# ... more stuff ...#
image: ceph/ceph:v15.2.6
imagePullPolicy: IfNotPresent
name: osd
resources: {}
securityContext:
privileged: true
readOnlyRootFilesystem: false
runAsUser: 0
So that’s fascinating – why is this pod running as root when the folder on disk is owned by ceph? Also, is the --setuser and --setgroup not working? The easiest way to debug this would be to get inside that container, so what I did was kubectl edit the deployment and change the command in there to ["/bin/bash", "-c", "while true; do sleep infinity; done"]:
Once we have a console, the command we want to run (listed above) looks like this:
ceph-osd --foreground --id "9" --fsid 6d0f3f65-0bd5-4e17-bee7-91c3cc494c5b --setuser ceph --setgroup ceph --crush-location="root=default host=all-in-one-01" --log-to-stderr=true --err-to-stderr=true --mon-cluster-log-to-stderr=true '--log-stderr-prefix=debug ' --default-log-to-file=false --default-mon-cluster-log-to-file=false --ms-learn-addr-from-peer=false
When you run that from inside your new happily-running OSD pod, you get:
[root@rook-ceph-osd-9-78494cff76-xs5h5 /]# # ceph-osd --foreground --id "9" --fsid 6d0f3f65-0bd5-4e17-bee7-91c3cc494c5b --setuser ceph --setgroup ceph --crush-location="root=default host=all-in-one-01" --log-to-stderr=true --err-to-stderr=true --mon-cluster-log-to-stderr=true '--log-stderr-prefix=debug ' --default-log-to-file=false --default-mon-cluster-log-to-file=false --ms-learn-addr-from-peer=false
[root@rook-ceph-osd-9-78494cff76-xs5h5 /]# ceph-osd --foreground --id "9" --fsid 6d0f3f65-0bd5-4e17-bee7-91c3cc494c5b --setuser ceph --setgroup ceph --crush-location="root=default host=all-in-one-01" --log-to-stderr=true --err-to-stderr=tr
ue --mon-cluster-log-to-stderr=true '--log-stderr-prefix=debug ' --default-log-to-file=false --default-mon-cluster-log-to-file=false --ms-learn-addr-from-peer=false
debug 2021-04-04T08:20:25.425+0000 7fb55f4a6f40 0 set uid:gid to 167:167 (ceph:ceph)
debug 2021-04-04T08:20:25.425+0000 7fb55f4a6f40 0 ceph version 15.2.6 (cb8c61a60551b72614257d632a574d420064c17a) octopus (stable), process ceph-osd, pid 22
debug 2021-04-04T08:20:25.425+0000 7fb55f4a6f40 0 pidfile_write: ignore empty --pid-file
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev create path /var/lib/ceph/osd/ceph-9/block type kernel
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev(0x55bafd244380 /var/lib/ceph/osd/ceph-9/block) open path /var/lib/ceph/osd/ceph-9/block
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev(0x55bafd244380 /var/lib/ceph/osd/ceph-9/block) open size 85022736384 (0x13cbc00000, 79 GiB) block_size 4096 (4 KiB) non-rotational discard supported
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bluestore(/var/lib/ceph/osd/ceph-9) _set_cache_sizes cache_size 3221225472 meta 0.4 kv 0.4 data 0.2
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev create path /var/lib/ceph/osd/ceph-9/block type kernel
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev(0x55bafd244a80 /var/lib/ceph/osd/ceph-9/block) open path /var/lib/ceph/osd/ceph-9/block
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev(0x55bafd244a80 /var/lib/ceph/osd/ceph-9/block) open size 85022736384 (0x13cbc00000, 79 GiB) block_size 4096 (4 KiB) non-rotational discard supported
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bluefs add_block_device bdev 1 path /var/lib/ceph/osd/ceph-9/block size 79 GiB
debug 2021-04-04T08:20:25.429+0000 7fb55f4a6f40 1 bdev(0x55bafd244a80 /var/lib/ceph/osd/ceph-9/block) close
debug 2021-04-04T08:20:25.717+0000 7fb55f4a6f40 1 bdev(0x55bafd244380 /var/lib/ceph/osd/ceph-9/block) close
debug 2021-04-04T08:20:25.989+0000 7fb55f4a6f40 1 objectstore numa_node 0
debug 2021-04-04T08:20:25.989+0000 7fb55f4a6f40 0 starting osd.9 osd_data /var/lib/ceph/osd/ceph-9 /var/lib/ceph/osd/ceph-9/journal
debug 2021-04-04T08:20:25.989+0000 7fb55f4a6f40 -1 Falling back to public interface
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 0 load: jerasure load: lrc load: isa
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 1 bdev create path /var/lib/ceph/osd/ceph-9/block type kernel
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 1 bdev(0x55bafd245180 /var/lib/ceph/osd/ceph-9/block) open path /var/lib/ceph/osd/ceph-9/block
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 -1 bdev(0x55bafd245180 /var/lib/ceph/osd/ceph-9/block) open open got: (13) Permission denied
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 0 osd.9:0.OSDShard using op scheduler ClassedOpQueueScheduler(queue=WeightedPriorityQueue, cutoff=196)
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 0 osd.9:1.OSDShard using op scheduler ClassedOpQueueScheduler(queue=WeightedPriorityQueue, cutoff=196)
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 0 osd.9:2.OSDShard using op scheduler ClassedOpQueueScheduler(queue=WeightedPriorityQueue, cutoff=196)
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 0 osd.9:3.OSDShard using op scheduler ClassedOpQueueScheduler(queue=WeightedPriorityQueue, cutoff=196)
debug 2021-04-04T08:20:25.993+0000 7fb55f4a6f40 0 osd.9:4.OSDShard using op scheduler ClassedOpQueueScheduler(queue=WeightedPriorityQueue, cutoff=196)
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 -1 bluestore(/var/lib/ceph/osd/ceph-9/block) _read_bdev_label failed to open /var/lib/ceph/osd/ceph-9/block: (13) Permission denied
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 1 bluestore(/var/lib/ceph/osd/ceph-9) _mount path /var/lib/ceph/osd/ceph-9
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 -1 bluestore(/var/lib/ceph/osd/ceph-9/block) _read_bdev_label failed to open /var/lib/ceph/osd/ceph-9/block: (13) Permission denied
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 1 bdev create path /var/lib/ceph/osd/ceph-9/block type kernel
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 1 bdev(0x55bafd245180 /var/lib/ceph/osd/ceph-9/block) open path /var/lib/ceph/osd/ceph-9/block
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 -1 bdev(0x55bafd245180 /var/lib/ceph/osd/ceph-9/block) open open got: (13) Permission denied
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 -1 osd.9 0 OSD:init: unable to mount object store
debug 2021-04-04T08:20:25.997+0000 7fb55f4a6f40 -1 ** ERROR: osd init failed: (13) Permission denied
OK so a lot more information in here, but generally the same issue – permission denieds all over the place. There’s a similar issue related to OpenShift filed in the Rook repo, but it’s from 2018 and what they suggest (adding a PSP with runAsAny) is already done, I have the psp:rook PodSecurityPolicy installed, and it is very permissive, and it is bound to the rook-ceph-osd ServiceAccount via the rook-ceph-osd-psp RoleBinding (which is a bit peculiar because it’s a RoleBinding which uses a ClusterRole). I’m also not running SELinux as far as I know so it’s very weird that I’d need to make that kind of fix.
So back to twiddling, root can write to the folder:
[root@rook-ceph-osd-9-57c499585-7gvkf /]# ls /var/lib/ceph/osd/ceph-9
block ceph_fsid fsid keyring ready require_osd_release type whoami
[root@rook-ceph-osd-9-57c499585-7gvkf /]# echo "MAYBE?" > /var/lib/ceph/osd/ceph-9/try-write
# ... on the server ... #
root@all-in-one-01 ~ # cat /var/lib/rook/rook-ceph/_dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a/try-write
MAYBE?
OK, root in the container can write to the directory, which is owned by ceph (167), and the file is as you would expect owned by root. Even more bizarrely, ceph inside the container can write to the same folder, and the permissions come up as the right user (user 167):
[ceph@rook-ceph-osd-9-57c499585-7gvkf ~]$ echo "MAYBE?" > /var/lib/ceph/osd/ceph-9/try-write-ceph
[ceph@rook-ceph-osd-9-57c499585-7gvkf ~]$ command terminated with exit code 137
# ... on the server ... #
root@all-in-one-01 ~ # ls -l /var/lib/rook/rook-ceph/_dev_ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed_osd-data-8543592e-af5c-429a-be88-22dad3d3715a/
total 40
lrwxrwxrwx 1 167 167 92 Apr 4 10:41 block -> /dev/ceph-5ba64dde-cdb3-49e1-871f-3043ced761ed/osd-data-8543592e-af5c-429a-be88-22dad3d3715a
-rw------- 1 167 167 37 Apr 4 10:41 ceph_fsid
-rw------- 1 167 167 37 Apr 4 10:41 fsid
-rw------- 1 167 167 55 Apr 4 10:41 keyring
-rw------- 1 167 167 6 Apr 4 10:41 ready
-rw------- 1 167 167 3 Apr 4 08:20 require_osd_release
-rw-r--r-- 1 root root 7 Apr 4 10:43 try-write
-rw-r--r-- 1 167 167 7 Apr 4 10:46 try-write-ceph
-rw------- 1 167 167 10 Apr 4 10:41 type
-rw------- 1 167 167 2 Apr 4 10:41 whoami
Absolutely bewildering. The mapping of user is working in a regular bash shell, the problem might be with the setuser commands or a Ceph issue? I was able to find a few good resources:
ceph/ceph-ansible which looks to point at udev. IAnd there it is, a super deep issue – Ceph relies on udev rules that expect GPT tags. Let’s confirm that I’m not on GPT first (thanks to Hetzner’s awesome shiny new documentation pages):
root@all-in-one-01 ~ # gdisk /dev/nvme0n1
GPT fdisk (gdisk) version 1.0.5
Partition table scan:
MBR: MBR only
BSD: not present
APM: not present
GPT: not present
***************************************************************
Found invalid GPT and valid MBR; converting MBR to GPT format
in memory. THIS OPERATION IS POTENTIALLY DESTRUCTIVE! Exit by
typing 'q' if you don't want to convert your MBR partitions
to GPT format!
***************************************************************
Command (? for help): q
There it is – now I have two choices:
grub anyway)chownsI’m going to go for changing the drives to GPT first, because if possible I’d like to lessen the amount of custom stuff I have to do. As luck would have it sgdisk has an option called --mbrtogpt (thank you Fedora magazine author Gregory Bartholomew!) for doing just that. I added the following to my ansible automation, after the Hetzner installimage tool finishes running:
- name: Convert boot disk from MBR to GPT
command: |
sgdisk --mbrtogpt /dev/{{ first_disk_device.stdout }}
when: first_disk_device.stdout != ""
Well of course, it’s never that easy, so after a lot of scouring the internet on how to make Hetzner work with GPT properly (and figuring out you need to run --mbrtogpt with two disks), I came across A thread on hostedtalk.net in which a user named Falzo shared the answer – running grub-install after installimage to write the proper boot information out. The pattern goes like this:
after it [installimage] finishes, boot into rescue mode and create a small (~10MB) partition on each 4 TB disk, type set to bios boot (fdisk).
- figure which partition from nvme is your root-partition and mount it somewhere. f.i. /mnt (and the boot partition boot into it, if seperate, e.g. /mnt/boot)
- bind mount dev/proc/sys into that
- now chroot into that system (chroot /mnt /bin/bash)
- use grub-install to write the boot-loader into each disk (grub-install /dev/sdX).
- run update-grub in the end. reboot, and hopefully it starts correctly :wink:
Well it turns out that after trying for hours to write the perfect repeatable scripts to wipe all the partitions, add the working boot partitions and do everything else (which didn’t work), Hetzner has a secret option to force GPT! I was overjoyed, until I tried it, and it doesn’t survive a reboot (after Rook and Ceph come up). Ceph only finds one drive (so it doesn’t find the partition on the boot device) and I think the fact that it wipes that drive (and uses the drive for Ceph) is what makes the machine not boot the second time. So in the end, I have to go wtih the second option, which is writing udev rules.
I look around the internet for some guidance on this and found some great resources:
So before going on this udev adventure (again) I figured I should look around first, and what do you know, there are already some rules that are firing:
root@all-in-one-01 ~ # udevadm test /dev/ceph-231a70da-439c-4eee-b789-2f462120f0a4/osd-data-0c0745e9-b492-41de-a64c-b36ffcd1d2f2
This program is for debugging only, it does not run any program
specified by a RUN key. It may show incorrect results, because
some values may be different, or not available at a simulation run.
Load module index
Parsed configuration file /usr/lib/systemd/network/99-default.link
Parsed configuration file /usr/lib/systemd/network/73-usb-net-by-mac.link
Created link configuration context.
Reading rules file: /usr/lib/udev/rules.d/01-md-raid-creating.rules
Reading rules file: /usr/lib/udev/rules.d/40-vm-hotadd.rules
Reading rules file: /usr/lib/udev/rules.d/50-firmware.rules
Reading rules file: /usr/lib/udev/rules.d/50-rbd.rules
Reading rules file: /usr/lib/udev/rules.d/50-udev-default.rules
Reading rules file: /usr/lib/udev/rules.d/55-dm.rules
Reading rules file: /usr/lib/udev/rules.d/56-lvm.rules
Reading rules file: /usr/lib/udev/rules.d/60-autosuspend-chromiumos.rules
Reading rules file: /usr/lib/udev/rules.d/60-block.rules
Reading rules file: /usr/lib/udev/rules.d/60-cdrom_id.rules
Reading rules file: /usr/lib/udev/rules.d/60-crda.rules
Reading rules file: /usr/lib/udev/rules.d/60-drm.rules
Reading rules file: /usr/lib/udev/rules.d/60-evdev.rules
Reading rules file: /usr/lib/udev/rules.d/60-fido-id.rules
Reading rules file: /usr/lib/udev/rules.d/60-input-id.rules
Reading rules file: /usr/lib/udev/rules.d/60-persistent-alsa.rules
Reading rules file: /usr/lib/udev/rules.d/60-persistent-input.rules
Reading rules file: /usr/lib/udev/rules.d/60-persistent-storage-dm.rules
Reading rules file: /usr/lib/udev/rules.d/60-persistent-storage-tape.rules
Reading rules file: /usr/lib/udev/rules.d/60-persistent-storage.rules
Reading rules file: /usr/lib/udev/rules.d/60-persistent-v4l.rules
Reading rules file: /usr/lib/udev/rules.d/60-sensor.rules
Reading rules file: /usr/lib/udev/rules.d/60-serial.rules
Reading rules file: /usr/lib/udev/rules.d/61-autosuspend-manual.rules
Reading rules file: /usr/lib/udev/rules.d/61-persistent-storage-android.rules
Reading rules file: /usr/lib/udev/rules.d/63-md-raid-arrays.rules
Reading rules file: /usr/lib/udev/rules.d/64-btrfs-dm.rules
Reading rules file: /usr/lib/udev/rules.d/64-btrfs.rules
Reading rules file: /usr/lib/udev/rules.d/64-md-raid-assembly.rules
Reading rules file: /usr/lib/udev/rules.d/69-lvm-metad.rules
Reading rules file: /usr/lib/udev/rules.d/69-md-clustered-confirm-device.rules
Reading rules file: /usr/lib/udev/rules.d/70-joystick.rules
Reading rules file: /usr/lib/udev/rules.d/70-mouse.rules
Reading rules file: /usr/lib/udev/rules.d/70-power-switch.rules
Reading rules file: /usr/lib/udev/rules.d/70-touchpad.rules
Reading rules file: /usr/lib/udev/rules.d/70-uaccess.rules
Reading rules file: /usr/lib/udev/rules.d/71-power-switch-proliant.rules
Reading rules file: /usr/lib/udev/rules.d/71-seat.rules
Reading rules file: /usr/lib/udev/rules.d/73-seat-late.rules
Reading rules file: /usr/lib/udev/rules.d/73-special-net-names.rules
Reading rules file: /usr/lib/udev/rules.d/75-net-description.rules
Reading rules file: /usr/lib/udev/rules.d/75-probe_mtd.rules
Reading rules file: /usr/lib/udev/rules.d/78-graphics-card.rules
Reading rules file: /usr/lib/udev/rules.d/78-sound-card.rules
Reading rules file: /usr/lib/udev/rules.d/80-debian-compat.rules
Reading rules file: /usr/lib/udev/rules.d/80-drivers.rules
Reading rules file: /usr/lib/udev/rules.d/80-net-setup-link.rules
Reading rules file: /usr/lib/udev/rules.d/85-hdparm.rules
Reading rules file: /usr/lib/udev/rules.d/85-regulatory.rules
Reading rules file: /usr/lib/udev/rules.d/90-console-setup.rules
Reading rules file: /usr/lib/udev/rules.d/95-ceph-osd-lvm.rules
Reading rules file: /usr/lib/udev/rules.d/95-dm-notify.rules
Reading rules file: /usr/lib/udev/rules.d/96-e2scrub.rules
Reading rules file: /usr/lib/udev/rules.d/99-systemd.rules
Failed to open device '/sys/dev/ceph-231a70da-439c-4eee-b789-2f462120f0a4/osd-data-0c0745e9-b492-41de-a64c-b36ffcd1d2f2': No such device
Unload module index
Unloaded link configuration context.
root@all-in-one-01 /usr/lib/udev/rules.d # grep -r "ceph" *
50-rbd.rules:KERNEL=="rbd[0-9]*", ENV{DEVTYPE}=="disk", PROGRAM="/usr/bin/ceph-rbdnamer %k", SYMLINK+="rbd/%c"
50-rbd.rules:KERNEL=="rbd[0-9]*", ENV{DEVTYPE}=="partition", PROGRAM="/usr/bin/ceph-rbdnamer %k", SYMLINK+="rbd/%c-part%n"
95-ceph-osd-lvm.rules:# VG prefix: ceph-
95-ceph-osd-lvm.rules: ENV{DM_VG_NAME}=="ceph-*", \
95-ceph-osd-lvm.rules: OWNER:="ceph", GROUP:="ceph", MODE:="660"
95-ceph-osd-lvm.rules: ENV{DM_VG_NAME}=="ceph-*", \
95-ceph-osd-lvm.rules: OWNER="ceph", GROUP="ceph", MODE="660"
root@all-in-one-01 /usr/lib/udev/rules.d # cat 95-ceph-osd-lvm.rules
# OSD LVM layout example
# VG prefix: ceph-
# LV prefix: osd-
ACTION=="add", SUBSYSTEM=="block", \
ENV{DEVTYPE}=="disk", \
ENV{DM_LV_NAME}=="osd-*", \
ENV{DM_VG_NAME}=="ceph-*", \
OWNER:="ceph", GROUP:="ceph", MODE:="660"
ACTION=="change", SUBSYSTEM=="block", \
ENV{DEVTYPE}=="disk", \
ENV{DM_LV_NAME}=="osd-*", \
ENV{DM_VG_NAME}=="ceph-*", \
OWNER="ceph", GROUP="ceph", MODE="660"
root@all-in-one-01 /usr/lib/udev/rules.d # udevadm info /dev/ceph-231a70da-439c-4eee-b789-2f462120f0a4/osd-data-0c0745e9-b492-41de-a64c-b36ffcd1d2f2
P: /devices/virtual/block/dm-9
N: dm-9
L: 0
S: disk/by-id/dm-uuid-LVM-O4THSvVeyOmMZhMOWl6j9Nnp2QinMA29Gvhz55Isq2KDBl1RldvY2hcMvcA4FMDE
S: disk/by-id/dm-name-ceph--231a70da--439c--4eee--b789--2f462120f0a4-osd--data--0c0745e9--b492--41de--a64c--b36ffcd1d2f2
E: DEVPATH=/devices/virtual/block/dm-9
E: DEVNAME=/dev/dm-9
E: DEVTYPE=disk
E: MAJOR=253
E: MINOR=9
E: SUBSYSTEM=block
E: USEC_INITIALIZED=624379520
E: DM_UDEV_DISABLE_DM_RULES_FLAG=1
E: DM_UDEV_DISABLE_SUBSYSTEM_RULES_FLAG=1
E: DM_UDEV_PRIMARY_SOURCE_FLAG=1
E: DM_SUBSYSTEM_UDEV_FLAG0=1
E: DM_ACTIVATION=1
E: DM_NAME=ceph--231a70da--439c--4eee--b789--2f462120f0a4-osd--data--0c0745e9--b492--41de--a64c--b36ffcd1d2f2
E: DM_UUID=LVM-O4THSvVeyOmMZhMOWl6j9Nnp2QinMA29Gvhz55Isq2KDBl1RldvY2hcMvcA4FMDE
E: DM_SUSPENDED=0
E: DM_UDEV_RULES=1
E: DM_UDEV_RULES_VSN=2
E: DM_VG_NAME=ceph-231a70da-439c-4eee-b789-2f462120f0a4
E: DM_LV_NAME=osd-data-0c0745e9-b492-41de-a64c-b36ffcd1d2f2
E: DM_NOSCAN=1
E: DM_UDEV_DISABLE_OTHER_RULES_FLAG=1
E: DEVLINKS=/dev/disk/by-id/dm-uuid-LVM-O4THSvVeyOmMZhMOWl6j9Nnp2QinMA29Gvhz55Isq2KDBl1RldvY2hcMvcA4FMDE /dev/disk/by-id/dm-name-ceph--231a70da--439c--4eee--b789--2f462120f0a4-osd--data--0c0745e9--b492--41de--a64c--b36ffcd1d2f2
E: TAGS=:systemd:
OK, well that’s weird – it seems like this udev would definitely fire, why is it not firing when the machine restarts? I can understand the partition OSDs to not come up (the udev rules only mention disks, not partition types), but none of the OSDs come up after a restart. Ther’es gotta be something that changes – does DM_VG_NAME not work out? Are the mounts not permanent? The only way to find out is to restart and crash teh system again, at least this time I have some information.
There’s also the prospect of running a command like ceph-volume lvm activate I do know where on disk the ceph OSDs are, I could run the appropriate lvm activation commands which SHOULD enable systemd units that work at boot time. I’ll do the ceph-volume lvm activate --all beore boot time just in case it works:
root@all-in-one-01 /usr/lib/udev/rules.d # ceph-volume lvm activate --all
--> Activating OSD ID 9 FSID eee12e03-8b62-49bc-ba52-9f3e9aae0de8
Running command: /usr/bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-9
--> Executable selinuxenabled not in PATH: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-9
Running command: /usr/bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-231a70da-439c-4eee-b789-2f462120f0a4/osd-data-0c0745e9-b492-41de-a64c-b36ffcd1d2f2 --path /var/lib/ceph/osd/ceph-9 --no-mon-config
Running command: /usr/bin/ln -snf /dev/ceph-231a70da-439c-4eee-b789-2f462120f0a4/osd-data-0c0745e9-b492-41de-a64c-b36ffcd1d2f2 /var/lib/ceph/osd/ceph-9/block
Running command: /usr/bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-9/block
Running command: /usr/bin/chown -R ceph:ceph /dev/mapper/ceph--231a70da--439c--4eee--b789--2f462120f0a4-osd--data--0c0745e9--b492--41de--a64c--b36ffcd1d2f2
Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-9
Running command: /usr/bin/systemctl enable ceph-volume@lvm-9-eee12e03-8b62-49bc-ba52-9f3e9aae0de8
stderr: Created symlink /etc/systemd/system/multi-user.target.wants/ceph-volume@lvm-9-eee12e03-8b62-49bc-ba52-9f3e9aae0de8.service → /lib/systemd/system/ceph-volume@.service.
Running command: /usr/bin/systemctl enable --runtime ceph-osd@9
stderr: Created symlink /run/systemd/system/ceph-osd.target.wants/ceph-osd@9.service → /lib/systemd/system/ceph-osd@.service.
Running command: /usr/bin/systemctl start ceph-osd@9
--> ceph-volume lvm activate successful for osd ID: 9
... repeated 9 more times for the other OSDs ...
Well the command succeeded (and the permissions in the folder haven’t changed), so let’s see if I can restart the machine and have everything not go wrong.
Unfortunately, running ceph-volume lvm activate --all didn’t fix anything, because the real issue was that when I set up the machine, I installed ceph via apt, which created a ceph user that clashed with the Rook-managed ceph user!. The path I took to stumbling onto this solution was:
--setuser and --setgroup from the OSD pods (the pod came up Running immediately)/etc/passwd and find that the ceph user in there actually had a different UID/GID than 167ceph user with the UID/GID 167 (this worked)ceph installation all together
apt-driven ceph installation ansible code) and it worked!I’m leaving all the exploration in this post just in case someone finds it useful (or it comes up in a search), but the real solution was just… don’t install ceph before Rook tries to. If you absolutely have to, make sure to ensure the ceph user has the same UID/GID that Rook is going to try and give it 167. You can read all about it (and lots of me talking to myself) in the issue I filed on Github.
Finally, with everything working I can run the two test pods, on two different storage pools (one replicated and one not):
$ k get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-replicated Bound pvc-d4d4710a-f99c-4af7-badb-066ab99c06de 1Gi RWO rook-ceph-block-replicated-osd 44s
test-single Bound pvc-dda4317e-456a-4a1e-8f22-43aa89a57402 1Gi RWO rook-ceph-block-single-osd 3m38s
$ k get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-d4d4710a-f99c-4af7-badb-066ab99c06de 1Gi RWO Delete Bound default/test-replicated rook-ceph-block-replicated-osd 58s
pvc-dda4317e-456a-4a1e-8f22-43aa89a57402 1Gi RWO Delete Bound default/test-single rook-ceph-block-single-osd 3m52s
$ k get pods
NAME READY STATUS RESTARTS AGE
test-replicated 1/1 Running 0 75s
test-single 1/1 Running 0 4m8s
A little more testing just to make sure that I can do it:
$ k exec -it test-single -n default -- /bin/ash
/ # echo "this is a test file" > /var/data/test-file.txt
/ #
$ k delete pod test-single -n default
pod "test-single" deleted
$ k get pv -n default
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-0551a170-d8ce-4802-8e02-d7fdf92725a3 1Gi RWO Delete Bound default/test-single rook-ceph-block-single-osd 5m4s
pvc-ec386b59-cf42-42bd-8e19-c8b173f22ca6 1Gi RWO Delete Bound default/test-replicated rook-ceph-block-replicated-osd 5m1s
$ k get pods
NAME READY STATUS RESTARTS AGE
test-replicated 1/1 Running 0 5m15s
$ make test-single
make[2]: Entering directory '/home/mrman/code/foss/k8s-storage-provider-benchmarks/kubernetes/rook'
kubectl --kubeconfig=/home/mrman/code/foss/k8s-storage-provider-benchmarks/ansible/output/all-in-one-01.k8s.storage-benchmarks.experiments.vadosware.io/var/lib/k0s/pki/admin.conf apply -f test-single.pvc.yaml
persistentvolumeclaim/test-single unchanged
kubectl --kubeconfig=/home/mrman/code/foss/k8s-storage-provider-benchmarks/ansible/output/all-in-one-01.k8s.storage-benchmarks.experiments.vadosware.io/var/lib/k0s/pki/admin.conf apply -f test-single.pod.yaml
pod/test-single created
make[2]: Leaving directory '/home/mrman/code/foss/k8s-storage-provider-benchmarks/kubernetes/rook'
$ k exec -it test-single -n default -- /bin/ash
/ # ls /var/data
lost+found/ test-file.txt
/ # cat /var/data/test-file.txt
this is a test file
And yes, a similar set of steps worked for the test-replicated pod as well. Finally we can move on to testing some other setups!
STORAGE_PROVIDER=rook-ceph-zfs (skipped)At first it doesn’t seem like Rook supports ZFS:
Searching for “zfs” in the codebase brings up a mention of go-zfs, but not a single documentation mention the issues above (and some others) no other codebase mentions. ZFS isn’t a well-trodden use case of Rook right now but I’m going to give it a shot anyway, and give up at the first inkling of trouble. ZFS still doesn’t support O_DIRECT, but it looks like zvols do work as underlying storage (when not created by Rook) in issue #2425) so…. I guess it’s worth a shot.
Let’s hope this is easier than LVM. After breaking out the ZFS zpool chapter of the FreeBSD handbook and giving it a quick skim, I think I can get away with just creating a zpool with these disparate devices… I also leaned on some internet for figuring out what some nice default settings might be:
There are a lot of ways to tune ZFS and it usually wants hmogeneous drives, but I have a nonstandard case – a drive with 512GB and a partition on another drive with ~412GB. I’d like for ZFS to perform it’s best within reason so a little bit of tuning is pretty reasonable, nothing fancy though. First let’s take a look at the drive:
root@all-in-one-01 ~ # fdisk -l /dev/nvme0n1
Disk /dev/nvme0n1: 476.96 GiB, 512110190592 bytes, 1000215216 sectors
Disk model: SAMSUNG MZVLB512HBJQ-00000
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xa0dc88d2
OK I should be able to get away with the following setup/options:
compression=lz4 (IIRC this is the default but doesn’t hurt to be sure)atime=off (minimze IO used for updating timestamps)recordsize=16k (8k is good for postgres, multiples of 8k are probably not bad since recordsize is the max size, not required size)logbias=throughput (good for DB workloads and small-ish files)xattr=sa (attributes stored at inodes, should result in less IO requests when extended attributese are in use)quota=396G (The remainig space on the partition is 396G and the other drive is 512, if I want space for duplicates pretty sure I need to take the smaller of the two drives here. 396G of NVMe is not a bad amount of memory)Well here’s what it looks like to set up a zpool with two mirrored identical size drives for ZFS:
root@all-in-one-01 ~ # sgdisk -R /dev/nvme1n1 /dev/nvme0n1 # Careful, the arguments are switched, this copies the partition table of the second disk *to* the first disk
root@all-in-one-01 ~ # wipefs -a /dev/nvme1n1p5 # Wipe the 5th partition of the second disk (the leftover space, in my setup) just in case
root@all-in-one-01 ~ # zpool create tank mirror /dev/nvme0n1p5 /dev/nvme1n1p5 # create a simple zpool mirror of the two partitions
root@all-in-one-01 ~ # zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
tank 394G 116K 394G - - 0% 0% 1.00x ONLINE -
It’s a shame I can’t give the entirety of both drives easily to ZFS, maybe I’ll get the chance to look into diskless alpine at some point. While we’re here talking about efficiency, the step before installing ceph actually brings one more thing comes to mind – with the available features of Ceph’s Bluestore, does it even make sense to run Ceph on ZFS?
The answer is actually a resounding no – It doesn’t make sense to run Ceph on Bluestore, because where LVM doesn’t really add much overhead, all of ZFS’s features are actually extra overhead that are already implemented in Bluestore:
It actually doesn’t make sense to test Ceph on ZFS (and if we want to test raw ZFS there’ll be a chance with the OpenEBS ZFS-powered localPVs). The first indication of this is when you stop think how you should feed 2 disks to Ceph – Both of the zvols that you would create are actually already replicated so it’s actually quite weird to give them to Ceph to make another level of replication out of. After finding some agreeing voices I’m convinced for now that it’s not reasonable to make (since Bluestore exists now) and I’m going to leave the discussion here without implementing it.
STORAGE_PROVIDER=openebs-mayastor#Mayastor is the latest product developed by OpenEBS – Rust-powered, NVMe-aware NVMe-oF-ready (I don’t have this tech at my disposal but it’s worth mentioning), and a move away from simple uzfs (which underpins OpenEBS’s cStor engine). I remember some emails back and forth with Philippe and Evan from Mayadata and I think that’s where I first heard of the effort, but It’s certainly looking like one of the favorites to be what I switch to.
I’ve got a few reasons for including Mayastor:
As of right now there are some very real downsides to using Mayastor:
ctrl_loss_tmo)If the last point is a bit obtuse/hard to understand, my apologies – it’s a bit hard to read what they mean to say in the original text:
However a Mayastor volume is currently accessible to an application only via a single target instance (NVMe-oF, or iSCSI) of a single Mayastor pod. If that pod terminates (through the loss of the worker node on which it’s scheduled, excution failure, pod eviction etc.) then there will be no viable I/O path to any remaining healthy replicas and access to data on the volume cannot be maintained.
So… If a node goes down, you’re up the creek without a paddle? Can replicas on other nodes not become master with the usual async/sync replication tradeoff considerations? Generally Container Attached Storage works like this:
SO I think what they’re trying to say is if a node goes down and it takes down the Mayastor Receiver pod and/or disk, you will not be able to continue using the App (at all, or without some manual intervention) with a different receiver pod or replica, even though the data is safe (assuming it was synchronously replicated). It’s not clear exactly what failover looks like, but I guess I’ll figure that out. Lack of HA is pretty inconvenient but since we’re just testing it’s worth a look to see if the performance of Mayastor warrants jumping in early (before multipath is done) is worth it.
OpenEBS products have always been pretty easy to install generally – at least Jiva and cStor were last time I tried them – so hopefully this isn’t too hard either. The Mayastor install documentation are pretty comprehensive and easy to follow. I won’t get into it too much here, but the deployment docs are fantastic as well, and pretty self-explanatory. There is good explanation behind all the pieces needed to get Mayastor up and running, instead of the “just curl and apply this large file” approach, which I greatly appreciate. The pieces are:
MayastorPool CRDmoac ServiceAccountmoac ClusterRole and ClusterRoleBindingDeployment (Mayastor uses this as a message bus)DaemonsetDeploymentDaemonsetOnce all of this is done, checking that I have installed everything seems to be pretty easy – all I have to do is run kubectl -n mayastor get msn which should return exactly one MayastorNode (a node with Mayastor enabled) object. Let’s see if we got it one shot:
$ k get msn
NAME STATE AGE
all-in-one-01 online 82s
OK it wasn’t quite “one shot”, I’m hiding a little bit of futzing around (basically me making sure I had everything automated perfectly), but this up to here was really easy to set up. Logs from the control plane:
$ k logs -f moac-5cc949c7bb-xqm7h -c moac
Apr 05 14:25:54.685 info [csi]: CSI server listens at /var/lib/csi/sockets/pluginproxy/csi.sock
Apr 05 14:25:54.690 info [node-operator]: Initializing node operator
Apr 05 14:25:54.699 error [nats]: Error: getaddrinfo ENOTFOUND nats
Apr 05 14:25:54.719 info [pool-operator]: Initializing pool operator
Apr 05 14:25:54.732 info: Warming up will take 7 seconds ...
Apr 05 14:26:01.733 info [volume-operator]: Initializing volume operator
Apr 05 14:26:01.766 info [api]: API server listening on port 4000
Apr 05 14:26:01.767 info: MOAC is warmed up and ready to 🚀
Apr 05 14:26:04.707 info [nats]: Connected to NATS message bus at "nats"
Apr 05 14:26:15.149 info [node]: new mayastor node "all-in-one-01" with endpoint "xxx.xxx.xxx.xxx:10124"
Apr 05 14:26:15.153 info [node-operator]: Creating node resource "all-in-one-01"
Apr 05 14:26:15.154 info [registry]: mayastor on node "all-in-one-01" and endpoint "xxx.xxx.xxx.xxx:10124" just joined
Nice signal/noise ratio log messages, looks like I’m ready to go as far as setup goes!
MayastorPoolsNow that we’ve got the Mayastor control and data plane installed, let’s setup our Mayastor pools – time to use that MayastorPool CRD. The Mayastor configuration documentation is a pretty easy read and lays everything out well. Automatic discovery like in the case of Rook would have been pretty awesome, but a CRD-driven approach is pretty nice as well. It’s not hard to imagine a privileged pod that spins up and automatically finds empty space to create CRDs for either, which is pretty nice.
The caveat of a “pool” being one disk for now rears it’s ugly head a bit here, but there are some cool innovative options in the types of schemes that Mayastor can handle (this is some cool engineering on the part of OpenEBS/MayaData):
aio)io_uringOpenEBS definitely gets some points in the innovation space here, these are some nice features and I’ll have to find some way to account for them in testing. Anyway, getting back to my setup, it’s actually just two regular ‘ol connected NVMe – part of one disk (a ~396GB partition) and a whole disk (512GB). Converted to MayastorPool format:
---
apiVersion: openebs.io/v1alpha1
kind: MayastorPool
metadata:
name: first-disk-partition
namespace: mayastor
spec:
# TODO: (clustered) this file needs to be replicated per-worker node
node: all-in-one-01 # hostname
disks:
- /dev/nvme0n1p5
---
apiVersion: openebs.io/v1alpha1
kind: MayastorPool
metadata:
name: second-disk
namespace: mayastor
spec:
# TODO: (clustered) this file needs to be replicated per-worker node
node: all-in-one-01 # hostname
disks:
- /dev/nvme1n1
We can confirm that everything got set up by checking the status of the MSPs (MayastorPools) and making sure they’re Online:
$ k get msp
NAME NODE STATE AGE
first-disk-partition all-in-one-01 online 104s
second-disk all-in-one-01 online 4s
Super easy – there’s a bit of a gap in age because I realized I actually had a typo in the name of the second disk! The partition worked right away. Let’s see if we’ve got some logs worth looking at in the control plane. Nice and legible logs with clear explanations of what happened:
Apr 05 14:34:00.398 info [node]: Created pool "first-disk-partition@all-in-one-01"
Apr 05 14:34:02.175 error [pool-operator]: Failed to create pool "second-disk": Error: 13 INTERNAL: bdev /dev/nvme1p1 not found
Apr 05 14:34:02.180 warn [pool-operator]: Ignoring modification to pool "second-disk" that does not exist
Apr 05 14:34:02.180 warn [pool-operator]: Ignoring modification to pool "second-disk" that does not exist
Apr 05 14:35:06.757 warn [pool-operator]: Ignoring modification to pool "second-disk" that does not exist
Apr 05 14:35:40.284 info [node]: Created pool "second-disk@all-in-one-01"
That’s pretty refreshing – this setup has been super easy so far, let’s finish it up and try it out.
StorageClassesIn traditional Kubernetes style, we’ll have to set up the StorageClass that represents the volumes. Pretty straight forward, but we have two options here – iSCSI and NVMe-oF (over TCP). There’s a bit of a combinatoric explosion here since there are 2 methods and 2 situations I’d like to test (no replication and with replication) so we’ll need at least 4 classes to cover the combinations, I’ll show two examples:
maystor-nvmf-single.storageclass.yaml:
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mayastor-nvmf-single
provisioner: io.openebs.csi-mayastor
parameters:
repl: '1' # replication factor
protocol: nvmf
maysator-iscsi-replicated.storageclass.yaml:
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mayastor-iscsi-replicated
provisioner: io.openebs.csi-mayastor
parameters:
repl: '2' # replication factor
protocol: iscsi
Very easy to make these, and that’s all I need. With the StorageClasses in place we can move on to testing the final bit.
OK, let’s make sure this works by making some pods. There are lots more pods to make this time since there are more combinations so I won’t show all of them but here’s one PVC + Pod combination:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-single-nvmf
namespace: default
spec:
storageClassName: mayastor-nvmf-single
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:
name: test-single-nvmf
namespace: default
spec:
containers:
- name: alpine
image: alpine
command: ["ash", "-c", "while true; do sleep infinity; done"]
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 0.5
memory: "512Mi"
requests:
cpu: 0.5
memory: "512Mi"
volumeMounts:
- mountPath: /var/data
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: test-single-nvmf
Pretty simple to understand, I make a 1GB PVC and mount it from a Pod – this particular example went off without a hitch:
$ k get pvc
k gNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-single-nvmf Bound pvc-af1828de-a240-4853-85d3-94f832cb2a55 1Gi RWO mayastor-nvmf-single 14s
$ k get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-af1828de-a240-4853-85d3-94f832cb2a55 1Gi RWO Delete Bound default/test-single-nvmf mayastor-nvmf-single 16s
$ k get pod
NAME READY STATUS RESTARTS AGE
test-single-nvmf 1/1 Running 0 16s
Working just like we want! I’ll spare you the content test (make a pod, add some content to the mounted PV, delete the pod, yadda yadda yadda) – it works!
Well this post certainly took longer than I thought – Ceph took much longer to install than I imagined, mostly due to my own errors. Ceph does have a fair bit more moving parts than Mayastor and it certainly showed – at first I was a very annoyed at having to try and “catch” the right pod’s logs before they disappeared, and it was kind of hard to tell where in the flowchart of a setup Rook was. I’d probably have been a lot happier and things might have gone smoother if I just did the curl ... | kubectl apply - thing but that’s just not how I roll.
OpenEBS Mayastor was a breeze in comparison to Ceph, but there are some pretty big feature holes in it (as of now anyway), we’ll see how they stack up when performance time comes. Looking at the Ceph is the front-runner in terms of reliability (remember, if it’s good enough for CERN you) and feature set so I’m glad to be able to properly test it this time around (versus last time limiting myself to hostPath and OpenEBS).
For your sake I hope you didn’t read all of this, but if you did, you should definitely subscribe to my mailing list.