DDG search drop in powered by ddg.patdryburgh.com
I've gotten some great feedback from a post in r/kubernetes and another post in r/zfs. I've added a section with some thoughts
tl;dr - I recently switched my baremetal cluster storage setup to OpenEBS ZFS LocalPV + Longhorn. Some issues with Longhorn not running on PVCs aside, the setup is flexible perf wise (ZFS LocalPV) and I at least have a low-complexity option for distributed/HA storage (Longhorn).
I recently spent some time working my way to my most flexible storage setup yet, and along the way I spent some time exploring whether Longhorn – a simple and easy to use storage provider for Kubernetes – could be run on PVCs rather than hostPath/local disk. I ran into a few issues with Longhorn (it doesn’t really work on PVCs right now) but a little pre-provisioned storage isn’t the end of the world. The rest of the setup is pretty nice so I thought I’d share a bit about it.
Up until now I’ve happily run and lightly managed Rook (in-cluster managed Ceph) on all my nodes. This worked great except for the fact that performance just didn’t scale. It’s to be expected of networked synchronous writes (the best writeup I’ve seen of the perf tradeoff is here), but I was happy with the tradeoff until I wasn’t. I started also having problems with Rook not making the amount of OSDs (attempting to boost the throughput on NVMes led me to try that) so I started looking elsewhere.
If we zoom out a bit I’ve tried a quite a few k8s storage options over the years (I’ve done some benchmarking):
hostPath (old reliable)local volumeshostPath)I’ve used OpenEBS in the past and am very happy with their offerings. OpenEBS Jiva was one the first storage providers I used and I was really happy with how simple it was to set up (in comparison to Rook/Ceph).
Since what I wanted here was performance, I gave them another look since they’ve got some better-than-local options in the local disk space. OpenEBS has a lot of offerings so let’s break it apart a bit.
On the networked drive side (likely highly available, low perf):
uzfs based)
On the local drive (high perf, not highly available)
mdadm RAID that Hetzner mahcines come with doesn’t offer checksumming (that Ceph and some other tech would give me)zfs checksumming, tooling, etcSo lots of options, it’s a veritable Smörgåsbord! Let’s take some time to think through it.
Of course before I can figure out the best solution, I need to figure out what I actually need/want. Of course as a world class yak-shaver not all of these things are strict requirements, but no one writes home about storage setups that are not resilient right? Anyway here’s a Maslow-esque hierarchy of needs (most important first):
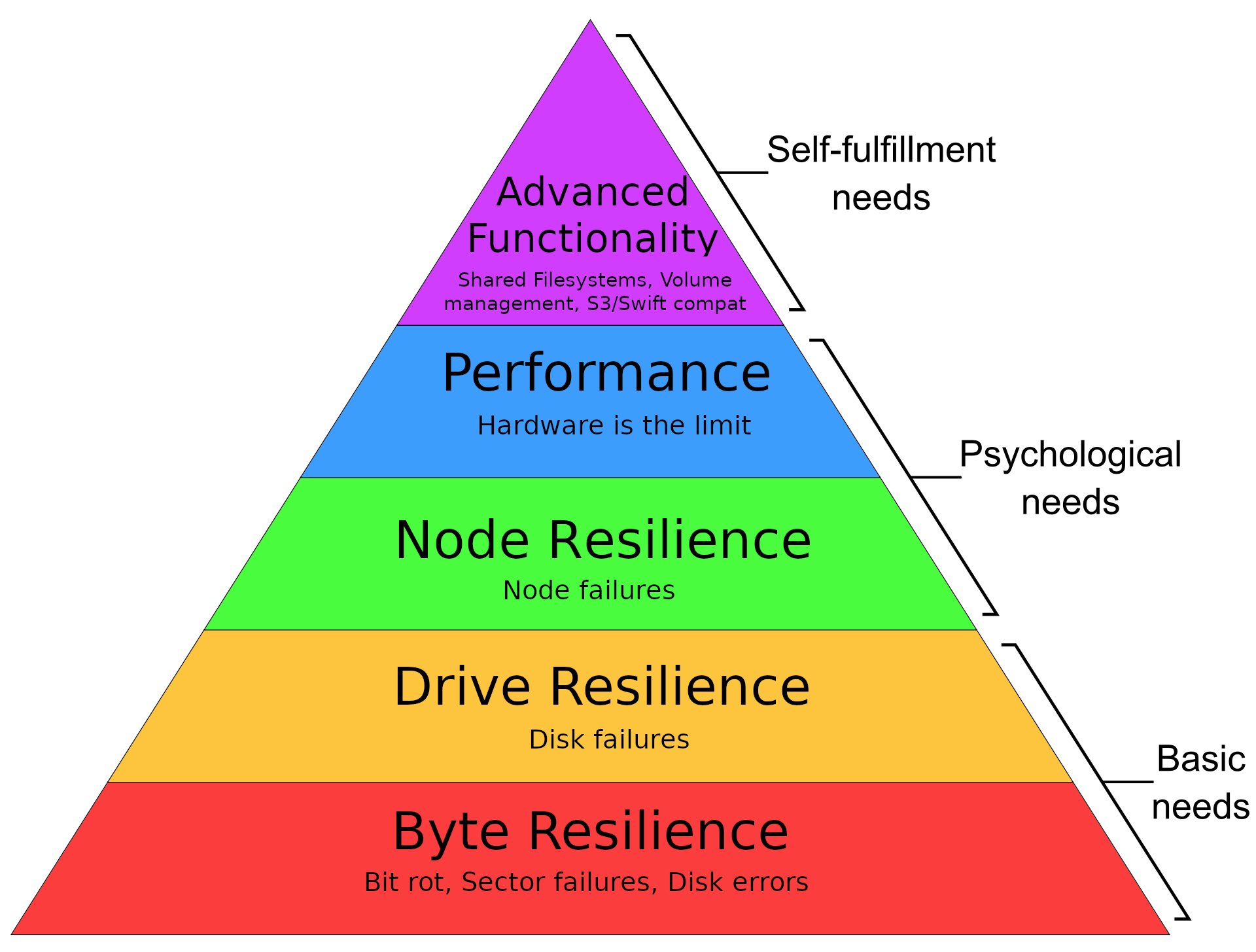
In textual form:
Block or a FileSystem)Up until I was happy with my setup, in particular the following:
I loved the following about this setup:
All-in-all the setup works pretty well, but the whole reason this post is here is that there are some issues:
I realized that running everything I want to run on Ceph (particularly databases or other high write workloads) was simply a non-starter with the hardware I have/am willing to purchase and setup. If I had access to a some crazy SAN or even just wanted to buy 10 drives and do lots of striping to try and boost the IOPS an dbandwidth sure, but I’m not willing to do that. Up until now I hadn’t really given performance enough thought – I run a ~5 databases and a bunch of other storage-enabled workloads and they’re doing just fine but I figure if I’m going to solve this earlier rather than later is better.
While thinking about my options in this space I started coming back to an interesting combination – OpenEBS ZFS LocalPV + Longhorn/Ceph. Let’s break down the choices individually:
A few reasons why ZFS LocalPV is a good fit:
zfs recv and zfs send are also awesome – extremely efficient snapshotsStorageClass), so experimentation is easyA few reasons on why Longhorn is a good choice for me, generally in comparison to Rook/Ceph:
Overally this choice is a bit sketchy but I’m pretty happy with the tradeoff because of how much more complicated Ceph is. If I ever get really annoyed with Longhorn I can always switch it out with Rook/Ceph or even LINSTOR down the road and feed ZVOLs or Block volumes, so for now I’m going with simplicity till I need something more.
OK, let’s get back to that hierarchy, what makes this setup actually good?
Block or a FileSystem
zfs send/zfs recv, I can efficiently take backups of any data set at any time, or even the whole machine if I wantProper cloud providers have a bunch of things that make them much more performant than the setup I’m whipping – they’ve got access to Hardware Storage Area Network (SANs) that they can run in one data center and have their disks in one place and their servers (with fiber connections) in another. Adding drives and using striping with appropriate RAID5/RAIDZ and other solutions gives them the ability to scale vertically much easier without sacrificing data integrity by just adding more disks, and without losing much speed network wise (with most data center traffic being essentially local and very fast).
I do know that that some providers run Ceph but I’d love some input from people in the space on just exactly how much heavy lifting custom SANs are doing relative to the software layer. Even just hardware RAID can offer a perf boost that I can’t go for.
In the end getting this setup up and running at a high level means:
mdadm RAID on the OS partition (Hetzner drives have mdadm RAID1 by default)To make this concrete, if a machine I have comes with 2 512GB NVMe disks my automation sets up:
mdadm RAID partitions for the OS (across both disks), swap, etc
zfs pool that is mirrored (across both disk) in the remaining space
tank/longhorn ext4 ZVOLOn top of that, at the k8s-and-above-level I set up:
tank/longhorn ZVOLSince I saw (but never tried) PVC support for Rook, I hoped Longhorn might have something similar but unfortuantely it didn’t. I ran into a few issues but at the end of the day Longhorn’s simplicity is still mostly unmatched and I’m very grateful to the Rancher team for releasing this awesome software for people to use for free.
Since I run k0s, I needed to set a non-standard kubelet directory on the driver deployer:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: longhorn-driver-deployer
namespace: longhorn
spec:
replicas: 1
selector:
matchLabels:
app: longhorn-driver-deployer
template:
metadata:
labels:
app: longhorn-driver-deployer
spec:
serviceAccountName: longhorn
securityContext:
runAsUser: 0
initContainers:
- name: wait-longhorn-manager
image: longhornio/longhorn-manager:v1.2.0
command: ['sh', '-c', 'while [ $(curl -m 1 -s -o /dev/null -w "%{http_code}" http://longhorn-manager:9500/v1) != "200" ]; do echo waiting; sleep 2; done']
containers:
- name: longhorn-driver-deployer
image: longhornio/longhorn-manager:v1.2.0
imagePullPolicy: IfNotPresent
command:
- longhorn-manager
- -d
- deploy-driver
- --manager-image
- longhornio/longhorn-manager:v1.2.0
- --manager-url
- http://longhorn-manager:9500/v1
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
# Manually set root directory for csi
- name: KUBELET_ROOT_DIR
value: /var/lib/k0s/kubelet
# ... the rest is elided ...
A small change but super important for those who run k0s or k3s or other similar projects.
volumeClaimTemplates by converting from Daemonset -> StatefulSetBy default the all-in-one Longhorn resource file (ex. https://raw.githubusercontent.com/longhorn/longhorn/v1.2.0/deploy/longhorn.yaml) you’re going to get a DaemonSet piece called the longhorn-manager. This sits on every node and negotiates storage for the various PersistentVolumeClaims that are created. Weirdly enough Kubernetes only supports volumeClaimTemplates for StatefulSets, so if I wanted a truly PVC driven setup, I needed to change longhorn-manager to a StatefulSet. There are two suboptimal things this forces:
replicas to match the number of nodes I want the manager to run on (with the appropriate selectors, etc)This is what it ended up looking like:
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: longhorn-manager
namespace: longhorn
labels:
app: longhorn-manager
spec:
serviceName: longhorn-manager
selector:
matchLabels:
app: longhorn-manager
template:
metadata:
labels:
app: longhorn-manager
spec:
serviceAccountName: longhorn
# Ensure the pods are scheduled only on nodes with the 'storage.zfs' label
nodeSelector:
storage.zfs: "true"
storage.longhorn: "true"
# Ensure no longhorn pods ever end on the same node
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- longhorn-manager
containers:
- name: longhorn-manager
image: longhornio/longhorn-manager:v1.2.0
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
command:
- longhorn-manager
- -d
- daemon
- --service-account
- longhorn
- --engine-image
- longhornio/longhorn-engine:v1.2.0
- --instance-manager-image
- longhornio/longhorn-instance-manager:v1_20210731
- --share-manager-image
- longhornio/longhorn-share-manager:v1_20210820
- --backing-image-manager-image
- longhornio/backing-image-manager:v2_20210820
- --manager-image
- longhornio/longhorn-manager:v1.2.0
ports:
- containerPort: 9500
name: manager
readinessProbe:
tcpSocket:
port: 9500
env:
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# Should be: mount path of the volume longhorn-default-setting + the key of the configmap
# data in 04-default-setting.yaml
- name: DEFAULT_SETTING_PATH
value: /var/lib/longhorn-config/default.yaml
volumeMounts:
- name: dev
mountPath: /host/dev/
- name: proc
mountPath: /host/proc/
- name: longhorn
subPath: longhorn
mountPath: /var/lib/longhorn/
mountPropagation: Bidirectional
- name: longhorn-config
mountPath: /var/lib/longhorn-config/
volumes:
- name: dev
hostPath:
path: /dev/
- name: proc
hostPath:
path: /proc/
- name: longhorn-config
configMap:
name: longhorn
There are a few bits missing becasue I use kustomize to do my templating – so in my overlays/<cluster name> folder I have a strategic patch merge that looks like this:
#
# Longhorn Manager has been converted to a StatefulSet that behaves like a DaemonSet
# for the following reasons:
# - volumeClaimTemplates to generate local PVCs to use
# - anti-affinity should ensure separate nodes
#
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: longhorn-manager
namespace: longhorn
labels:
app: longhorn-manager
spec:
# The replicas have to set to # of nodes manually
replicas: 2
volumeClaimTemplates:
- metadata:
name: longhorn
spec:
storageClassName: localpv-zfs-ext4
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 128Gi
This was good enough to get me off the ground with regards to getting longhorn-manager running on PVCs rather than hostPath.
longhorn-manager runningThis is just a bit of how Longhorn works – it turns out the longhorn PVCs won’t get created on nodes where longhorn-manager isn’t running. Unfortunately I didn’t record the exact error to put here, but I fixed this with nodeSelectors on the appropriate workloads to restrict to nodes where storage.longhorn=true.
hostPath state for other workloadsWhile the longhorn-manager was running, the UI was usable, and the drives actually got Bound, I ran into an issue that sunk the ship (and forced the solution I ultimately went with). It turns out ancillary longhorn containers use hostPath and do things with the shared paths that other pieces depend on. In particular, this manifests itself as binaries being missing. Here’s an excerpt from longhorn-manager (I believe?):
E1009 06:19:11.773255 1 engine_controller.go:695] failed to update status for engine pvc-9f71b456-3106-4074-9a2d-a2eace2220f6-e-de46fc92: failed to list replicas from controller 'pvc-9f71b456-3106-4074-9a2d-a2eace2220f6': Failed to execute: /var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.0/longhorn [--url 10.244.136.201:10000 ls], output , stderr, , error fork/exec /var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.0/longhorn: no such file or directory
E1009 06:19:16.773298 1 engine_controller.go:695] failed to update status for engine pvc-9f71b456-3106-4074-9a2d-a2eace2220f6-e-de46fc92: failed to list replicas from controller 'pvc-9f71b456-3106-4074-9a2d-a2eace2220f6': Failed to execute: /var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.0/longhorn [--url 10.244.136.201:10000 ls], output , stderr, , error fork/exec /var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.0/longhorn: no such file or directory
While debugging this I went to check the position on disk:
$ k exec -it longhorn-manager-0 -- /bin/bash
root@longhorn-manager-0:/# ls /var/lib/longhorn
root@longhorn-manager-0:/# ls /var/lib/longhorn
longhorn/ longhorn-config/
I definitely didn’t expect the folder to be completely empty. I started doing some reading on [bidirectional mount propagation], which turned out to not be the problem (but is an interesting requirement). After some head scratching I started theorizing that the ancillary workloads (pods triggerred by longhorn-manager and friends) were actually doing the binary downloading. That said, it was possible that I was overwriting some binaries that were supposed to be in the longhorn-manager container so I ran it locally:
$ docker run --rm -it --entrypoint=/bin/bash longhornio/longhorn-manager:v1.2.0
Unable to find image 'longhornio/longhorn-manager:v1.2.0' locally
v1.2.0: Pulling from longhornio/longhorn-manager
35807b77a593: Pull complete
c1ffcd782017: Pull complete
abb38587df9f: Pull complete
Digest: sha256:75aac5ee182c97d136a782e30f753debcf3c79d3c10d8177869c2e38cadc48ff
Status: Downloaded newer image for longhornio/longhorn-manager:v1.2.0
root@eab01ec907ac:/# ls /var/lib/
apt dpkg misc nfs pam python systemd ucf vim
root@eab01ec907ac:/# ls /var/lib/longhorn
ls: cannot access '/var/lib/longhorn': No such file or directory
root@eab01ec907ac:/# exit
Well that leaves only the theory about the ancillary containers downloading the binaries – and a quick check of the contents of the resources was enough to validate my assumptions:
apiVersion: v1
kind: Pod
metadata:
annotations:
cni.projectcalico.org/podIP: 10.244.121.38/32
cni.projectcalico.org/podIPs: 10.244.121.38/32
kubernetes.io/psp: 00-k0s-privileged
creationTimestamp: "2021-10-09T05:36:27Z"
generateName: engine-image-ei-0f7c4304-
labels:
controller-revision-hash: dc7b8949b
longhorn.io/component: engine-image
longhorn.io/engine-image: ei-0f7c4304
pod-template-generation: "1"
name: engine-image-ei-0f7c4304-2plb8
namespace: longhorn
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: DaemonSet
name: engine-image-ei-0f7c4304
uid: 455b1328-7be3-4d82-9245-6bbc4c6e47df
resourceVersion: "91981962"
uid: 934672b6-d18b-4080-8d7b-80b87d362400
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- node-5.eu-central-1
containers:
- args:
- -c
- diff /usr/local/bin/longhorn /data/longhorn > /dev/null 2>&1; if [ $? -ne 0
]; then cp -p /usr/local/bin/longhorn /data/ && echo installed; fi && trap 'rm
/data/longhorn* && echo cleaned up' EXIT && sleep infinity
command:
- /bin/bash
image: longhornio/longhorn-engine:v1.2.0
imagePullPolicy: IfNotPresent
name: engine-image-ei-0f7c4304
readinessProbe:
exec:
command:
- sh
- -c
- ls /data/longhorn && /data/longhorn version --client-only
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 4
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /data/
name: data
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-64sdt
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: node-5.eu-central-1
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: longhorn
serviceAccountName: longhorn
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/disk-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/memory-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/pid-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/unschedulable
operator: Exists
volumes:
- hostPath:
path: /var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v1.2.0
type: ""
name: data
- name: kube-api-access-64sdt
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
Once I checked on a one of the longhorn nodes I saw that the disks (which are the root OS disks!) had the files that were being searched for:
root@node-3 ~ # ls /var/lib/longhorn/
engine-binaries longhorn-disk.cfg replicas
At this point I thought I had only two choices:
hostPath storage for ancillary workloads(1) is the easier solution and (2) seems like the “right” solution (though PVC support in Rook was somewhat late as well), so I took some time and asked the Longhorn team. Turns out it’s possible but pretty hard, so (1) is the far easier option, and what I went with after all.
So to go with that, I had to revert back to the DaemonSet (which felt better conceptually anyway) and use a hostPath that is backed by a mounted ZVOL.
So I happened to do a few fio runs (thanks to the excellent dbench which I’ve made some changes to) on both ZFS (during some separate storage experimentation I haven’t written up) and Longhorn, so here are some results to look at (unfortunately in textual form):
fio is kind of annoying – In the future I’m likely going to have to stop using libaio since it makes for some really annoying/inconsistent results. I might also start working in some more tools like I did in the past – pgbench, sysbench or even dd. Right now I’ve got a few nice little Job that I carry around and use with fio so it’s very convenient.
Anyway, in general we can at least talk about the scales on which the different runs are – generally:
Hostpath has some great high level numbers for random reads/writes:
Random Read/Write IOPS: 271k/238k. BW: 1101MiB/s / 964MiB/s
Random Read/Write IOPS: 18.6k/460k. BW: 3472MiB/s / 3740MiB/s
ZFS (RAID1) on top of that has drastically worse performance:
Random Read/Write IOPS: 8198/123. BW: 1101MiB/s / 14.1MiB/s
Random Read/Write IOPS: 8797/2084. BW: 1285MiB/s / 279MiB/s
And Longhorn (psync) numbers are the worst of all (as we’d expect):
Random Read/Write IOPS: 1966/21.0k. BW: 80.1MiB/s / 81.7MiB/s
Random Read/Write IOPS: 2012/1347. BW: 83.1MiB/s / 43.2MiB/s
fio for your perusalhostPath on NVMe (RAID0)Generally expected to be the highest possible performance, hostPath folders on a given node that has the relevant storage attached. If you care about this kind of thing, the storage driver is libaio and I’ve toggled O_DIRECT on fio. This is the theoretical limit
libaio)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 18.6k/460k. BW: 3472MiB/s / 3740MiB/s
Average Latency (usec) Read/Write: 273.36/
Sequential Read/Write: 9558MiB/s / 3147MiB/s
Mixed Random Read/Write IOPS: 13.3k/4445
libaio, O_DIRECT)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 271k/238k. BW: 1101MiB/s / 964MiB/s
Average Latency (usec) Read/Write: 71.94/17.67
Sequential Read/Write: 3219MiB/s / 813MiB/s
Mixed Random Read/Write IOPS: 131k/43.6k
lz4) on NVMelibaio)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 8797/2084. BW: 1285MiB/s / 279MiB/s
Average Latency (usec) Read/Write: 451.10/3505.75
Sequential Read/Write: 8025MiB/s / 850MiB/s
Mixed Random Read/Write IOPS: 1686/569
libaio, O_DIRECT)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 8198/123. BW: 1101MiB/s / 14.1MiB/s
Average Latency (usec) Read/Write: 512.16/39762.44
Sequential Read/Write: 6743MiB/s / 92.6MiB/s
Mixed Random Read/Write IOPS: 324/105
When running these tests I used my custom version to vary the IO engine – the numbers from psync look a lot more consistent/represenative of what you’d expect.
libaio, FIO_DIRECT=0)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 1941/485k. BW: 80.9MiB/s / 4112MiB/s
Average Latency (usec) Read/Write: 2108.66/
Sequential Read/Write: 746MiB/s / 2509MiB/s
Mixed Random Read/Write IOPS: 30/10
psync, FIO_DIRECT=0)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 1966/21.0k. BW: 80.1MiB/s / 81.7MiB/s
Average Latency (usec) Read/Write: 509651.19/1584.78
Sequential Read/Write: 729MiB/s / 185MiB/s
Mixed Random Read/Write IOPS: 1922/623
libaio, FIO_DIRECT=1)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 25.1k/13.7k. BW: 203MiB/s / 93.8MiB/s
Average Latency (usec) Read/Write: 470.69/771.32
Sequential Read/Write: 202MiB/s / 98.9MiB/s
Mixed Random Read/Write IOPS: 15.7k/5237
psync, FIO_DIRECT=1)==================
= Dbench Summary =
==================
Random Read/Write IOPS: 2012/1347. BW: 83.1MiB/s / 43.2MiB/s
Average Latency (usec) Read/Write: 489.59/739.91
Sequential Read/Write: 200MiB/s / 61.7MiB/s
Mixed Random Read/Write IOPS: 1314/441
After getting some fantastic feedback from reddit:
I got to doing some investigation on whether LVM was actually a better choice than ZFS for the underlying layer with the better write performance others were seeing. In the end the benchmarking wasn’t completely successful because benchmarking ZFS is hard due to it’s reliance (and expected use of) in-memory caching (ex. the ARC subsystem). I won’t recount all the details here, but the difficulty of benchmarking storage systems has taken another victim – I do have these takewaways though:
openebs/lvm-localpv) is seemingly around 2-5x faster on the write path than ZFS, but requires bit more fiddling (dm-integrity) to get bitrot/checksum data protection.blocksize needs to be tuned, as every guide will probably tell you (I didn’t believe this because I erroneously believe it was “just an upper bound”, so I left it at 128k)In the end I’m going with ZFS for my cluster rather than LVM despite the write perf difference, for a few reasons:
dm-integrity on just a partition (looks like full disks are required, which isn’t unreasonable, I guess, but is hard to do on Hetzner)zfs send/zfs recv) of ZFSZFS writes are slower in comparison but considering AWS provisioned IOPS for postgres are $.10/IOPS-month and 1000 IOPS (the lowest pre-provisioned amount you can get on RDS) would be $100, that’s already 2x what a whole ~6k IOPS hetzner server costs, so if I ever need to facilitate crazy IOPS demands I’ll just scale out and revisit the storage decision. Having faster reads that writes is also a pretty common database usecase so I think I’m happy with it.
In the future I’ll probably try and assemble all the guidance I’ve seen around Postgres + ZFS, so look out for that.
Well this was a fun exercise in combining solutions, and at the end of the day I have a setup I’m pretty happy with – allowing workloads with relatively small storage demands to float around, and with the option for storage-performance-critical workloads (which usually handle their own replication, like Postgres) to use closer to raw speed storage.
Hopefully this saves some people some time out there in deciding what to do with their storage setups. The vast majority of people are probably very happy with their local cloud provider storage provisioner but for those running on bare metal or looking for something different, this information might be useful.