DDG search drop in powered by ddg.patdryburgh.com
tl;dr - Finally, the results of the benchmarking. You can find the code on GitLab. There are some issues with the benchmarks but there was enough decent data to make a decision for me at least. As far as which storage plugins I’m going to run, I’m actually going to run both OpenEBS Mayastor and Ceph via Rook on LVM. I look forward to emails from users/corporations/devrel letting me know how I misused their products if I did – please file an issue on GitLab!
Thanks to /u/joshimoo who noted on reddit that I missed Longhorn's support for RWX volumes along with Harvester which supports live migration with KubeVirt. I've added a section that basically says exactly what's in this update to the post.
NOTE: This a multi-part blog-post!
In part 4 we worked through getting the testing tools set up, figuring out how to get our results back out, and now we can finally make use of that beautiful data!
Thanks for sticking with me (those of you that did) all the way here – I’m sure it must have felt like I was doing some sort of “growth hack” drip-feed but I just didn’t want to drop 6 posts all at the same time once I realized how big this series was going to have to be. No one wants to see a scroll bar nub the size of an atom.
NOTE: No you’re not crazy, this post series was reduced from 6 parts to 5, I combined Part 6 into this post just so I could be done quicker. I need to actually get back to shipping software.
To keep the tables narrow I used some acronyms, so a legend is required:
usec)fio, some values are un-knowable)Remember, “RW” does not stand for “read/write”!
This round of testing is on a single node this means a single node with a single copy – i.e. your data is not safe but it probably got there fast. As you might expect, the theoretical limit for this a hostPath volume, and the storage plugin that should be closest to the upper bound is OpenEBS LocalPV Hostpath.
fio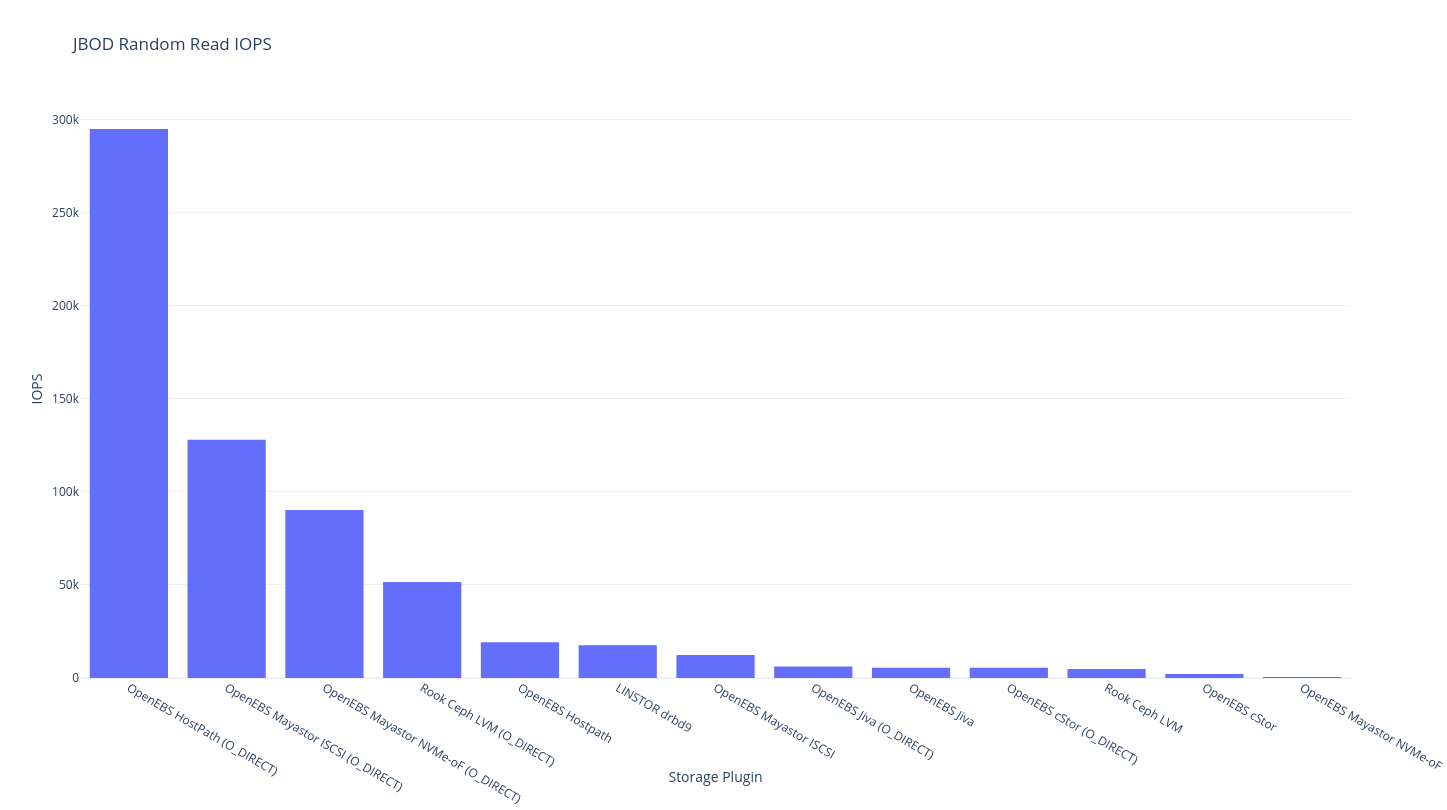
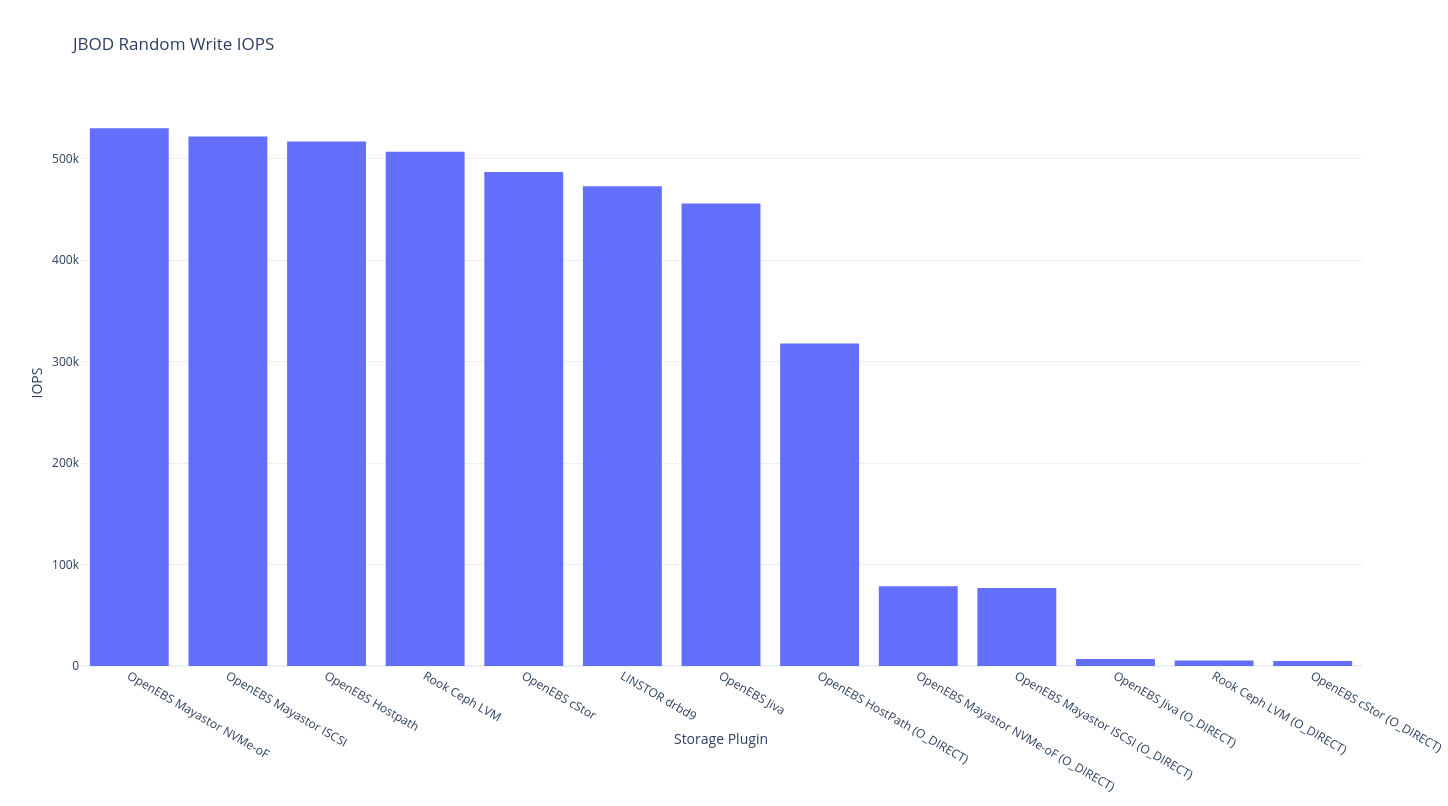
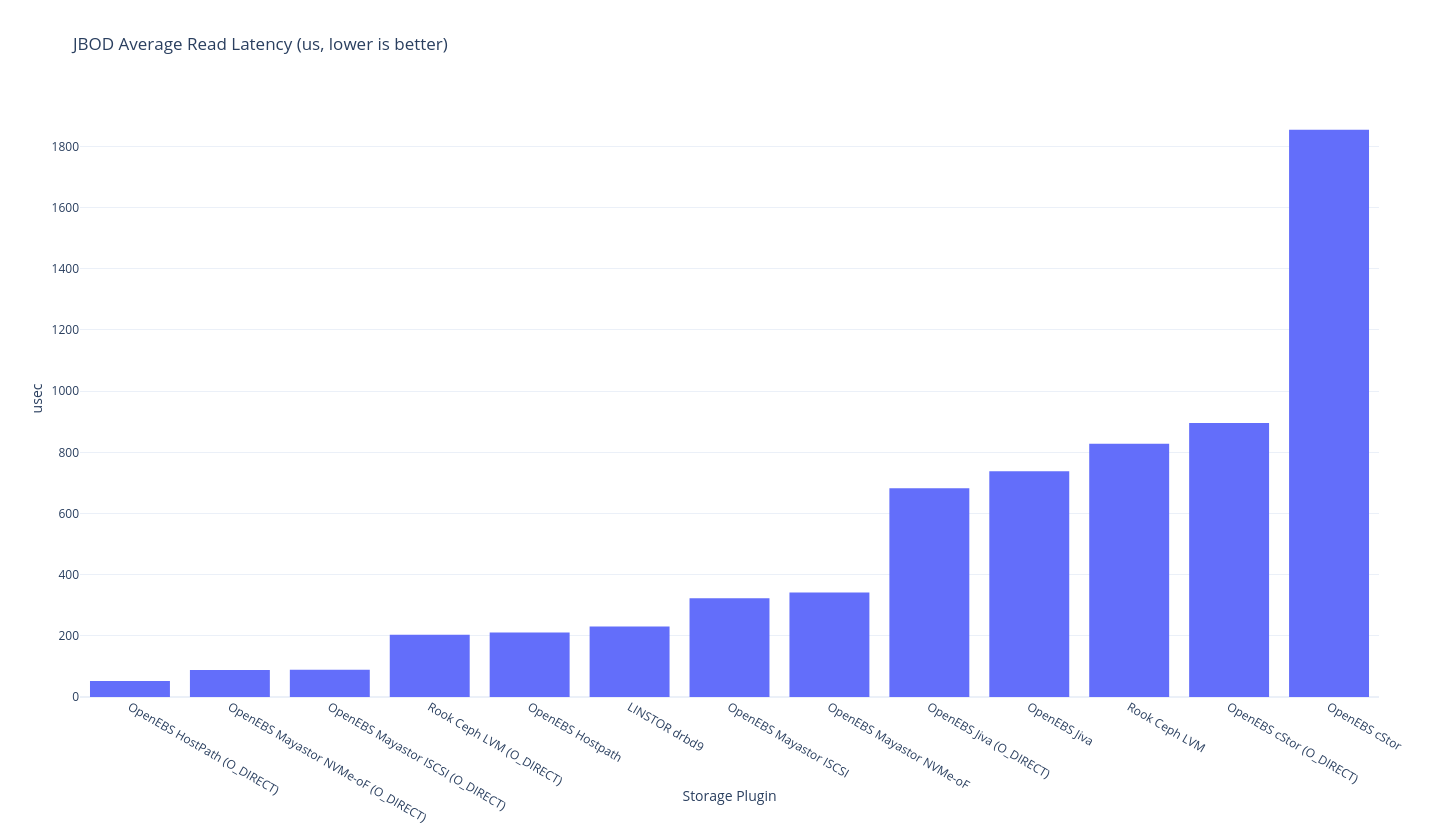
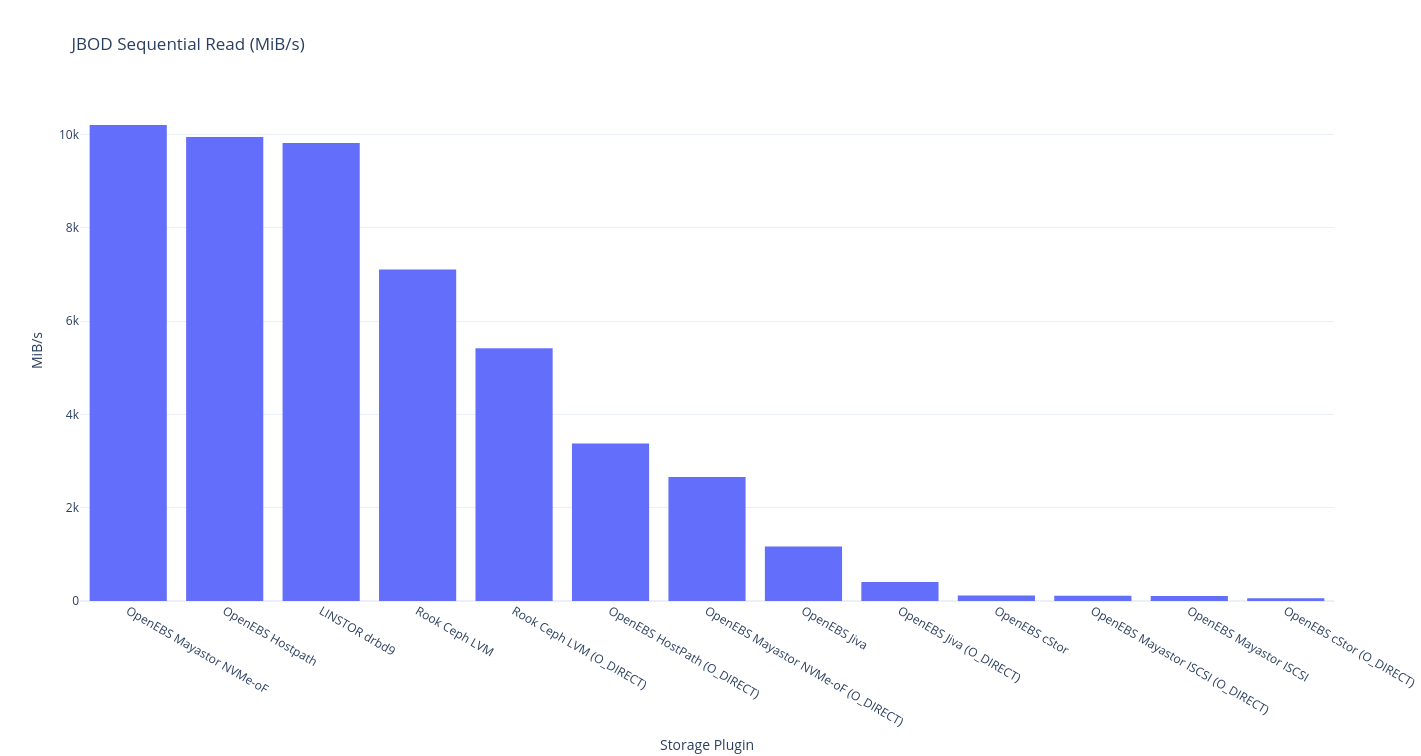
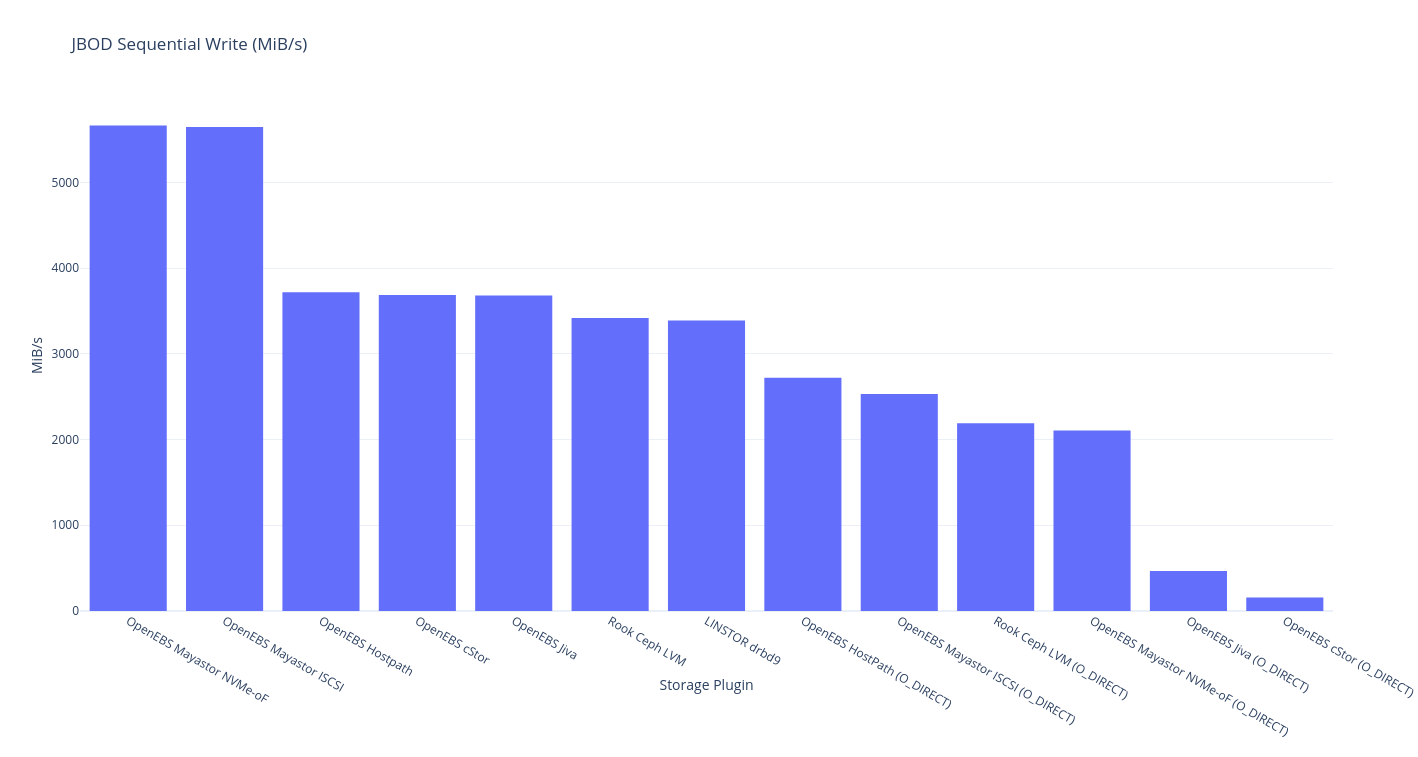
If you’re into tabular data (powered by Simple DataTables):
| Plugin (JBOD, no replicas) | RR IOPS | RR BW | RW IOPS | RW BW | Avg RL | Avg WL | SR | SW | Mixed RR IOPS | Mixed RW IOPS |
|---|---|---|---|---|---|---|---|---|---|---|
OpenEBS HostPath (O_DIRECT) |
295,000 | 1428 | 318,000 | 2652 | 52.69 | 13.53 | 3378 | 2721 | 252,000 | 83,900 |
OpenEBS Mayastor ISCSI (O_DIRECT) |
128,000 | 1399 | 76,800 | 2028 | 89.18 | 78.72 | 111 | 2532 | 78,100 | 26,300 |
OpenEBS Mayastor NVMe-oF (O_DIRECT) |
90,300 | 1398 | 78,500 | 2053 | 88.55 | 86.66 | 2660 | 2105 | 64,700 | 21,600 |
Rook Ceph LVM (O_DIRECT) |
51,600 | 4141 | 5307 | 499 | 203.46 | ??? | 5419 | 2190 | 4726 | 1582 |
| OpenEBS Hostpath | 19,200 | 6079 | 517,000 | 4135 | 210.88 | ??? | 9943 | 3718 | 18,500 | 6194 |
| LINSTOR drbd9 | 17,600 | 6074 | 473,000 | 3860 | 230.79 | ??? | 9815 | 3389 | 17,200 | 5708 |
| OpenEBS Mayastor ISCSI | 12,300 | 4582 | 522,000 | 5210 | 323.12 | ??? | 105 | 5645 | 11,800 | 3921 |
OpenEBS Jiva (O_DIRECT) |
6129 | 235 | 6883 | 324 | 682.68 | 570.70 | 409 | 466 | 4470 | 1491 |
| OpenEBS Jiva | 5564 | 218 | 456,000 | 4046 | 738 | ??? | 1169 | 3681 | 3486 | 1157 |
OpenEBS cStor (O_DIRECT) |
5454 | 159 | 4983 | 180 | 895.86 | 991.47 | 57.3 | 156 | 3942 | 1311 |
| Rook Ceph LVM | 4883 | 268 | 507,000 | 4007 | 828.36 | ??? | 7103 | 3416 | 4544 | 1519 |
| OpenEBS cStor | 2190 | 34.2 | 487,000 | 4142 | 1854.37 | ??? | 118 | 3687 | 923 | 304 |
| OpenEBS Mayastor NVMe-oF | 11.800 | 4640 | 530,000 | 5196 | 341.55 | ??? | 10,200 | 5662 | 11,700 | 3666 |
pgbench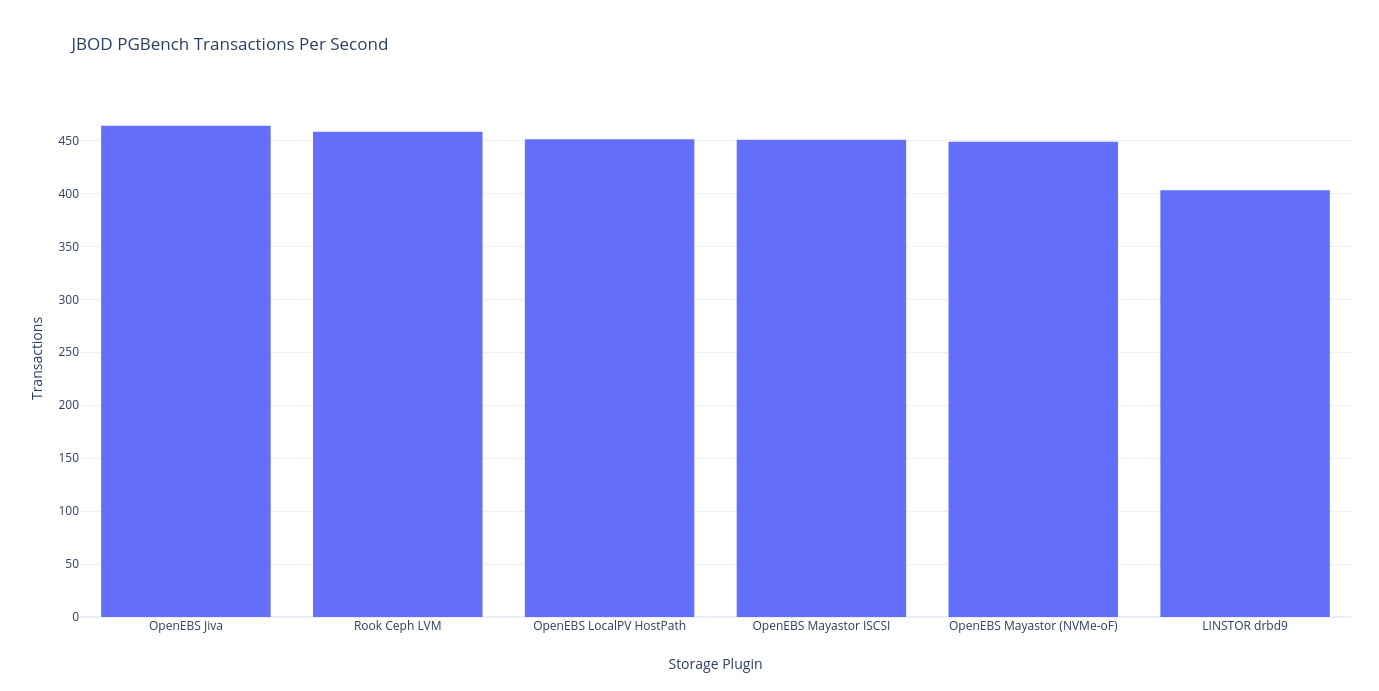
And if you’re into tabular data:
| Plugin (JBOD, no replicas) | # clients | # threads | transactions/client | Latency Avg (ms) | tps w/ establish |
|---|---|---|---|---|---|
| LINSTOR drbd9 | 1 | 1 | 10 | 2.482 | 402.97 |
| OpenEBS Jiva | 1 | 1 | 10 | 2.156 | 463.85 |
| OpenEBS LocalPV HostPath | 1 | 1 | 10 | 2.216 | 451.18 |
| OpenEBS Mayastor ISCSI | 1 | 1 | 10 | 2.218 | 450.82 |
| OpenEBS Mayastor (NVMe-oF) | 1 | 1 | 10 | 2.228 | 448.90 |
| Rook Ceph LVM | 1 | 1 | 10 | 2.182 | 458.23 |
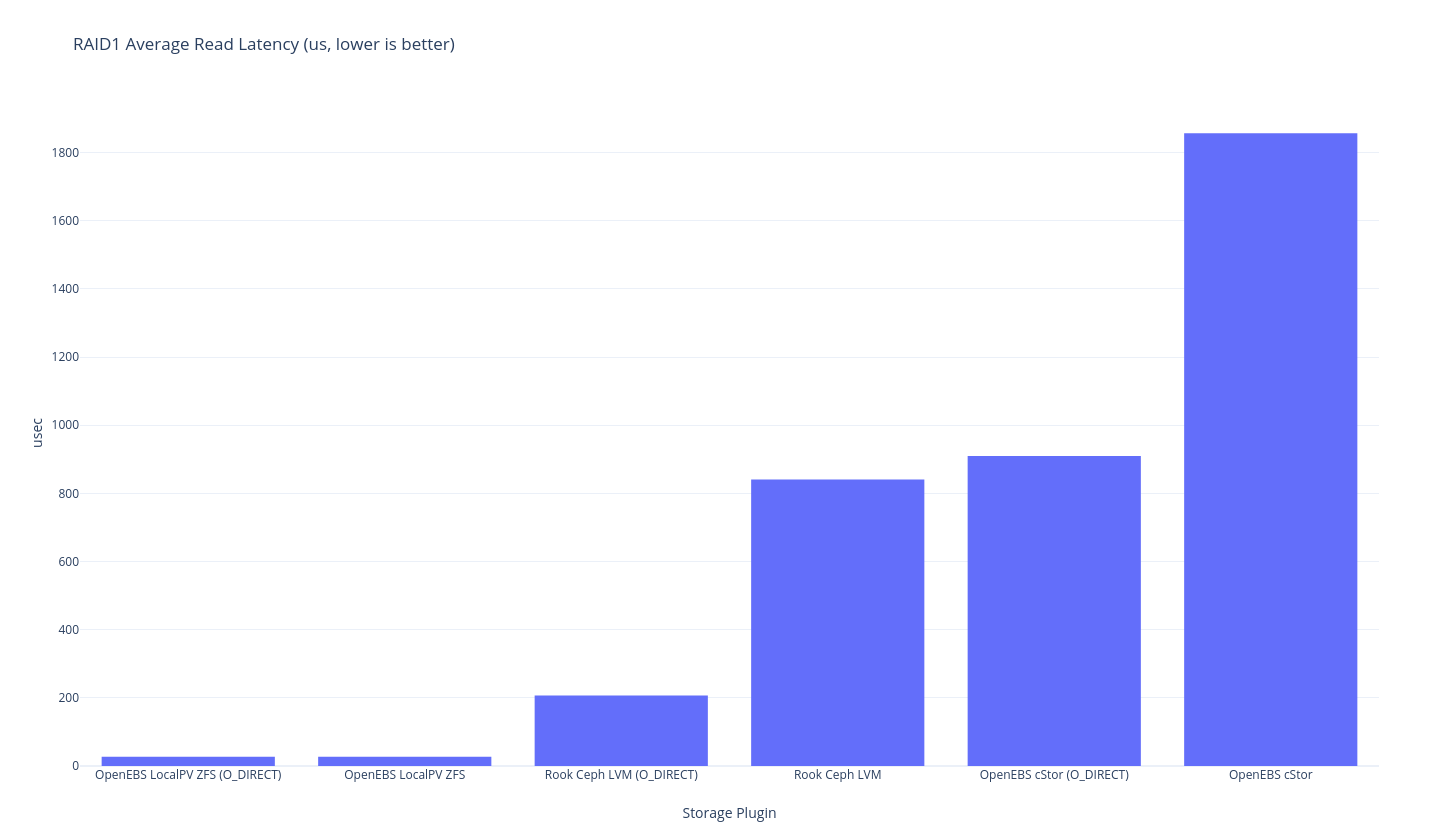
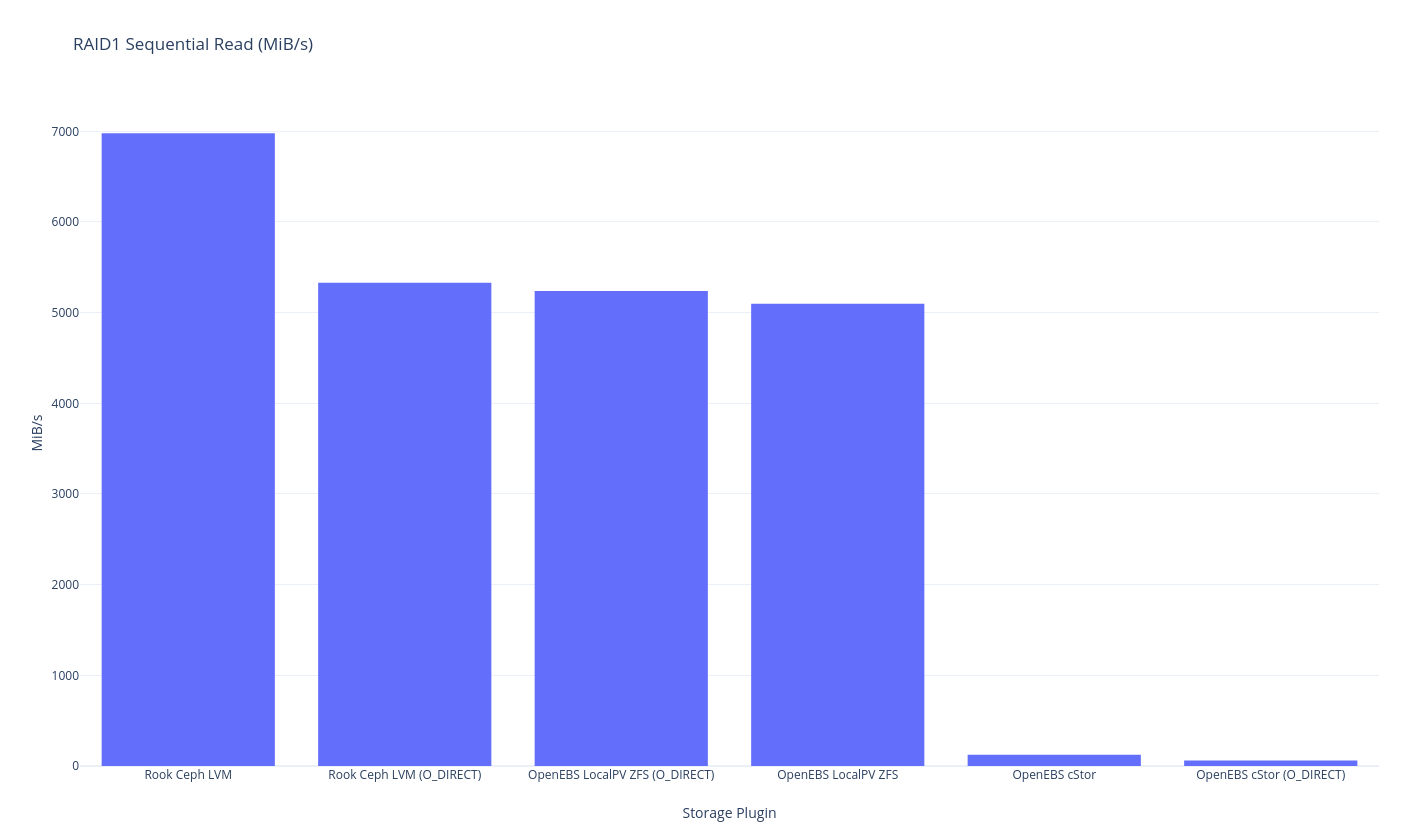
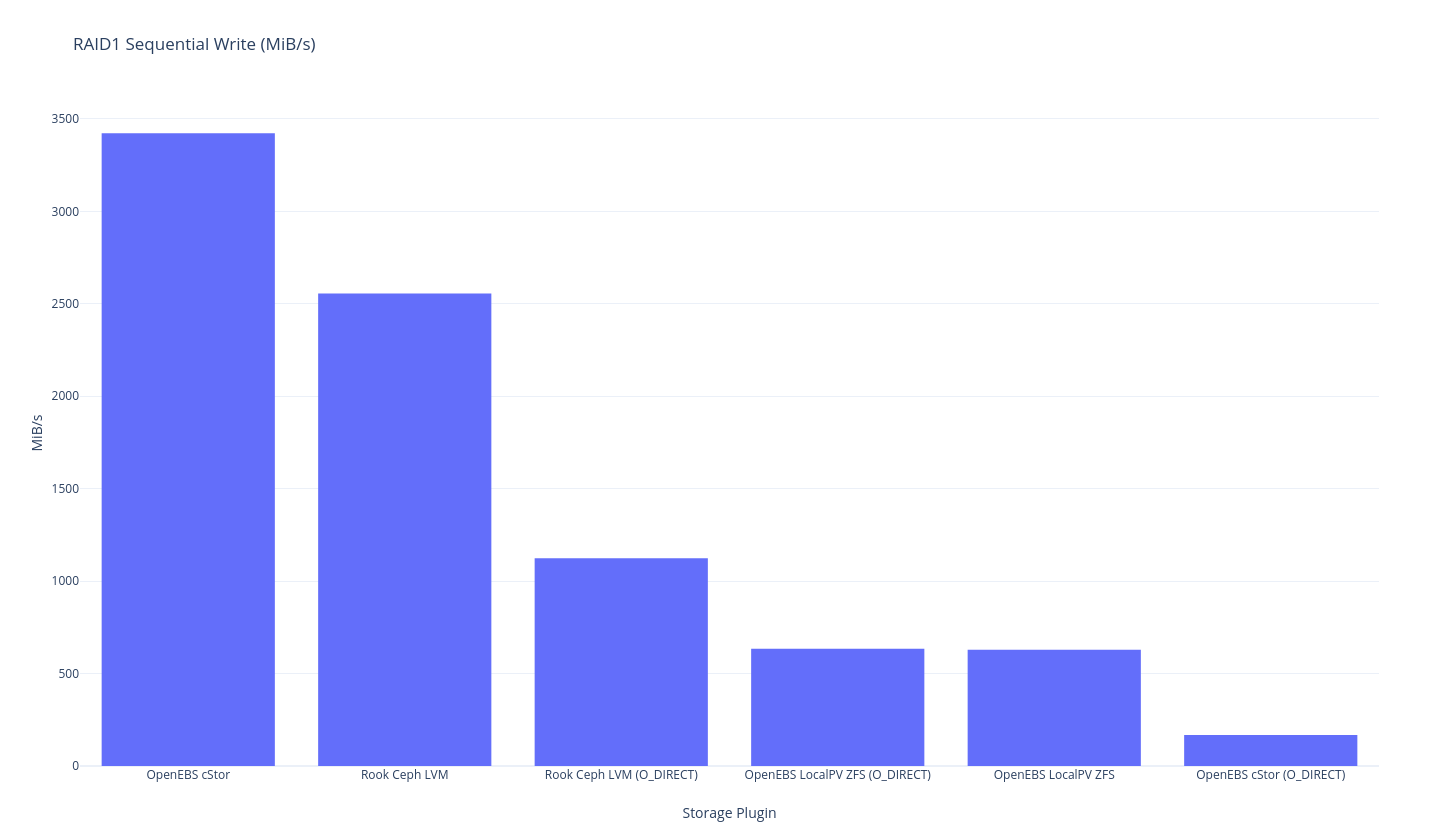
As previously mentioned this round of testing is single node, so “RAID1” is the traditional meaning of RAID1 – duplicated data – in this case, with 2 disks. The closest we might get to perfection here would be mirrored LVM, but I don’t think we have a benchmark that is quite in that area. The closest thing we have is OpenEBS LocalPV ZFS because the underlying ZFS pool is mirrored but ZFS has a heavier overhead than LVM so let’s just see what the results shape up as.
fio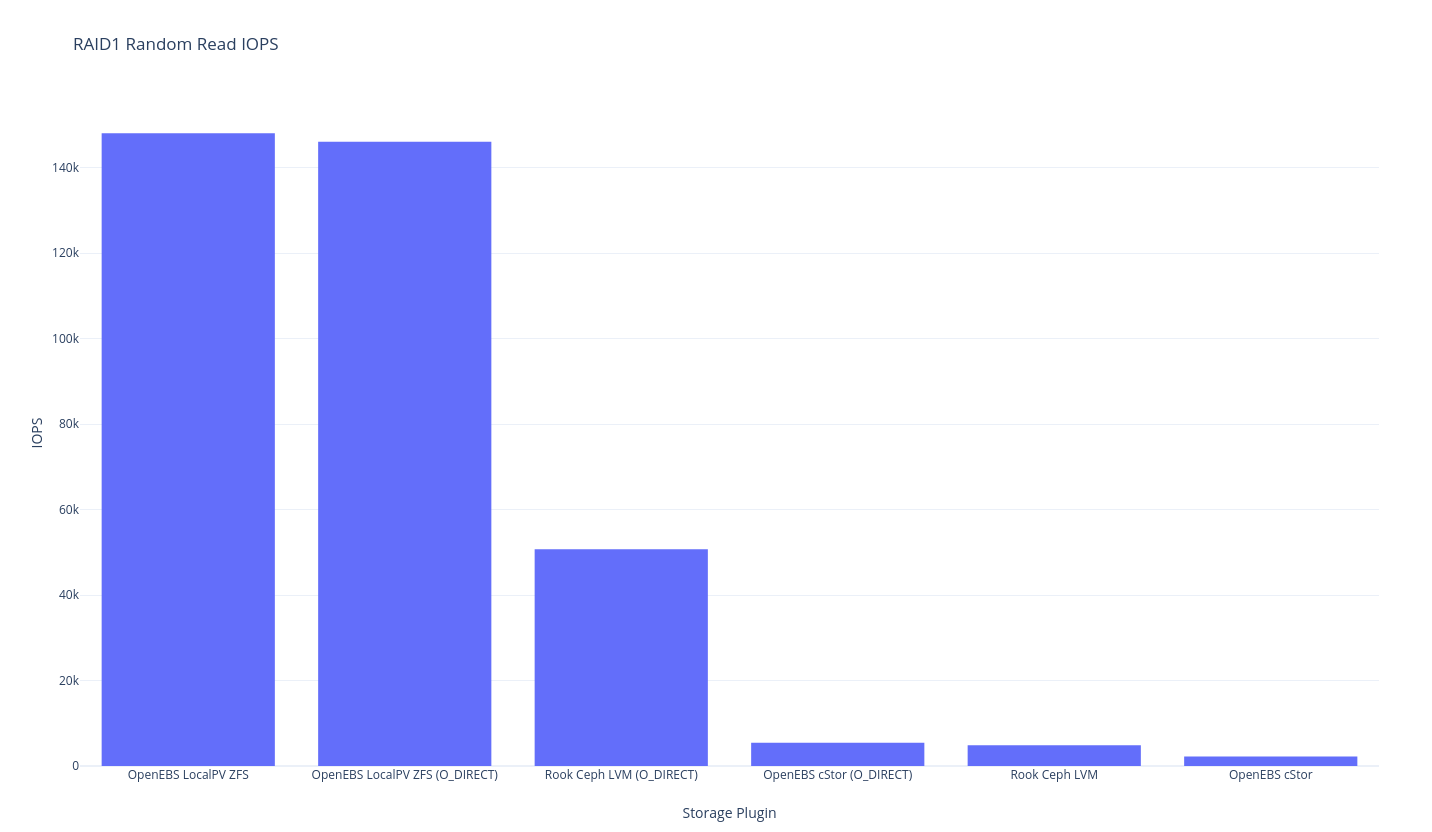
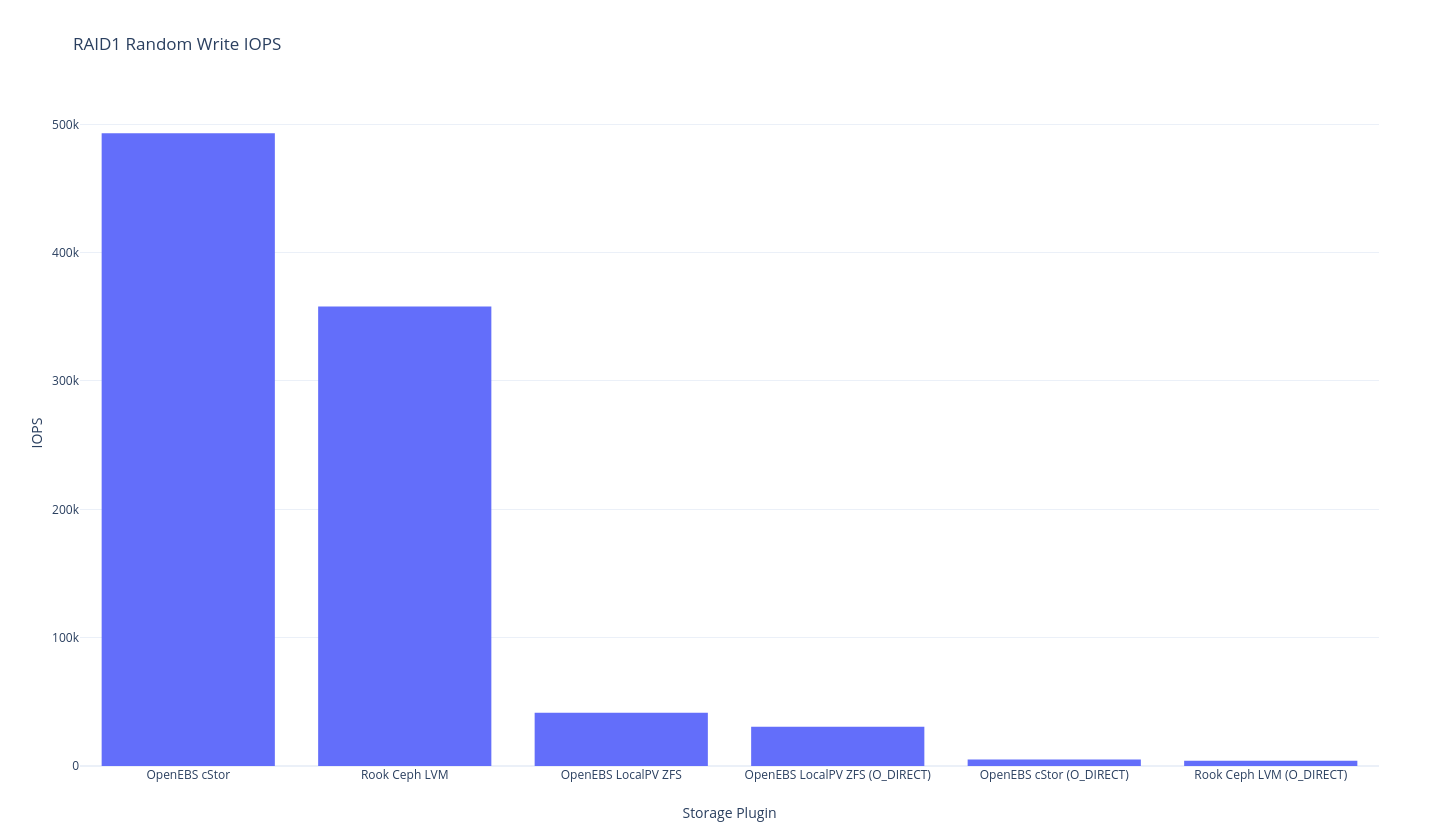
And if you’re into tabular data:
| Plugin (RAID1, 2 replicas 1 node) | RR IOPS | RR BW | RW IOPS | RW BW | Avg RL | Avg WL | SR | SW | Mixed RR IOPS | Mixed RW IOPS |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenEBS cStor | 2205 | 35.30 | 493,000 | 4039 | 1856.88 | ??? | 125 | 3422 | 920 | 303 |
OpenEBS cStor (O_DIRECT) |
5441 | 159 | 4979 | 185 | 910.12 | 983.81 | 60.90 | 167 | 3979 | 1315 |
| OpenEBS LocalPV ZFS | 148,000 | 2304 | 41,500 | 646 | 27.51 | 105 | 5098 | 629 | 46,700 | 15,600 |
OpenEBS LocalPV ZFS (O_DIRECT) |
146,000 | 2298 | 30,500 | 473 | 27.31 | 121.63 | 5239 | 634 | 46,800 | 15,600 |
| Rook Ceph LVM | 4837 | 250 | 358,000 | 3404 | 840.48 | ??? | 6978 | 2555 | 4730 | 1581 |
Rook Ceph LVM (O_DIRECT) |
50,700 | 4076 | 4132 | 370 | 206.70 | ??? | 5330 | 1124 | 2790 | 939 |
pgbench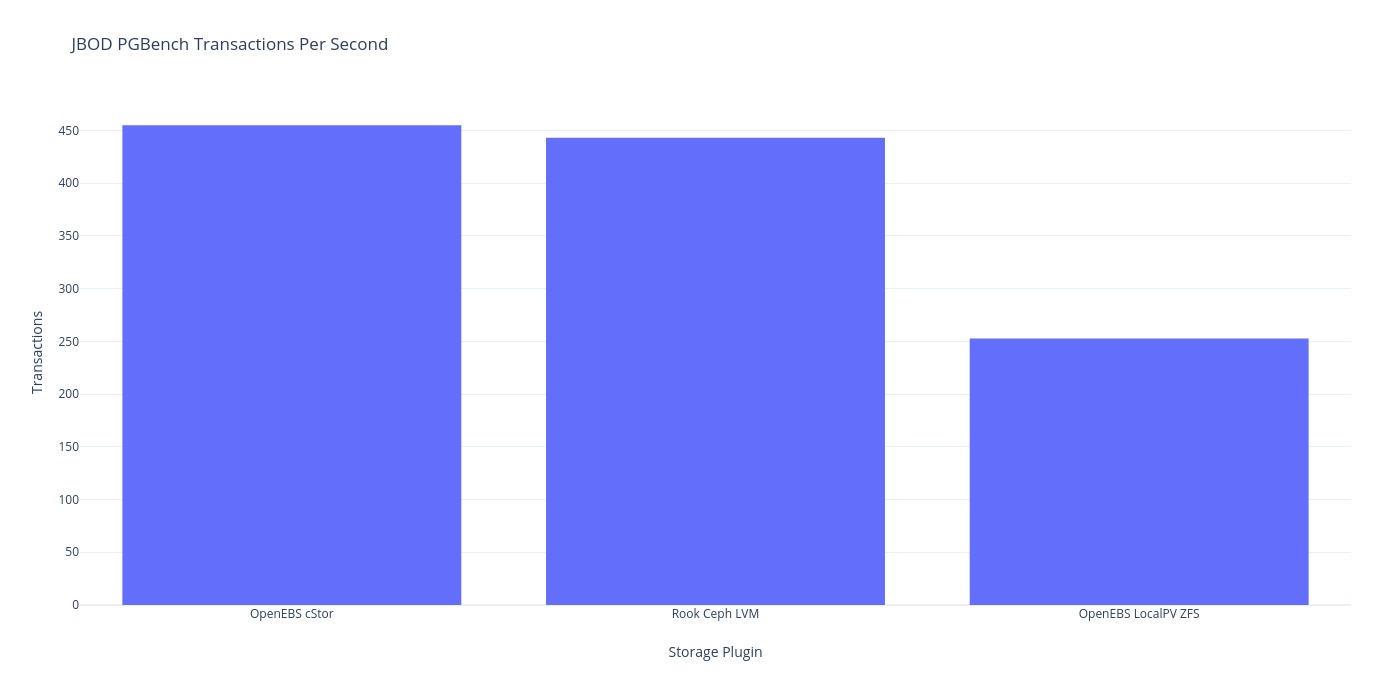
And if you’re into tabular data:
| Plugin (RAID1, 2 replicas 1 node) | # clients | # threads | transactions/client | Latency Avg (ms) | tps w/ establish |
|---|---|---|---|---|---|
| OpenEBS cStor | 1 | 1 | 10 | 2.193 | 455 |
| OpenEBS LocalPV ZFS | 1 | 1 | 10 | 3.958 | 252.65 |
| Rook Ceph LVM | 1 | 1 | 10 | 2.257 | 443.038 |
I won’t get into too much analysis just yet, but it looks like this is the difference between the speed of LVM RAID1 (at the lower level) and ZFS-based mirrored setups. It looks like ZFS performance is about 55% of the performance – which is what you might expect from having to write twice the amount of data. I wonder if LVM writes data initially as striped then does some settling later? It’s a bit curious that only ZFS has this penalty.
Note also that the ZFS (cStor is also ZFS) results might be skewed due to how ZFS writes to memory (“asynchronous write”) O_DIRECT results are probably a little better to use for eyeball comparisons.
Here are some of the thoughts that I shared with my mailing list:
A few thoughts on the single disk results and anomalies:
And a few results on the disk-level RAID1 setup:
There’s a large amount of things left to test/re-run. Getting all this automated is a good first step (so it will be easier to iterate on testing any individual one of these later), but I’ve left out the following variations, just to start:
fio block sizesfio worker thread countAll of these things could have huge impact and could change the skew of these results – its’ a huge matrix of possibilities. What I need is a framework like the one I built back during the PM2 cluster sizing experiments. I may have to reach over and use that in the future, but for now I’ll take these results as just one cubby hole in the matrix.
Repeating it here, but someone needs to make a site where you can paste a table and get a simple bar/line graph out. For these graphs I used the venerable gnuplot. Though I did see some nice options:
Looks like I’ve got a new side project to do at some point – if this was automated it would be a lot easier to run all the tests, and I could spend more time on only analysis.
There’s obviously some more to be done here – I need to try out and get some decent numbers on clustered deployments. Multi-node setups are the obvious day 2 for better disaster recovery and availability, but this analysis was only single-node.
ZFS and btrfs are really similar – there are differences, but btrfs is actually somewhat easier to manage in some ways (heterogeneous disks, etc), and while people used to often site questions of reliability, Facebook is well known to have switched to btrfs and btrfs is the default filesystem of Fedora 33. And after all, btrfs has made it into the mainline linux kernel.
In the past I have ran into some posts on ZFS’s NVMe performance that show it’s defnitely not a free lunch and some care has to be taken when using ZFS in new places (it seems like performance was bad because trying to write to ZIL/SLOG was actually causing writes to go slower because of just how fast NVMe is). While I don’t really have the problem of NVMe drives on any of the machines I run right now it’s worth keeping an eye on how the area evolves.
NVMe aside, ZFS’s performance penalty seems to be kind of high – there’s a paper out there which shows some pretty favorable numbers for BTRFS though it’s back from 2015. In general ZFS’s performance cost seems to be kinda high.
ZFS has some really important features though, in particular:
One thing you might ask is why you’d need Copy-on-Write and journaling – well ZFS has a feature called SLOG that lets you keep the Write-Ahead-Log on a completely separate drive! I may need to test ZFS with and without the ZIL in the future.
But getting back to btrfs – I’ve heard some mixed reviews over the years about btrfs, but it’s important to note that it’s in the kernel already. I found a paper with btrfs doing quite well compared to ext4 and xfs and some levelheaded helpful reviews.
Maybe it’s worth giving it a shot? Are there any provisioners for btrfs PVCs? Should I just format some local loopback mounted disks with btrfs (ex. OpenEBS rawfile LocalPV)? The easiest to start with would likely be the latter, especially for testing – loopback drives shouldn’t suffer too much of a penalty to at least make a comparison.
One thing I’ve always wanted/needed in btrfs is synchronous remote writes (kind of like ceph). There’s quite a performance hit, but being able to ensure writes are persisted on a remove drive before continuing for certain workloads would be really useful. Unfortuantely brtfs doesn’t support this either. btrfs does have some very nice features:
btrfs has better disk size flexibilitybtrfs has no downtime pool expandingbtrfs has volume shrinkingbtrfs has automatic data redistributionZFS seems to be better at raidzX but I know for most dedicated servers I’m going to have 2x some drive so I don’t think I’m too worried about RAID5/Z5.
The last thing to worry about is whether btrfs is stable. The FUD is quite persistent on this front, but there’s a whole section on it in the kernel wiki, and Facebook happens to use it. It’s also the default for OpenSUSE’s enterprise distribution so honestly it’s good enough for me.
One area of optimization that we could do on storage is considering whether we need ZIL for certain workloads on ZFS. ZFS is already copy on write, so it makes sense to disable similar features at the application level (and various scrubbing/checksumming features) if we know that we’re getting rock solid data protectionf rom ZFS. It looks like sometimes it’s actually better to have it for performance, but it’s worth considering.
Would be cool to have a simple static results page that we could throw up on GitLab pages and use to share the results. Maybe using some simple markdown-driven site generator would be a good idea/enough. If we wanted to get really fancy, we could even schedule the tests to be run every week or month. I’ll leave that for the next time I touch this project (which will probably be when I add clustered testing as well)
aio-max-nrWhile reading some stuff around the internet I took some notes on a presentation given by some people pushing the boundaries of storage setup in Japan. This slide seemed like something worth remembering, maybe even worth setting this value to something high right off the bat on nodes that are going to be storage-focused.
Looks like Ceph has some documentation on this as well
PVC-central Quality of Service limitations/features are lacking on all the baremetal hobbyist to enterprise I’ve discussed here. Generally if you want to scale to platform level service, you’re probably going to want to make sure you can avoid/limit the noisy neighbor problem. At the time of this post Kubernetes itself doesn’t even support hard-drive QOS quite yet, and there’s a KEP out.
Longhorn doesn’t support QoS (and OpenEBS Jiva since it’s based on it)
QoS features are in Oracle ZFS, but you know what they say about Oracle, not even once. OpenZFS doesn’t seem to have this feature right now so unless I’m willing to jump in and implement it (or someone else does) it’s not there for now.,
QoS is supported by Ceph but not yet supported or easily modifiable via Rook and not by ceph-csi either. It would be possible to set up some sort of admission controller or initContainers to set the information on PVCs via raw Ceph commands after creation though so I’m going to leave this as possible.
After setting up a Block you can clearly see the QOS settings:
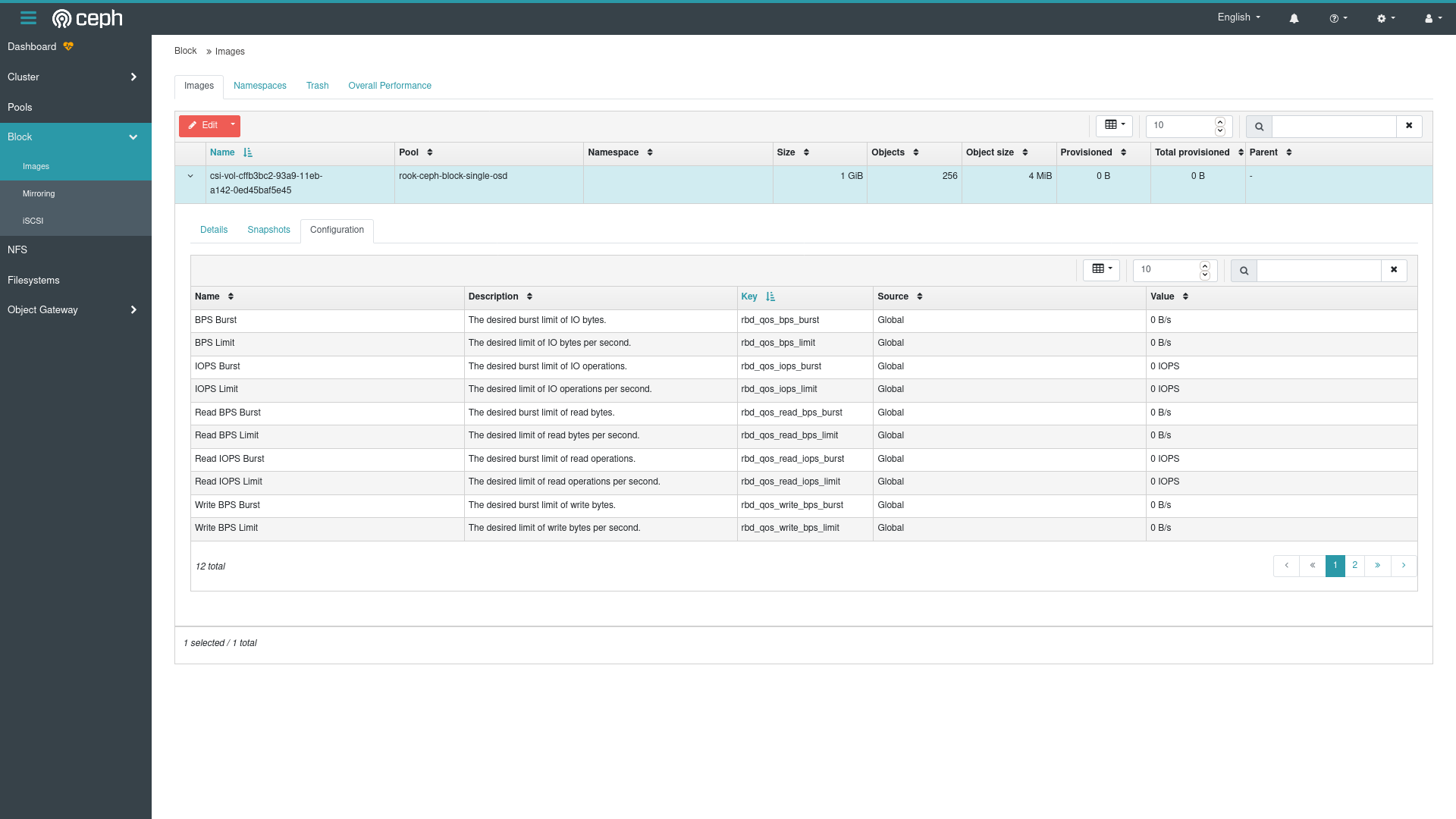
Maybe we coudl limit IOPS with containerd & v2 cgroups? We know that v1 cgroups couldn’t limit properly if you use the linux writeback cache (i.e. you weren’t using O_DIRECT which postgres doesn’t but mysql does for example), but v2 looks to have some promise – there’s an awesome blog post out there by Andre Carvalho outlining how to do it with v2 cgroups.
Even though the kernel can do it, looks like Kubernetes doesn’t have the ability just yet:
containerd (always the innovator, I remember when it was the first to get alternative non-runc container engines underneath) looks to support v2 cgroups and io limiting thanks to hard work from Akihiro Suda and others).
Limiting IOPS is a crucial feature of being able to provide storage as a service, up until now I thought the best way was to do it at the storage driver layer but it looks like the kernel subsystems might be just as good a place and might work for everything at the same time. Hopefully sometime in teh future I can get aroudn to testing this.
Read Write Many is another feature of Kubernetes storage plugins that isn’t talked about so much (since it’s not available that often) but it’s a really nice feature in my mind. A couple reasons you might want this:
Ceph is very robust software so it actually has a way to do block storage, object storage and file storage. For Ceph, CephFS is the piece of the puzzle that supports RWX drives. Since Rook is managing “our” Ceph instance, the question of whether it’s supported by Rook also comes up so there are a few issues in the rook repo about this:
It looks like CephFS has been fucntional since Rook v1.1, though there was one ticket that suggests it may have been broken intermittently between releases.
Someday I’d love to circle back and give this a try – hopefully sometime soon in the future!
Another way to achieve RWX would be to use OpenEBS’s in combination with NFS. The OpenEBS documentation details setting up RWX PVCs basedon NFS very well (also detailed on their blog back in 2018) and if you want to go straight to the code, openebs/dynamic-nfs-provisioner is the place to start.
This path seems really easy, but a blog post on it would make things crystal clear, I’m not sure if many people have taken this route.
Another good option for the RWX problem is Longhorn – as I’ve mentioned this is what OpenEBS Jiva is based on, and it’s worth mentioning that the ease with which you can set up OpenEBS Jiva is definitely attributable in part to Longhorn’s hard work. I personally have interacted with their team and they’re very capable (obviously, longhorn works so well it was extended), and gracious as well, even when I was lodging what might be seen as a complaint.
Originally I missed this point, and for that I have to thank /u/joshimoo on reddit who pointed it out two salient points:
At this point we have enough of these solutions that support RWX, it looks like next time I’m going to need to add longhorn to the stable of solutions, and start running tests on RWX as well, as soon as I find out how you’re supposed to test it in the first place (somehow fio doesn’t seem like the right choice). According to an SO post it looks like I can just check the NFS wiki for decent testing tools, and dbench (I used this last time I did some benchmarking)or bonnie might be good bets. Maybe I’ll be the first one to get some proper NFS vs CephFS performance comparisons. Even dd and iozone seem to be fine for benchmarking NFS so maybe I don’t need to think about it too hard.
The question of whether to use NFS with some not-ceph solution and CephFS is a big one. I’ve only been able to find one resource that seems to compare the two:
But even this is more about running samba on top of them, which is a bit different from a knock-down drag-out benchmark.
The numbers I’ve gotten aren’t all that good. They’re pretty good in seeing some trends, but pretty bad in other ways, some of the various biases of certain providers are leaking through, and making it somewhat hard to get a good read. As I get more time to go over the benchmarks (or get some nice contributions) I think I’ll work on them more and may revisit, but for now I’m making the following determination:
Given a system with more than one NVMe disk, I’m going to install both OpenEBS Mayastor and Ceph, and use them both, with the bigger empty disk going to Ceph and the smaller partition going to OpenEBS Mayastor.
There are a few reasons I’ve arrived at this decision:
I really want to have ZFS underneath/as a part of my system (and maybe I still can by running LocalPV ZFS on top of mayastor or something), and have it’s amazing data safety, but the drastic drop in write speed (which you can see in the TPS reductions) and the addition of overhead when I can get some pretty decent availability improvements from the other two solutions just makes it a non-starter. We’ll see if I live to regret this decision, because if NVMe is 2x faster than SSD, then maybe it makes sense to use ZFS and go back to ~SSD performance with the benefit of essentially absolute data confidence and a really easy to configure/use system.
Well this started as one blog post and turned into a 5 part series! It’s been grueling but fun yak shave and hopefully a worthwile post to put together (along with the development on the back end though).
I’m glad I finally got some time to do some proper testing of these solutions and hopefully the analysis will help others out there. If this article ends up being anywhere as useful as the CNI benchmark posts have been, I’ll be more than thrilled.